В современном мире растущей автоматизации и внедрения искусственного интеллекта важную роль играет способность технологий быть понятными и прозрачными для конечных пользователей. Объяснимый искусственный интеллект (Explainable AI, XAI) направлен на создание моделей, которые не только обеспечивают точные предсказания, но и предоставляют интерпретации своих решений в доступной для человека форме. Одним из перспективных методов в этой области является использование правил — логических конструкций, которые достаточно естественно воспринимаются людьми. Однако универсальные, «один для всех» объяснения порой оказываются недостаточно эффективными: разные пользователи обладают разным уровнем знаний, опытом и предпочтениями, что влияет на восприятие и полезность предоставляемых объяснений. Здесь на помощь приходит персонализация объяснений на основе правил с учётом пользовательских предпочтений, позволяющая адаптировать объяснения к индивидуальному профилю пользователя.
Сегодня существует множество XAI-методов, однако значительная часть из них ориентирована на формирование одинаковых объяснений вне зависимости от пользователя и контекста. Практика показывает, что такая унификация часто снижает эффективность восприятия: пользователи сталкиваются с излишне сложными, неинтуитивными или слишком общими объяснениями. Уровень профессиональной подготовки, цели использования модели и даже психологические особенности влияют на предпочтения и требования. Например, врачам нужна более детальная и техническая информация, тогда как пациенты предпочитают объяснения в более простом и обобщённом виде. Для решения данной задачи разработан инновационный подход, лежащий в основе системы CoRIfEE-Pref — одной из реализаций фреймворка CoRIfEE, направленного на генерацию объяснений, учитывающих когнитивные предпочтения пользователей.
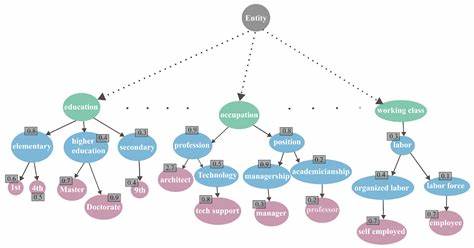
Основополагающая идея заключается в моделировании пользовательских знаний и предпочтений через весовые функции, применяемые к узлам специального графа знаний, связующего термины и концепты доменной области. Граф знаний представляет собой ориентированный ацикличный граф, где вершинами являются атрибуты, значения атрибутов и абстрактные концепты (например, более общие категории), а рёбрами — отношения «категоризирован как» или другие семантические связи. Каждому пользователю соответствует уникальная весовая функция, которая навешивает числовые коэффициенты на соответствующие концепты в графе. Эти веса отражают степень знакомости, важности или предпочтения пользователя к тому или иному понятию. Для врача, например, вес могут иметь термины медицинской специфики или конкретные числовые показатели, а для непрофессионала предпочтение будет отдаваться более общим, понятным категориям.
В основе метода лежит принцип распознавательного эвристического подхода: пользователь предпочитает объяснения, состоящие из знакомых и признаваемых им понятий. Поэтому качественное объяснение — это не только точное с точки зрения модели, но и максимально соответствующее фоновой экспертизе пользователя. Процесс создания персонализированного объяснения начинается с получения множества правил из разных интерпретируемых моделей машинного обучения, например, из деревьев решений или правил индукции. Этот многообразный пул моделей отражает известный эффект «Рашомона», когда несколько моделей одинаково хорошо объясняют данные, но используют различные подмножества признаков и логических построений. Далее условия правил группируются на основе их семантической близости в графе знаний.
Это обеспечивает формирование кластеров, где объединяются связанные по смыслу параметры, что способствует получению более когерентных и логичных объяснений. Затем внутри каждого кластера происходит генерация кандидатов на объяснения — правил с одной или несколькими связанными по смыслу условиями, которые отвечают минимальным требованиям по охвату и точности. Эти промежуточные объяснения проходят проверку на адекватность, и если соответствуют установленным порогам, они переходят к этапу объединения — межкластерной генерации новых, более комплексных правил. Объединённые правила оцениваются с учётом двух ключевых факторов: традиционного эвристического показателя качества (например, m-оценки, сочетающей охват и точность) и пользовательской функции предпочтений, основанной на весах из графа знаний. Пороговое значение интегрированной метрики определяет, какие правила отдавать в финальное объяснение.
Благодаря такому подходу конечный набор правил максимально адаптирован под запросы и уровень знаний конкретного пользователя. Для оценки качества полученных персонализированных объяснений используется семантическая метрика, учитывающая близость понятий в графе знаний (например, метрика Leacock & Chodorow) и веса пользователя. Это позволяет количественно определить, насколько сгенерированное объяснение соответствует ожиданиям и особенностям целевой аудитории. Эксперименты, проведённые на различных наборах данных, таких как медицинская диагностика, банковский маркетинг, качество воды и доходы населения, продемонстрировали, что подход CoRIfEE-Pref успешно генерирует объяснения, которые статистически значимо более соответствуют профилю пользователя. Это достигается без существенной потери точности модели, что подчеркивает эффективность персонализации.
Особая важность применения данного метода проявляется при взаимодействии с критически зависимыми от понимания объяснений дисциплинами, такими как медицина или финансы. Здесь неперсонализированные объяснения могут привести к неправильному восприятию, снижению доверия к системе или неверным управленческим решениям. Применение весовых функций, основанных на знании и опыте пользователя, позволяет более эффективно доносить смысл и суть алгоритмических решений. Кроме того, методика обеспечивает динамическую адаптацию гранулярности объяснений — их степени детализации и абстракции. Это критически важно, поскольку слишком развернутые и технические пояснения могут перегрузить непрофессионала, а излишне простые — не удовлетворить добросовестного эксперта.
Управляя уровнем абстракции с помощью весов в графе знаний, можно балансировать между детализацией и обобщением. Важным преимуществом представленого подхода является использование формализованных графов знаний, что обеспечивает глубокую интеграцию доменной онтологии в процесс генерации объяснений. Это позволяет применять метод в самых разных предметных областях, просто адаптируя или создавая соответствующий граф. Несмотря на очевидные достоинства, метод имеет некоторые ограничения. В частности, необходимость задания весовых функций требует либо непосредственного участия пользователей либо высокого качества эвристического моделирования их предпочтений.
В текущих исследованиях предпочтения пользователей имитируются с помощью современных языковых моделей, таких как ChatGPT, что обеспечивает масштабируемость, но не всегда отражает реальное восприятие живых людей. Будущие работы нацелены на проведение полноценных пользовательских исследований и интеграцию обратной связи для улучшения адаптации. Также стоит отметить потенциальные риски чрезмерной персонализации — например, сокрытие важных деталей или подкрепление уже существующих когнитивных искаженностей. Следует внимательно изучать эти аспекты, особенно в областях с высокими этическими и социальными требованиями. В целом, подход, направленный на формирование персонализированных объяснений на основе правил с учётом пользовательских предпочтений, представляет собой значительный шаг к созданию человеко-центричных искусственных интеллектов.
Он способствует улучшению понимания, повышению доверия и эффективности взаимодействия между людьми и сложными моделями, что крайне важно на пути к широкому и безопасному внедрению AI-технологий в повседневную жизнь и профессиональную практику.