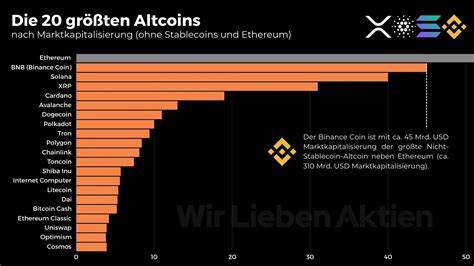
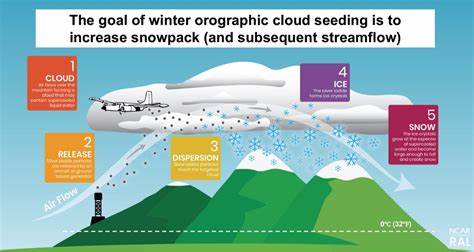
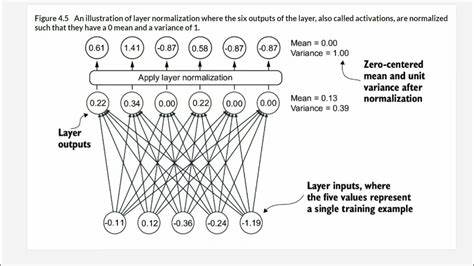
В области машинного обучения модели, работающие с последовательными данными, занимают особое место. Они лежат в основе обработки естественного языка, аудио, видео и многих других типов данных. На сегодняшний день наиболее популярными являются трансформеры, особенно после успеха архитектуры «Attention Is All You Need» и масштабирования больших языковых моделей. В то же время растет интерес к State Space Models (SSM) — современным рекуррентным моделям с расширенным состоянием, которые предлагают уникальные перспективы в обработке длинных последовательностей. В этой статье мы подробно рассмотрим основные характеристики, преимущества и ограничения SSM и трансформеров, чтобы лучше понять, в чем состоят их ключевые компромиссы и как эти два подхода дополняют друг друга.
State Space Models — что это и почему они важны SSM представляют собой класс моделей, которые формализуют обработку последовательностей через обновление скрытого состояния на каждом временном шаге. Основная идея — использовать расширенное скрытое состояние, значительно больше размера входного элемента, чтобы эффективно хранить релевантный контекст за всю историю последовательности. В отличие от классических RNN, SSM обладают структурой с параметрическими матрицами переходов, которые могут варьироваться во времени и зависеть от входных данных. Эта «селективность» позволяет им более гибко запоминать и обновлять информацию, что критично для работы со сложными последовательностями, например, в языковом моделировании. Одним из прорывов в этой области стала архитектура Mamba, которая объединяет большой скрытый размер, выразительные динамики обновления состояния и тщательно продуманные методы тренировки с использованием параллельных вычислений.
Благодаря этому удалось получить производительность на уровне трансформеров при меньших вычислительных ресурсах и лучшей масштабируемости на длинных последовательностях. Отличие SSM от трансформеров заключается в способе, которым модели хранят и используют информацию. SSM сжимают весь контекст в фиксированное по размеру скрытое состояние, обновляя его последовательно с каждым новым входом. Это можно сравнить с «рабочей памятью мозга», которая активно обрабатывает и обобщает всю поступающую информацию без необходимости хранить каждый отдельный элемент данных. Трансформеры и их уникальный подход к обработке последовательностей Трансформеры кардинально отличаются по архитектуре, используя механизм самовнимания (self-attention), который рассматривает каждый элемент последовательности в контексте всех остальных.
Благодаря этому модели могут эффективно захватывать долгосрочные зависимости и уделять внимание конкретным позициям входа, обладающим наибольшей значимостью для предсказания. Их основная сила — возможность точного запоминания и манипуляции отдельными элементами контекста. Однако у этого подхода есть и ограничения. Функция внимания требует вычисления взаимодействий между всеми парами токенов, что приводит к квадратичной сложности по длине последовательности. Это создает значительные препятствия при работе с очень длинными или высокочастотными данными, особенно без корректирующих механизмов или приближений.
Кроме того, трансформеры требуют предварительной обработки данных на достаточно абстрактном уровне — обычно это токенизация в языковом моделировании, которая группирует слова или подсловные куски в единицы для эффективной обработки. Такая обработка улучшает качество модели, но вводит сложности, связанные с потерей информации и «грубостью» представления для определенных данных. Компромиссы между SSM и трансформерами Основной компромисс между этими двумя классами моделей связан с балансом между эффективностью и выразительностью. SSM предлагают линейный по времени проход с постоянным объемом памяти, что позволяет масштабировать обработку к очень длинным последовательностям и высоким скоростям данных. Тем не менее, за счет сжатия контекста в скрытом состоянии они теряют способность к точному запоминанию отдельных элементов, что ограничивает подробную работу с отдельными входами.
Трансформеры, наоборот, обеспечивают «идеальный» уровень детализации, запоминая и обращаясь к каждому токену в контексте, что превосходно для задач, где необходима точная семантическая обработка. Но квадратичная сложность лежит в основе ограничений на длину контекста и скорость работы. Интересно отметить, что в некоторых случаях трансформеры работают плохо без соответствующего уровня предварительной обработки и токенизации, особенно когда данные представлены в очень высоком разрешении, например, на уровне символов или букв. В таких случаях SSM зачастую показывают лучшие результаты, поскольку их компрессия состояния помогает извлекать более высокоуровневые закономерности из «сырых» данных. Как токенизация влияет на модели Токенизация — это процесс разбиения текста на более крупные, часто семантически значимые блоки, которые проще обрабатывать.
Она значительно сокращает длину входных последовательностей и облегчает работу трансформеров. Однако она далеко не идеальна: токенизация вызывает множество известных проблем и ограничений, включая неспособность эффективно работать с определенными языками или с сильно зашумленными данными. Удаление необходимости в токенизации находится в центре исследований современных моделей, и именно здесь преимущество SSM проявляется особо ярко. Поскольку SSM способны работать непосредственно с исходными символами или базовыми единицами, они сохраняют гибкость обработки и способны учиться извлекать сложные представления без явных операций препроцессинга. В исследованиях показано, что при моделировании данных на уровне байтов или символов SSM по-прежнему превосходят трансформеры по эффективности и качеству, даже когда трансформеры используют больше вычислительной мощности.
Это неудивительно, учитывая, что токенизация создает для трансформеров «жесткие» рамки и заставляет их фокусироваться на отдельном токене, который не всегда является оптимальной единицей информации. Применение гибридных моделей Для максимизации преимуществ обеих подходов сегодня активно разрабатываются гибриды, сочетающие слои SSM и трансформеров. Такой подход позволяет моделям использовать эффективную компрессию состояния и онлайн-обработку на ранних этапах, а затем применять точное внимание там, где требуется точечная работа с отдельными элементами контекста. Оптимальное сочетание таких слоев варьируется, но исследования и эксперименты показали, что наилучшие результаты достигаются при соотношении примерно от 3:1 до 10:1 в пользу слоев SSM. Эти гибридные модели продемонстрировали впечатляющую производительность в больших языковых моделях, мультимодальных задачах и других сферах, подтверждая идею о том, что компромисс между парциальной компрессией и полной детализацией может быть эффективно сбалансирован.
Будущее и перспективы развития Несмотря на выдающиеся успехи трансформеров, их архитектура далеко не совершенна и не единственно возможна. SSM и связанная с ними новая волна рекуррентных моделей, таких как Mamba и ее производные, показывают альтернативный путь развития с упором на эффективность, масштабируемость и естественную компрессию информации. Со временем ожидается появление все более совершенных архитектур, которые не только решат проблему квадратичной сложности трансформеров, но и предложат более глубокую семантическую и структурную обработку данных без необходимости сложной токенизации. Сочетание идей, заложенных в SSM, с преимуществами внимания и гибридными подходами — это, вероятно, следующий шаг в развитии моделей для обработки последовательностей. Кроме того, исследование вопросов, связанных с повышением устойчивости к шуму, масштабированием и обучением непосредственно на «сырых» данных, может привести к новым прорывам в области понимания естественного языка, биоинформатики, аудио- и видеорядах.
Заключение Торговля между State Space Models и трансформерами сводится к дилемме между эффективностью и точностью воспоминаний. SSM предлагают компактное, сжатое представление контекста с преимуществом линейной обработки и меньших требований к памяти, что делает их незаменимыми для задач с длинными или высокочастотными входами. Трансформеры же сохраняют превосходство в задачах, требующих детального и точного внимания к каждому токену, но страдают от квадратичных вычислительных затрат и зависимости от предварительной обработки данных. Современные исследования и практика показывают, что не стоит рассматривать одно из решений как универсальное. Вместо этого гибридные модели и дальнейшее понимание компромиссов позволят создавать более гибкие, масштабируемые и мощные архитектуры.
С учетом быстрого роста интереса к SSM и методам без токенизации, будущее области обещает быть богатым на инновации и неожиданные открытия.