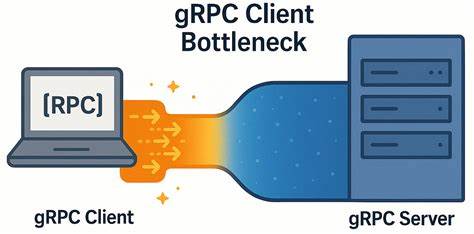
gRPC давно зарекомендовал себя как мощный инструмент для межсервисного взаимодействия и высокопроизводительных систем. Однако, несмотря на его широкое применение и репутацию надёжной платформы, в низкозадержных сетях неожиданно возникают трудности, выявляющие скрытые ограничения на стороне клиента. Такой узкое место способно серьёзно ограничивать масштабируемость и эффективность взаимодействия, что особенно критично в системах с высокими требованиями к скорости отклика и пропускной способности. gRPC реализован поверх протокола HTTP/2, что позволяет использовать множественные параллельные потоки внутри одного TCP-соединения. На первый взгляд, это должно обеспечивать максимально эффективное использование сетевых ресурсов и минимизировать накладные расходы.
Однако практика и эксперименты с нагрузочными тестами, например, произведённые в рамках разработки YDB — распределённой СУБД с поддержкой ACID-транзакций, выявили важный нюанс. Когда нагрузка распределяется по небольшому количеству узлов или когда количество клиентов сокращается, ожидаемое улучшение производительности не происходит. Более того, при уменьшении кластера наблюдаются простаивающие серверные ресурсы вместе с ростом задержек на стороне клиента. Причина кроется в том, что даже несмотря на использование нескольких gRPC-каналов, они могут необязательно создавать отдельные TCP-соединения. gRPC по умолчанию использует один и тот же TCP-сокет для нескольких каналов с одинаковыми аргументами, мультиплексируя запросы через HTTP/2.
Это приводит к тому, что количество одновременно активных потоков ограничено внутренним лимитом HTTP/2 по максимальному числу concurrent streams, который по умолчанию часто равен 100. Данный эффект обостряется в сценариях с большим количеством коротких запросов, где общее время ожидания на стороне клиента начинает расти из-за очередей на создание новых RPC. В таких условиях реальное улучшение пропускной способности становится невозможным, так как новые вызовы просто не могут быть отправлены, пока существующие не завершатся. В итоге, даже при минимальной нагрузке, задержки на клиенте превышают сетевые задержки, что указывает на внутренние непроизводительные задержки именно в клиентской реализации. Для анализа была создана простая микробенчмарочная система ping на основе последних версий gRPC (v1.
72.0) с асинхронным сервером и синхронным клиентом, работающим по принципу закрытого цикла. Сервер и клиент запускались на выделенных физических машинах с мощными процессорами и сетевым соединением 50 Гбит/с, что позволяет исключить влияние загруженности оборудования или сети на результаты. Результаты подтвердили, что при использовании одного соединения с разными каналами и росте количества параллельных запросов увеличение RPS (запросов в секунду) происходит не линейно, а значительно хуже, а задержки растут непропорционально. Подробный разбор сетевого трафика с помощью tcpdump и Wireshark выявил отсутствие сетевых проблем, таких как потеря пакетов, задержки TCP или накопление данных в буферах.
Несмотря на быструю обработку сервером и конфигурацию TCP с отключённым алгоритмом Нэйгла (TCP_NODELAY), между посылками пакетов от клиента наблюдались промежутки 150–200 микросекунд без активности. Этот так называемый idle time указывает на задержки, генерируемые клиентской стороной, возможно, вызванные внутренними очередями или синхронизацией. Эксперименты с созданием каналов с различными аргументами, что заставляет gRPC открыть отдельное TCP-соединение на каждый канал, показали резкое улучшение показателей. Использование параметра GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL на клиенте позволило добиться ещё более высокого пропускания и сниженного времени отклика. Это доказывает, что мультиплексирование запросов внутри одного соединения, хотя и оптимально с точки зрения использования сетевых ресурсов, приводит к узкому месту в системе и снижает общую производительность.
Интересно отметить, что в сетях с высокой задержкой (например, порядка 5 мс RTT) данный эффект практически не проявляется. Высокие сетевые задержки доминируют и маскируют внутренние задержки клиента gRPC, что объясняет, почему проблема остаётся незамеченной во многих реальных сценариях широкого применения gRPC, где сети обычно имеют значительные задержки. Для практиков, работающих с gRPC в системах с низкой сетевой задержкой, это означает важный урок: не стоит считать, что один канал на один клиент или даже несколько каналов с одинаковыми параметрами позволят достичь оптимальной производительности. Следует создавать отдельные каналы с уникальными аргументами для каждого рабоче-клиентского потока, чтобы наладить эффективное распределение запросов по нескольким TCP-соединениям. Такой подход помогает избежать накопления и очередей в рамках ограничений HTTP/2 и одновременно повышает параллелизм обработки запросов.
Кроме того, важно соблюдать рекомендации по закреплению потоков и распределению нагрузки на уровне CPU, например, используя taskset или аналогичные средства, чтобы избежать накладок на планирование потоков и обеспечить устойчивую работу на NUMA-системах. Понимание и правильное использование таких тонкостей могут существенно улучшить производительность сервисов, снижающих энергозатраты и уменьшающих задержки. В целом, выявленное узкое место клиента gRPC является наглядной демонстрацией того, что улучшение масштабируемости систем с низкими задержками требует комплексного подхода, учитывающего не только параметры сервера и сети, но и внутренние архитектурные особенности транспортного протокола и клиентов. Современные распределённые системы, стремясь к миллисекундной или микросекундной задержке, должны обращать внимание на подобные детали и тестировать свои решения в условиях, максимально приближённых к реальной нагрузке и инфраструктуре. Разработчики и архитекторы могут использовать предложенные в исследовании методы и настройки для диагностики и устранения клиентских узких мест.
Оптимизация не только повысит производительность и отзывчивость приложений, но и сделает инфраструктуру более предсказуемой и управляемой при росте нагрузки. Таким образом, очевидно, что поддержка и развитие сложных коммуникационных платформ, таких как gRPC, требует постоянного мониторинга, глубокого анализа и адаптации решений к конкретным условиям эксплуатации. Только так возможно раскрыть потенциал современных распределённых баз данных и сервисов и обеспечить качество обслуживания, необходимое в высоконагруженных и чувствительных к задержкам системах.