PostgreSQL является одной из самых популярных систем управления базами данных, широко используемой благодаря своей надежности, функциональности и гибкости. Важной частью эффективной работы с PostgreSQL становится умение читать и интерпретировать планы выполнения запросов - отчеты, которые показывают, как СУБД планирует и выполняет SQL-запросы. Понимание этих планов критично для оптимизации запросов и улучшения производительности приложений. В условиях, когда каждая миллисекунда задержки влияет на пользовательский опыт, грамотный разбор планов выполнения способен обеспечить прирост в скорости работы базы данных от десяти до сотен раз. Планы помогают понять, какие именно индексы используются, насколько эффективно устроены операции соединения таблиц и как выполняются сортировки данных.
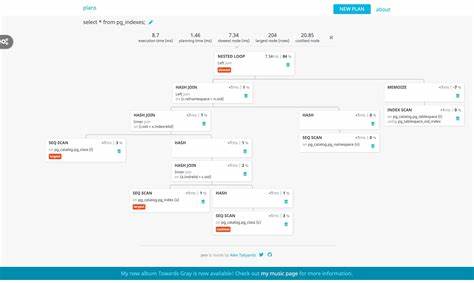
Чтобы начать работу с планами, в PostgreSQL существует команда EXPLAIN, которая показывает прогнозируемый план выполнения запроса. Она не запускает сам запрос, а лишь строит модель. Для получения более детальной информации, включая фактическое время выполнения и количество обработанных строк, применяется EXPLAIN ANALYZE. Эта команда фактически запускает запрос и измеряет его работу, что позволяет выявить расхождения между оценками и реальными показателями. Использовать EXPLAIN (ANALYZE, BUFFERS, VERBOSE, FORMAT JSON) - значит получить максимально подробную информацию, включая статистику обращения к кешу и диску, что полезно для комплексной диагностики.
Важным этапом в понимании планов является выделение основных сигналов, на которые стоит обращать внимание. Типы сканов играют ключевую роль: последовательный Scan (Seq Scan) подразумевает полное чтение таблицы и может считаться нормальным для совсем маленьких таблиц. Однако на больших объёмах данных такой способ приводит к серьёзным задержкам. Индексные сканирования (Index Scan, Index Only Scan) направлены на поиск целевых данных и могут значительно снизить количество прочитанных страниц. Комбинация в виде Bitmap Index Scan и Bitmap Heap Scan применима, когда выборка средней или большой, но всё равно требует оптимального управления чтением.
Наблюдение за расхождением между прогнозируемым и фактическим количеством обработанных строк помогает определить, насколько актуальны статистические данные. Если разница велика, скорее всего, необходимо обновить статистику методом ANALYZE и подумать о создании выраженных или частичных индексов, учитывающих часто уточняемые условия фильтрации. Также имеет смысл анализировать время выполнения и использование буферов, чтобы понять распределение операций по кешу и физическому вводу-выводу. Понимание структуры узлов плана также крайне важно. Например, Nested Loop эффективен, если внешний набор данных мал и внутренний индексирован, но при больших объемах без индексов он становится узким горлышком.
Хеш-джойны (Hash Join) хорошо работают на средних и больших выборках, создавая хеш на меньшем входном наборе и используя его для быстрого поиска. Сортировки и агрегации могут вызвать большие задержки, если не покрыты подходящими индексами, например, композитными, которые удовлетворяют и условию WHERE, и ORDER BY. Для лучшего понимания можно рассмотреть практические примеры. В одном из кейсов при выборке последних заказов по клиенту с сортировкой по дате создания наблюдался полный последовательный скан таблицы с последующей сортировкой. Это приводило к большим задержкам, поскольку СУБД читала миллионы строк и выполняла сортировку на уровне плана.
Создание композитного индекса, покрывающего и фильтрацию по клиенту, и порядок сортировки, позволило избежать полного сканирования и сортировки, что дало существенный выигрыш в производительности и отклик в миллисекундах. Другой пример связан с неправильным выбором типа джойна. При поиске событий последнего месяца для пользователей определенной организации PostgreSQL выбрал Nested Loop с внутренним последовательным сканом на таблице событий. При большом количестве пользователей и отсутствии индекса по полям user_id и created_at такой запрос превращался в экологическую катастрофу, перебирая слишком много строк. Рекомендуемое решение включало создание частичного или композитного индекса по этим полям с учетом фильтрации по типу события и времени, а также изменение параметров конфигурации для побуждения планировщика к использованию Hash Join, который лучше масштабируется.
Современные практики рекомендуют использовать искусственный интеллект в связке с EXPLAIN. Планы редко бывают короткими, они сложны и содержат много технического шума. Автоматизированный анализ с помощью ИИ помогает переводить планы на понятный язык, выделять критичные узлы и предлагать точечные рекомендации по улучшению. Помимо этого, в рамках процессов CI/CD удобно хранить базовые планы в формате JSON для сравнения новых версий запросов - так разработчики оперативно получают предупреждения о регрессиях или ухудшении плана. Скрипты с использованием psql и jq позволяют быстро выявлять изменения ключевых полей, а ИИ комментирует и рекомендует шаги исправления.
Не менее важен правильный подход к статистике и сбору данных. Регулярный запуск ANALYZE для поддержания актуальности статистики - залог правильного планирования. Кроме того, повышая уровень сбора статистики по определенным колонкам и создавая частичные индексы на участках с высокой концентрацией запросов, можно уменьшить негативное влияние скинов данных и повысить точность оценок планировщика. Особенности работы с параметрами конфигурации, такими как enable_nestloop, enable_seqscan и work_mem, позволяют в диагностических целях тестировать альтернативные планы, но не должны оставаться в рабочих системах постоянно. При подготовке к выпуску важно проверить, что планы для критичных запросов не содержат последовательных сканов там, где доступны индексы, что крупные джойны используют подходящие типы соединений и что сортировки обеспечены индексами.
Работа с CI Guardrails и мониторинг планов в динамике помогают системно избегать деградации производительности. Заключая, умение читать планы выполнения запросов - это инвестиция в продуктивность работы с PostgreSQL. Оно позволяет выявлять и устранять узкие места, повышать масштабируемость и отзывчивость приложений. Совмещение классических методов анализа с поддержкой искусственного интеллекта ускоряет процесс оптимизации и помогает командам быстрее достигать стабильных показателей. В результате пользователи получают более плавный и быстрый опыт взаимодействия с данными, а разработчики - уверенность в качественной и масштабируемой инфраструктуре.
.