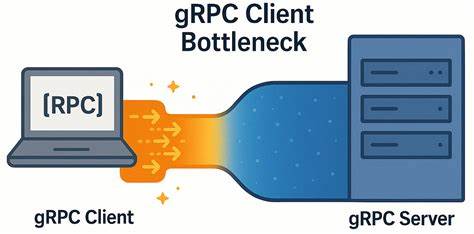
gRPC на сегодня пользуется широкой популярностью благодаря своей эффективности и надёжности при межсервисном взаимодействии. Тем не менее ряд компаний и разработчиков сталкиваются с неожиданными ограничениями производительности именно на стороне клиента, что особенно проявляется в сетях с минимальной задержкой. На таких сетях, где время отклика измеряется сотнями микросекунд, любая даже малая внутренняя проблема клиента способна серьёзно ухудшить общую скорость и отзывчивость системы. Подобное явление стало предметом исследований специалистов YDB, открывших неожиданный узкий участок в реализации gRPC клиента, влияющий на масштабируемость и задержки.В основе gRPC лежит протокол HTTP/2, который обеспечивает мультиплексирование большого количества RPC вызовов по одному TCP-соединению.
Именно такой подход позволяет экономить сетевые ресурсы и эффективно обрабатывать множество параллельных запросов. В классической модели gRPC клиент управляет одним или несколькими каналами, каждый из которых поддерживает множество активных потоков. Однако в практике YDB оказалось, что при создании каналов с одинаковыми параметрами все они неожиданно используют общее TCP-соединение, что ограничивает максимальное число параллельных запросов, накладываемое ограничением HTTP/2 — 100 активных потоков на одно соединение. Проведённые тесты показали, что именно эта особенность стала «бутылочным горлышком» на стороне клиента.В рамках экспериментов был разработан простой микробенчмарк на C++ с использованием асинхронного API gRPC, который позволил выявить аномалии в производительности.
Клиент отправлял запросы с разным уровнем параллелизма (in-flight requests), при этом нагрузка распределялась по рабочим потокам, каждый из которых использовал свой канал. В окружении с очень низкой сетевой задержкой (около 40 мкс) результаты показали, что увеличение числа одновременных запросов не приводит к ожидаемому линейному росту пропускной способности. Причём при увеличении нагрузки заметно возрастало время ожидания отклика, что резко снижало эффективность работы клиента.В ходе анализа сетевого трафика и поведения протокола был зафиксирован отрезок времени порядка 150–200 мкс между получением ответа сервера клиентом и отправкой следующего запроса. Этот промежуток оказался следствием внутреннего механизма реализации gRPC, в частности — очередей на отправку данных и ограничений на параллельные HTTP/2 потоки.
Интересно, что при использовании одного и того же TCP-соединения, но разных каналов с одинаковыми аргументами, многоканальная модель не давала прироста по пропускной способности. Иными словами, сама структура изолированных каналов не решала основную проблему в данной реализации.Всё изменилось, когда каналы стали создавать с различными параметрами и было включено специальное внутреннее переключение GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL, которое ограничивает общий пул соединений. Благодаря этому каждый канал получил собственное TCP-соединение, что в итоге сняло ограничение на одновременные потоки и значительно улучшило масштабируемость. После такой настройки наблюдался рост пропускной способности почти в шесть раз для обычных RPC и примерно в 4.
5 раза для стриминговых вызовов. При этом стабилизировалась и медианная задержка, которая перестала расти линейно с добавлением новых запросов.Важно отметить, что этот узкий участок касается именно известных сетей с минимальной задержкой, таких как высокоскоростные дата-центры и локальные кластеры. В сценариях с сетевой задержкой в несколько миллисекунд разница в производительности между конфигурациями не так заметна. Поэтому в реальных продуктивных условиях с «обычными» сетями проблемы могут не проявляться столь явно.
Тем не менее для оптимизации систем с критическими требованиями к времени отклика описанный подход становится ключевым фактором повышения эффективности.Для достижения лучших результатов используется рекомендация официальной документации gRPC — создавать отдельные каналы для частей приложения с высокой нагрузкой или же использовать пул каналов с уникальными параметрами, чтобы избежать повторного использования одного TCP-соединения. Практика YDB показывает, что правильнее рассматривать эти решения не как альтернативы, а как взаимодополняющие этапы единой стратегии устранения узких мест в клиентской части.Соблюдение балансировки между количеством каналов и нагрузкой на клиентскую машину является критичным. Избыточное количество соединений может привести к ресурсным затратам на уровне операционной системы и росту накладных расходов на обслуживание потоков и очередей.
Поэтому оптимальный выбор числа каналов необходимо делать с учётом конкретного варианта применения, количества потоков, особенностей сетевой инфраструктуры и характера нагрузки.Сделанные в ходе исследования тесты также подчеркивают важность тщательного профилирования и мониторинга систем, особенно в распределённых высокопроизводительных базах данных и микросервисных архитектурах, где gRPC широко используется как транспортный слой. Наличие инструментов для оценки реальной производительности и выявления узких мест позволяет своевременно менять архитектурные решения и улучшать программное обеспечение.Кроме того, описанные принципы имеют универсальный характер и распространяются не только на C++ реализации gRPC, но и на другие популярные языки программирования, включая Java. Следовательно, публикация результатов и соответствующих инструментов для тестирования принесёт пользу широкой аудитории разработчиков и системных инженеров.
В итоге, проблема, которая ощущалась как неожиданная и труднообъяснимая деградация производительности в условиях низкой сетевой задержки, была решена достаточно простым, но малоизвестным методом настройки клиентов gRPC. Эта оптимизация позволяет не только увеличить общую пропускную способность, но и существенно снизить латентность, что критично для современного бизнеса с высокими требованиями к скорости обработки данных.Для разработчиков, использующих gRPC в своих проектах, основной вывод таков: не стоит игнорировать внутренние механизмы работы каналов и их сопряжённость с TCP-соединениями. Подход с отдельными каналами, обеспеченными собственными параметрами, а также использование внутреннего локального пула подсоединений, способны вывести производительность клиентских приложений на качественно новый уровень. В конечном итоге это решение гармонично вписывается в рекомендации официальной документации, но требует более внимательного понимания и тщательного исполнения.
Отказ от единого TCP-соединения для всех каналов открывает путь для значительного масштабирования и позволяет реализовывать высокоэффективные системы на базе gRPC. Сообщество разработчиков и специалисты по распределённым системам получили важное практическое знание, которое поможет избегать скрытых узких мест в архитектуре своих приложений. Это пример того, как глубокий анализ, тщательное измерение и эксперименты подкрепляют теоретические знания и приводят к реальным улучшениям в индустрии цифровых технологий.