Умножение матриц — одна из фундаментальных операций в вычислительной математике, которая занимает центральное место в сфере искусственного интеллекта, машинного обучения и высокопроизводительных вычислений. Особенно в современных архитектурах нейронных сетей, таких как трансформеры, основная часть вычислений заключается именно в умножении матриц. Скорость выполнения этих операций напрямую влияет на возможности и эффективность моделей, от точности прогнозов до времени обучения и инференса. Сложность задачи особенно возрастает с развитием разнообразных аппаратных ускорителей, включая графические процессоры NVIDIA, AMD, Intel и даже специализированные CPU. С этими реалиями возникает острая необходимость в создании мультиплатформенных решений, обеспечивающих универсальную и быструю работу на различных устройствах.
Исторически компания NVIDIA сыграла ключевую роль в ускорении матричных вычислений, особенно благодаря развитию GPU, ориентированных на игры, а затем — на глубокое обучение. Введение Tensor Cores в GPU NVIDIA стало прорывом, значительно ускорившим операции умножения матриц, оптимально использующих возможности параллельных вычислений и специализированных инструкций. Несмотря на то, что такие решения обеспечивают очень высокий уровень производительности, их использование обычно ограничено конкретными аппаратными платформами, что снижает гибкость и переносимость в различных средах. Основная сложность заключается не только в вычислительной нагрузке, сколько в узком месте, связанном с перемещением данных между уровнями памяти — от глобальной памяти до регистров. Чем меньше перемещается данных, тем выше общая производительность.
Эффективным решением становится слияние нескольких этапов вычислений в единый ядро, что позволяет уменьшить лишние операции с памятью. Однако предустановленные библиотеки, такие как cuBLAS и cuDNN, не поддерживают такую гибкость, вынуждая разработчиков создавать кастомные ядра для оптимальной работы с конкретными задачами. Проект CUTLASS от NVIDIA предложил шаблоны на C++, позволяющие создавать специализированные ядра с возможностью тонкой настройки. Несмотря на преимущества, это решение по-прежнему привязано к платформе NVIDIA и остается сложным для использования. В то же время растет спрос на мультиплатформенные инструменты, способные обеспечить сопоставимую производительность на устройствах AMD, Intel и даже в CPU-среде.
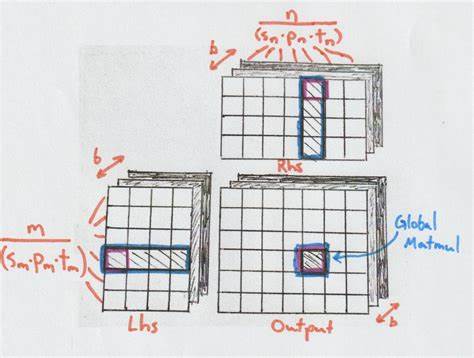
В ответ появился CubeCL — мультиплатформенный движок для генерации оптимизированных ядер умножения матриц, написанный на Rust, что обеспечивает безопасность, высокую производительность и удобство расширения. CubeCL реализует многоуровневую архитектуру, разделяющую задачу умножения матриц на несколько уровней абстракции, позволяя адаптироваться к различным аппаратным возможностям. Такая архитектура базируется на детальном понимании современного GPU: от уровня потоков (units) до блоков потоков (cubes) и групп исполнения (planes). Уровни абстракции CubeCL включают Tile Matmul, который работает с мелкими блоками и отвечает за базовые операции умножения и сложения, Stage Matmul, координирующий работу нескольких Tile Matmul и управляющий локальной памятью (shared memory), Global Matmul, обеспечивающий сборку результатов с различных этапов сокращения и работу с глобальной памятью, и Batch Matmul, который масштабирует выполнение для целых батчей и распределяет вычисления по нескольким блокам GPU. Такая иерархия позволяет эффективно управлять загрузкой памяти, регистров и ресурсов процессора, максимально скрывая задержки и увеличивая параллелизм.
Одним из ключевых аспектов оптимизации является правильное использование регистров и shared memory. Регистры обеспечивают максимально быструю работу с данными, но их количество на Streaming Multiprocessor (SM) ограничено. Чрезмерное использование регистров приводит к так называемому spilling — сохранению избыточных данных в медленную память, что значительно снижает производительность. Shared memory служит промежуточной, быстрой памятью, доступной для взаимодействия между потоками в одном блоке, позволяя кэшировать данные и избегать многократных обращений к глобальной памяти. Для повышения производительности внедряется техника двойного буферизации (double buffering), позволяющая перекрывать загрузку данных с выполнением вычислений.
Таким образом можно добиться асинхронности, когда GPU не простаивает в ожидании данных из памяти. В CubeCL двойная буферизация реализована как на уровне глобальной памяти, так и на уровне shared memory, что приводит к существенному уменьшению простоев и повышению общей пропускной способности ядра. Интересно, что в архитектуре современного GPU существует понятие «plane» — группы потоков, выполняющих инструкции синхронно. Оптимизация работы на уровне plane позволяет снизить риски вредных ветвлений (branch divergence) и эффективно использовать механизмы коалесцированной памяти, при которой последовательные потоки загружают последовательные элементы, оптимизируя использование памяти и уменьшая транзакционные издержки. Архитектура CubeCL также предусматривает отношение к особенностям различных типов матричных умножений.
Для ряда небольших или вырожденных форм матрицы (например, вектор-матрица или матрица-вектор) предусмотрена реализация Tile Matmul на уровне отдельных потоков (units), обеспечивающая гибкость и высокую производительность на устройствах без поддержки специализированных ускорителей. Еще одним важным элементом является использование стратегии под названием «специализация» (plane specialization). В таких схемах разные группы потоков (planes) делятся на вычислительные и загрузочные, чтобы оптимально распределить нагрузку, снизить использование регистров и увеличить occupancy — количество одновременно работающих блоков на SM. Это особенно эффективно для уменьшения задержек загрузки данных и повышения общего уровня асинхронного выполнения. Помимо архитектурных решений, CubeCL предоставляет расширяемые интерфейсы (traits) для всех уровней умножения матриц.
Это позволяет создавать множество вариантов алгоритмов, подгонять их под конкретные приложения и аппаратные условия, поддерживая JIT-компиляцию, что обеспечивает быструю специализацию и оптимизацию во время выполнения. Такой подход значительно повышает гибкость и потенциал производительности. На практике разработчики выделяют несколько семей алгоритмов, отличающихся используемыми оптимизациями: простые ядра без двойной буферизации, алгоритмы с двойной буферизацией, специализированные варианты с разделением ролей между потоками, а также оптимизированные стратегии с тщательным упорядочиванием загрузок данных, минимизирующим синхронизацию. Результаты предварительных бенчмарков показывают, что мультиплатформенные ядра, созданные с использованием CubeCL, демонстрируют сопоставимую, а иногда и превосходящую производительность относительно эталонных библиотек NVIDIA cuBLAS и CUTLASS на различных GPU от NVIDIA и AMD, а также на Apple Silicon с использованием Metal. Особенно ярко проявляется эффективность алгоритмов с двойной буферизацией и упорядоченной загрузкой на платформе Vulkan, что подтверждает глобальный потенциал этой архитектуры.
Эти решения важны не только для высокопроизводительных вычислений в исследовательских центрах, но и для практического применения встраиваемых систем, облачных сервисов и даже веб-приложений, где присутствует разнообразие аппаратных платформ и требования к переносимости и эффективности. В частности, благодаря поддержке CPU и GPU с разных производителей, CubeCL и аналогичные технологии расширяют горизонты использования продвинутых моделей искусственного интеллекта и глубокого обучения. Подводя итог, мультиплатформенные ядра умножения матриц — это сложный, многоуровневый механизм, который объединяет знания аппаратной архитектуры, программных абстракций и алгоритмических техник. Только комплексный подход, включающий четкое управление памятью, эффективное распределение вычислительных ресурсов, и гибкую адаптацию к конкретным задачам, способен обеспечить стабильную высокую производительность в современных вычислительных системах. Развитие этих технологий продолжается, и с появлением новых аппаратных возможностей и расширением экосистемы открытого ПО, мультиплатформенные решения будут становиться все более мощными и универсальными.
Для разработчиков и исследователей, работающих с нейросетями, HPC и системной оптимизацией, понимание таких архитектур и методов становится ключом к созданию эффективных, масштабируемых и портируемых приложений будущего.