В современном мире обработки и анализа данных организации всё чаще сталкиваются с необходимостью правильной и эффективной организации сложных процессов обработки информации. Современные технологии требуют выполнения различных трансформаций данных, объединённых в сложные структуры, которые программно должны быть определёнными, оптимальными и поддерживаемыми. Именно здесь ключевую роль играют направленные ацикличные графы, или DAG (Directed Acyclic Graphs), которые обеспечивают чёткую последовательность и зависимости трансформаций внутри процесса. Apache Hamilton — это инновационная Python-библиотека, которая предлагает удобный способ создания, управления и визуализации таких DAG-трансформаций, объединяя в себе простоту, портативность и расширяемость. Она особенно полезна для специалистов в области данных, инженеров и разработчиков, стремящихся повысить качество и масштабируемость своих дата-воркфлоу.
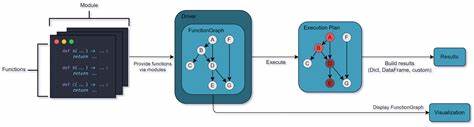
Apache Hamilton — легковесная библиотека, предназначенная для построения DAG, описывающих зависимости между функциями трансформаций данных. В отличие от классических оркестраторов, цель Hamilton — помочь пользователям сосредоточиться на чистом определении логики трансформаций, отделяя её от инфраструктурных и эксплуатационных аспектов. Этот подход способствует лучшей модульности, повторному использованию кода и поддерживаемости проектов. Основным принципом Apache Hamilton является возможность описания DAG с помощью обычных Python-функций, где зависимости моделируются через параметры функций. Такой подход обеспечивает наглядность и естественность определения последовательностей обработки данных в привычной среде Python без необходимости изучать специализированные языки или DSL (Domain Specific Languages).
Более того, Hamilton автоматически анализирует описания функций и строит DAG, что приводит к уменьшению ручного труда и повышению надёжности кода. Одним из важнейших достоинств Apache Hamilton является его портативность. Построенные DAG можно запускать в разных средах и инфраструктурах без изменений — будь то локальный скрипт, интерактивный ноутбук, веб-сервер на FastAPI или планировщик задач вроде Apache Airflow. Такая независимость помогает организациям интегрировать библиотеку в существующие пайплайны и процессы без дополнительных затрат на адаптацию. Кроме того, библиотека предоставляет множество механизмов, позволяющих управлять выполнением DAG, среди которых можно выделить изменение конфигурации для разных сред, встроенную валидацию данных и схем, мониторинг и отслеживание результатов трансформаций.
Эти возможности позволяют повысить качество и надёжность рабочих процессов с данными, а также упрощают отладку и сопровождение. Особое внимание заслуживает возможность интеграции с Apache Hamilton UI — пользовательским интерфейсом, который обеспечивает визуализацию DAG, каталогизацию данных и мониторинг исполнения пайплайнов. Такая функциональность значительно облегчает командную работу, повышает прозрачность бизнес-процессов и улучшает взаимодействие между специалистами разных направлений — от дата-сайентистов до инженеров-разработчиков и аналитиков. Применение Apache Hamilton охватывает широкий спектр задач, включая построение ETL процессов, создание рабочих потоков для машинного обучения, управление обработкой данных для LLM и систем с Retrieval-Augmented Generation (RAG), а также разработку BI-дашбордов. Эта библиотека позволяет ставить задачу построения DAG на более высоком уровне абстракции, что повсеместно упрощает поддержку и развитие аналитических решений.
Благодаря принципу отделения определения DAG от его выполнения Apache Hamilton позволяет повысить эффективность взаимодействия между командами. Дата-сайентисты могут сосредоточиться на описании трансформаций без необходимости «ломать голову» над эксплуатационными аспектами, тогда как инженеры берут на себя задачу управления запуском и мониторингом рабочих процессов. Это снижает барьеры во взаимодействии и позволяет быстрее приходить к рабочим результатам. Важным аспектом использования Apache Hamilton является его поддержка стандартов кодирования и тестируемости. Определение каждой трансформации через отдельную функцию стимулирует написание модульного, читаемого и самодокументируемого кода.
Также реализованы декораторы и адаптеры для валидации качества данных, что помогает выявлять ошибки на ранних этапах обработки. Библиотека активно развивается на базе сообщества, сформировавшегося вокруг этого проекта. Поддержка многочисленных интеграций и расширений позволяет адаптировать Hamilton под запросы различных корпоративных инфраструктур и рабочих процессов. Благодаря открытости исходного кода и возможности вносить взаимодействия с другими технологиями, проект стремительно набирает популярность среди профессионалов в области данных. Преимущество библиотеки в том, что она работает на Python версии 3.
8 и выше, что делает её доступной для широкого круга пользователей и современного ПО. Для визуализации DAG необходимо установить дополнительный пакет с визуализацией, а также систему Graphviz, которая отвечает за отображение графов. Наличие встроенного SDK и UI-компонента существенно расширяет возможности мониторинга и управления, особенно в командных и производственных условиях. Создатели Apache Hamilton подчёркивают, что библиотека не является инструментом оркестровки, таким как Airflow, но дополняет их, фокусируясь на структурировании и описании самих преобразований данных. Если сравнивать с более традиционными инструментами, то Hamilton для Python — это как dbt для SQL: он позволяет организовать процесс описания трансформаций с помощью ясного, модульного кода и управлять им на уровне разработки и тестирования.
Большинству современных дата-команд важно обеспечить непрерывность процессов от разработки до релиза в продакшен. Apache Hamilton способствует выстраиванию такого конвейера благодаря простым и понятным механизмам конфигурации, которые избавляют от использования путаных if/else конструкций и feature-флагов. Это делает поддержку проектов менее ресурсоёмкой и более надёжной. Среди крупных пользователей можно выделить известные компании и государственные организации, которые успешно внедрили Apache Hamilton в свои бизнес-процессы. Такие кейсы доказывают способность библиотеки справляться с массовыми и критичными задачами, включая обработку временных рядов, конвейеры машинного обучения и сложные ETL процессы.
Для разработчиков и дата-специалистов существует возможность легко начать работу с библиотекой, так как она имеет продуманную документацию, большое количество примеров, обучающих материалов и активное сообщество в Slack и на других платформах. Это позволяет новичкам быстро включаться в процесс и использовать все преимущества Apache Hamilton уже на первых шагах создания проектов. Библиотека также демонстрирует гибкость благодаря архитектуре, ориентированной на плагины, что позволяет расширять возможности стандартных функций и интегрироваться в любые корпоративные стеки и технологические решения. Таким образом, Apache Hamilton можно считать универсальным инструментом современного дата-инжиниринга на Python. В заключение стоит отметить, что Apache Hamilton — это не просто инструмент, а целая экосистема для управления DAG трансформациями, объединяющая лучшие практики из мира разработки, data engineering и анализа данных.
Использование этой библиотеки помогает создавать более прозрачные, управляемые и совместные процессы обработки данных, что важно для современных организаций, стремящихся к качеству и инновациям. Если ваша команда ищет средство для упрощения построения, поддержки и мониторинга сложных потоков трансформаций данных, Apache Hamilton представляет собой мощное решение, которое стоит изучить и внедрить. Благодаря своей портативности, выразительности и поддержке лучших практик разработки эта библиотека имеет все шансы стать вашим ключевым инструментом в сфере работы с данными.