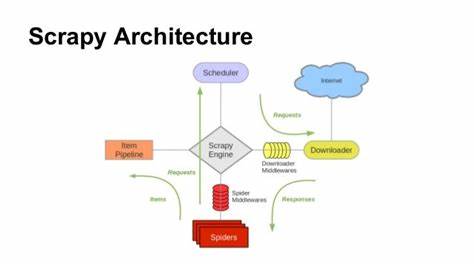
В современном мире цифровых технологий сбор данных из интернета стал неотъемлемой частью бизнеса, исследования и аналитики. Качество и скорость обработки информации во многом определяют конкурентные преимущества компаний и специалистов. Именно поэтому выбор правильного инструмента для веб-скрапинга так важен. В условиях постоянно растущих объемов данных и требований к высокой производительности на помощь приходит Scrapy_cffi - инновационный асинхронный фреймворк, разработанный с акцентом на скорость, модульность и масштабируемость. Scrapy_cffi по своей архитектуре вдохновлен популярным Scrapy, знакомым многим разработчикам Python.
Однако он предлагает более современный и гибкий подход, используя curl_cffi в качестве базового HTTP/WebSocket клиента и полностью перейдя на асинхронное программирование, что позволяет эффективно использовать ресурсы и быстро обрабатывать большое количество запросов одновременно. Основной философией scrapy_cffi является простота, но при этом максимальная оптимизация работы. Фреймворк представляет собой легковесное решение с последовательностью компонентов, уже знакомых тем, кто использовал Scrapy: пауки (spiders), элементы данных (items), перехватчики (interceptors), пайплайны и сигналы. Такой подход обеспечивает плавный переход и минимальную кривую обучения для разработчиков. Важнейшее преимущество scrapy_cffi - это полностью асинхронный движок, построенный на базе asyncio.
Асинхронность сегодня - один из ключевых факторов эффективности приложений, так как она позволяет обрабатывать сотни и тысячи запросов без блокировок и простоев. Интеграция curl_cffi, поддерживающего HTTP и WebSocket, дает возможность легко работать с современными сервисами и динамическими веб-страницами, где часто применяются технологии реального времени. Гибкость - еще одна отличительная черта Scrapy_cffi. Система поддерживает работу с различными базами данных - Redis, MySQL, MongoDB - и реализует асинхронные механизмы повторных подключений и обработки ошибок. Это особенно важно для крупных и распределённых систем, где надежность и устойчивость к сбоям критичны.
Кроме того, scrapy_cffi умеет работать с сообщениями через RabbitMQ и Kafka, что открывает широкие возможности интеграции с существующими экосистемами и масштабирования за счет очередей сообщений. Специалисты по архитектуре распределенных систем оценят возможность настройки многомодового развертывания: одиночный инстанс, кластерный режим и sentinel-мод, которые позволяют адаптировать фреймворк под любые сценарии и нагрузки. Ещё одним достоинством считается легковесная система middleware и interceptor, которые дают инструмент для расширения функционала без необходимости серьезных изменений в исходном коде. Такая модульность способствует творческим решениям и быстрой адаптации под конкретные задачи клиента. Высокая производительность достигается не только за счёт асинхронности, но и благодаря использованию C-расширений для запуска ресурсоёмких операций.
Этот технический подход значительно снижает нагрузку на процессор и минимизирует задержки, что особенно важно при работе с большими объемами данных. Одним из уникальных компонентов scrapy_cffi является Redis-совместимый планировщик. Он позволяет эффективно управлять очередью заданий в распределённых системах пауков и оптимизирует параллельную работу, что существенно увеличивает пропускную способность и стабильность. Для разработчиков, которые только начинают знакомство с scrapy_cffi, предусмотрен простой и интуитивно понятный старт. Из командной строки можно легко создать новый проект, сгенерировать пауков и запустить процесс парсинга без необходимости глубокого погружения в настройки.
Важным моментом стало обновление CLI-инструмента: начиная с версии 0.1.4 командная строка стала более удобной, что ускоряет рабочий процесс. При переходе к более сложным или долгосрочным проектам можно воспользоваться расширенными настройками фреймворка. Система конфигурирования поддерживает загрузку через Python и .
env файлы, что позволяет гибко управлять параметрами окружения. В частности, параметры подключения к базам данных, количество одновременно выполняемых задач, режимы работы пауков и многое другое становятся доступными для центральной настройки. Обновления в системе планировщика также заслуживают внимания. От версии 0.2.
5 планировщики RedisScheduler и RabbitMqScheduler перестали автоматически останавливать работу при пустой очереди. Это нововведение позволяет реализовывать как конечные задачи с заданным числом циклов работы, так и непрерывные, постоянно слушающие очереди пауки. Такой функционал существенно повышает удобство и гибкость развертывания. Ключевая область применения scrapy_cffi - это как небольшие проекты, требующие быстрой и надежной передачи данных, так и крупномасштабные распределенные системы, где важна отказоустойчивость и параллелизм. Рынок сегодня требует от разработчиков надежных инструментов, способных работать в условиях высокой нагрузки, поддерживать сложные методы аутентификации и интеграции с современными протоколами, которые scrapy_cffi реализует из коробки.
Стоит отметить и открытость проекта. Scrapy_cffi распространяется под лицензией BSD 3-Clause, что дает свободу для коммерческого и некоммерческого использования, а также для внесения собственных улучшений. Это делает его привлекательным для компаний, стремящихся к прозрачным и безопасным решениям. Изучение документации и примеров использования в директории docs помогает быстро войти в курс дела и раскрыть весь потенциал фреймворка. В сообществе пользователей развивается практика обмена опытом и лучших практик, что стимулирует развитие проекта и своевременное реагирование на новые потребности индустрии.
Не менее важно и то, что scrapy_cffi отвечает требованиям современного веб-скрапинга. Инструмент учитывает проблемы блокировок, замедленной работы баз данных и сложностей распределенного развертывания, предлагая готовые решения и архитектуры для их преодоления. Уменьшение времени отклика и ускорение цикла обработки информации повышают качество конечного продукта и увеличивают ROI для бизнеса. Scrapy_cffi - это пример того, как философия открытого кода, инновационные технические решения и внимание к реальным задачам индустрии формируют новый стандарт веб-скрапинга. В эпоху, когда данные считаются "новой нефтью", иметь под рукой инструмент, позволяющий быстро и эффективно "добывать" информацию, является решающим фактором для успеха.
Таким образом, scrapy_cffi представляет собой эффективное, современное и масштабируемое решение для разработчиков, аналитиков и исследователей, желающих построить надежный и быстрый процесс сбора данных. В сочетании с асинхронным подходом, поддержкой широкого спектра технологий и удобной системой конфигураций, этот инструмент предлагает оптимальный баланс между сложностью и функциональностью, открывая широкие горизонты для любых проектов в сфере веб-скрапинга. .