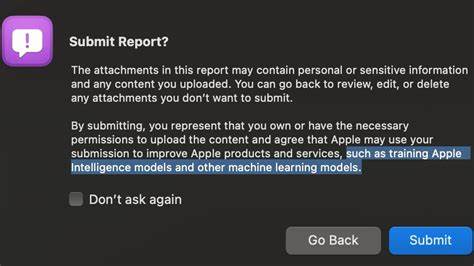
Apple давно зарекомендовала себя как компания, которая уделяет особое внимание защите конфиденциальности пользователей и надежному обращению с их данными. Именно эти принципы помогли компании сформировать один из самых лояльных пользовательских сообществ в мире технологий. Однако недавние изменения в политике обработки отчетов об ошибках вызывают серьезные вопросы и обеспокоенность среди пользователей и разработчиков. Речь идет о том, что теперь Apple намерена использовать информацию из баг-репортов, которая может содержать чувствительные и личные данные, для обучения своих искусственных интеллектов и других моделей машинного обучения. Такой шаг вызывает множество споров и ставит под сомнение прежние гарантии компании по защите приватности данных своих пользователей.
Изменения в политике обработки данных в баг-репортах впервые были замечены пользователями, которые отправляли отчеты с помощью официального инструмента Feedback Assistant. При загрузке диагностических данных — логов, скриншотов или других приложений — пользователям предоставляется уведомление о том, что в этих файлах может содержаться конфиденциальная информация. Нововведением стало упоминание о том, что отправленная информация может использоваться Apple для обучения моделей искусственного интеллекта. Несмотря на важность этой оговорки, она вызвала реакцию недовольства, так как многие восприняли это как попытку компании получить широкие полномочия на использование личных данных без явного согласия и возможности отказаться от этого. Суть критики заключается не только в самом факте использования баг-отчетов для обучения ИИ, но и в формате информирования пользователей.
Многие считают, что предупреждение подано слишком расплывчато и спрятано в уведомлении, которое пользователи не всегда внимательно читают. Для многих представителей сообщества разработчиков и обычных пользователей такой подход воспринимается как нарушение доверия, ведь баг-репорты традиционно рассматривались как средство помочь компании улучшать продукты, а не источник данных для масштабного сбора и обучения нейросетей. Еще одна значимая проблема связана с отсутствием четкой возможности отказаться от использования своих данных для обучения ИИ. В текущем состоянии, чтобы не дать согласие, пользователям практически остается лишь отказаться от подачи отчета об ошибке вообще, что, по мнению многих экспертов, может негативно сказаться на качестве обратной связи и, как следствие, на стабильности и развитии продуктов Apple. Некоторые пользователи выражают опасения, что подобные шаги могут привести к снижению числа отчетов о реальных проблемах, а это, в свою очередь, ухудшит опыт использования устройств и программного обеспечения.
Обсуждения на разнообразных платформах, включая независимые Mastodon-серверы, показывают широкий спектр мнений на этот счет. Одни пользователи считают подобное использование данных вполне оправданным с точки зрения развития технологий, указывая, что именно подобная «живая» информация из реальных сценариев помогает совершенствовать интеллектуальные системы. Другие же подчеркивают, что даже при потенциальной полезности такая масштабная агрегация данных без прозрачности и опции отказа недопустима и противоречит основам цифровой этики. Интересно отметить, что до недавнего времени Apple была известна своими продуманными и ответственными подходами к конфиденциальности. Многие пользователи отмечают, что компания раньше демонстрировала уважение к выбору каждого человека, позволяя гибко управлять сбором данных и настройками приватности.
Теперь же наблюдается тенденция к усилению централизованного контроля и расширению полномочий корпорации над пользовательскими данными, что воспринимается как отступление от прежних принципов. Публичные высказывания разработчиков и активных пользователей указывают на то, что практика использования баг-репортов для обучения ИИ-моделей проходит с недостаточным вниманием к деталям и выдержке. Были замечены даже ошибки в формулировках уведомлений, что добавляет ощущение спешки и непродуманности нововведения. Такое отношение формирует негативный имидж и подрывает доверие сообщества к Apple. Важность тонкой настройки коммуникации при обращении с пользовательскими данными нельзя переоценить, особенно в эпоху, когда вопросы приватности находятся в центре общественного внимания.
С точки зрения технического обоснования, использование баг-репортов для обучения ИИ действительно может иметь свою логику. Анализ реальных ситуаций, описанных в ошибках, помогает моделям лучше понимать поведение системы, выявлять нестандартные сценарии и предлагать более релевантные решения. Это может повысить качество автоматизированной диагностики и ускорить выявление проблем. Тем не менее, это требует тщательного балансирования интересов компании и защиты прав пользователей. Возможные альтернативы включают введение прозрачных и понятных опций для согласия на использование данных именно в целях ИИ-обучения, а также разработку эффективных методов автоматической анонимизации и фильтрации чувствительной информации в присылаемых файлах.
Правильное и ясное информирование пользователей с возможностью отказа — ключевой элемент, который способен сохранить доверие и поддержать активное участие сообщества в улучшении продуктов. На фоне известных случаев неправильного обращения с пользовательскими данными у разных крупных игроков IT-индустрии, Apple предстоит сделать выбор между развитием своих технологий и сохранением имиджа защищенного и ответственного поставщика. Реакция пользователей и разработчиков на такую практику показывает, что вопрос не сводится лишь к техническим возможностям. Прежде всего это вопрос этики, прозрачности и уважения к приватности. Многие эксперты советуют пользователям быть осторожными и внимательно относиться к отправляемой информации, особенно в диагностических отчетах, самостоятельно удаляя или редактируя возможные конфиденциальные данные.
Такая практика снижает риск нежелательного использования личной информации. В целом, ситуация вокруг новой политики Apple демонстрирует естественную сложность баланса между инновациями и ответственностью перед пользователями. Обучение ИИ на базе реальных данных неотъемлемо связано с потенциальными рисками, и именно активное вовлечение сообщества, прозрачность и внимательность способны обеспечить долгосрочный успех любой инициативы в этой сфере. Индустрия технологий продолжает развиваться, и пользователям важно быть информированными и осознанно подходить к вопросам приватности, чтобы сохранить контроль над собственными цифровыми данными и влиять на формирование этических стандартов в эпоху искусственного интеллекта.