В мире разработки больших языковых моделей (LLM) существует множество компонентов, которые на первый взгляд могут показаться слишком простыми или механическими, но именно они играют решающую роль в успешном обучении сети и получении качественных результатов. Одним из таких компонентов является слой нормализации. Несмотря на то, что его объяснение кажется достаточно техническим, его понимание поможет лучше осознать фундаментальные принципы стабилизации обучения и оптимизации моделей с многослойной архитектурой. Большие языковые модели работают в несколько этапов. Изначально текст разбивается на токены, которые затем преобразуются в токен-эмбеддинги вместе с позиционными эмбеддингами.
Эти векторы служат входными данными для слоя многоголового внимания (Multi-Head Attention), который с учетом контекста формирует так называемые контекстные векторы — они описывают значение каждого токена с учетом информации от предыдущих токенов. Далее эти контекстные векторы проходят через несколько таких слоев внимания, каждый из которых обрабатывает данные на более высоком уровне абстракции, позволяя модели «понимать» контекст более глубоко. Наконец, полученные векторы, ориентирующиеся в пространстве эмбеддингов в сторону наиболее вероятного следующего токена, проецируются в пространство словаря, что позволяет получить оценки вероятности для каждой возможной следующей лексемы. Хотя такая последовательность вычислений кажется завершенной и логичной, реальное обучение LLM требует дополнительных манипуляций с данными, поступающими на каждом этапе. Одним из ключевых элементов этих манипуляций является слой нормализации, позволяющий контролировать статистические свойства данных и предотвращать типичные проблемы, возникающие при обучении глубинных нейронных сетей.
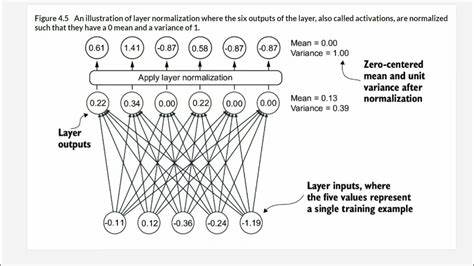
Суть нормализации заключается в перераспределении значений внутренних векторов так, чтобы их среднее значение равнялось нулю, а дисперсия (вариативность) — единице. Проще говоря, каждый контекстный вектор при проходе через слой нормализации преобразуется так, чтобы иметь одинаковое «среднее» и «разброс» значений по своим компонентам. Такой подход напоминает выравнивание уровня аналогового сигнала в аудиооборудовании, где устраняется постоянный сдвиг и выравнивается громкость для стабильного качества звучания и более качественного микширования. Почему же это важно? Во время обучения с использованием алгоритма градиентного спуска параметры модели корректируются в направлении уменьшения ошибки прогноза. Градиенты ошибки распространяются назад по сети, корректируя веса на каждом уровне.
Одной из проблем при обучении глубоких моделей является явление затухающего или взрывающегося градиента. Если значение градиента убывает к младшим слоям, то эти слои не получают достаточной информации для корректировки, и обучение сильно замедляется или останавливается. В противоположном случае — при взрывающемся градиенте — корректировки становятся слишком резкими, что приводит к нестабильности и ухудшению результатов. Слой нормализации служит своего рода стабилизатором, поддерживая уровни активаций в оптимальных пределах и обеспечивая, чтобы передаваемая обратная ошибка имела разумный масштаб на всех этапах. Нормализация включает два ключевых этапа: вычитание среднего значения и деление на стандартное отклонение (корень квадратный из дисперсии).
Вычитание среднего уровня устраняет смещение (аналогично удалению DC-баса в аудио), а масштабирование с помощью стандартного отклонения нормирует разброс значений, делая распределение данных однородным. Важно, что используется именно стандартное отклонение, а не дисперсия. Это связано с тем, что дисперсия измеряется в квадрате единиц исходных данных, а стандартное отклонение — в тех же единицах, что и исходные данные, что делает масштабирование корректным и сохраняющим смысловую структуру. Однако возникает вопрос: не изменится ли при этом смысл embedding-векторов, ведь направление вектора отражает его смысловое значение, а нарушение направления может привести к потере информации? Важным открытием является то, что именно такой нормализованный вывод передается между слоями, и обучение всей модели происходит с учетом этих преобразований. Это значит, что сами веса и матрицы преобразований внутри слоев тренируются так, чтобы давать смысловые векторы уже с учетом нормализации на выходе.
Таким образом, слой нормализации не разрушает смысловые связи, а лишь стандартизирует представления для устойчивого обучения. После нормализации вводятся параметры масштаба и смещения — обучаемые векторы, которые масштабируют и сдвигают нормализованные данные. Это дает модели гибкость – она может сама решать, насколько сильно отклоняться от нейтрального нормализованного состояния. Такой подход позволяет модели находить оптимальные статистические свойства для внутренних представлений, если собой рассмотреть крайне упрощенную аналогию из аудио — это как эквалайзер, который позволяет усилить или ослабить определенные частотные диапазоны для улучшения звучания, но уже применительно к измерениям в эмбеддинг-пространстве. Слой нормализации в современной архитектуре LLM — это не просто метод предобработки данных.
Это важнейший инструмент, выражающий баланс и контроль над потоками информации, обеспечивающий эффективное взаимодействие между слоями модели. Без него обучение было бы либо нестабильным, либо затрудненным из-за проблем с градиентами. Стоит отметить, что существуют различные варианты нормализации в глубоких сетях. Для LLM чаще всего применяют слой нормализации (Layer Normalization), который нормализует по измерениям эмбеддинга для каждого отдельного токена, в отличие от батч-нормализации (Batch Normalization), распространяемой на весь пакет данных. Такой подход лучше подходит для задач с последовательной обработкой и обеспечивает большую стабильность на этапах обучения при небольших размерах пакетов.