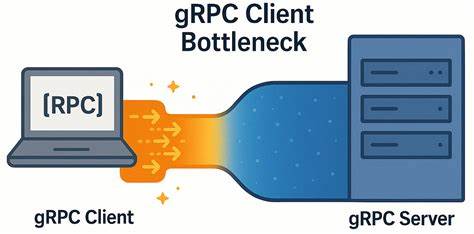
gRPC давно считается одной из наиболее производительных и надежных платформ для межсервисного взаимодействия, активно применяемой в распределенных приложениях и микросервисной архитектуре. Однако при работе в высокопроизводительных распределенных системах иногда возникают неожиданные проблемы, которые могут серьезно ограничивать потенциал сети, даже в условиях современного высокоскоростного соединения с низкой задержкой. Одной из таких проблем является узкое место не на сервере или сети, а именно в gRPC клиенте, что было выявлено недавно при тестировании YDB — распределенной SQL-базы данных с акцентом на высокую доступность и строгую консистентность. Разберем детально суть проблемы, особенности работы gRPC, специфику тестирования и рекомендации для разработчиков, которые помогут избежать подобных ограничений и максимально эффективно использовать возможности gRPC в условиях низкой сетевой задержки. Для понимания корней возникшей проблемы важно осознать общие принципы работы gRPC.
Этот фреймворк реализован поверх протокола HTTP/2, который поддерживает мультиплексирование для одновременного обмена несколькими потоками внутри одной TCP-сессии. gRPC клиент зачастую создает один или несколько каналов (channels) — логических коммуникационных объектов, каждый из которых соответствует одному или нескольким TCP-соединениям. Именно каналы отвечают за управление отрисовкой вызовов удаленных процедур (RPC), которые по сути являются отдельными HTTP/2-стримами. В документации gRPC особо отмечено, что каждый канал может иметь ограничения по количеству параллельно активных HTTP/2 потоков (чаще всего значение по умолчанию около 100). Если число запущенных вызовов превышает эту границу, они начинают ставиться в очередь, что приводит к дополнительной задержке.
Для обхода таких ограничений стандартно предлагается создавать отдельные каналы для разных областей высокой нагрузки или применять пул каналов с уникальными конфигурационными параметрами, чтобы обеспечить многократное использование разных TCP-соединений. В практике YDB стояла задача прогрузить кластер базой данных с целью оценки предельной производительности. При создании минимального количества узлов в кластере неожиданно наблюдалось, что нагрузка с клиента не растет пропорционально ожиданиям, а наоборот – возникают вынужденно простаивающие ресурсы на сервере и увеличение клиентских задержек. Такое поведение привлекло внимание и стало поводом для глубокого исследования. Для выявления причин и воспроизведения поведения был разработан простой gRPC микро-бенчмарк, реализованный на C++ и также протестированный на Java, что подтвердило универсальность проблемы.
Бенчмарк представляет собой вариант ping-протокола, где клиент запускает множество параллельных потоков с собственным gRPC каналом, отправляющих RPC-запросы к серверу с минимальным payload для исключения влияния обработки данных и максимально сфокусироваться на коммуникационном слое. Тестирование проводилось на двух серверах с процессорами Intel Xeon Gold и гиперпотокингом, связанных скоростным 50 Гбит/с каналом с RTT около 0.04 мс, что является практически оптимальным сценарием с низкой задержкой сети. Для оценки стабильности и корректности результатов была проведена проверка сетевого стека и показано отсутствие задержек, связанных с TCP параметрами или признаками перегрузки. Результаты тестов показали интересную картину.
При увеличении числа одновременно выполняемых запросов (in-flight) с клиента пропускная способность увеличивалась существенно меньше, чем прогнозировалось теоретически, а задержка резко возрастала. Фактически была обнаружена непропорциональная деградация отклика, обусловленная параметрами и внутренними механизмами gRPC на стороне клиента. Детальный анализ сетевых захватов и логов коммуникаций выявил, что при использовании стандартных настроек все RPC на разных потоках клиентского приложения фактически идут через одно и то же TCP-соединение. Это значит, что все параллельные запросы внутри одного канала мультиплексируются по одним и тем же HTTP/2 потокам, что приводит к внутренней очереди и ощутимой задержке из-за особенностей очередности и обработки трафика. Проведённые опыты с созданием пулов каналов с идентичными параметрами не улучшили ситуации, поскольку по умолчанию gRPC соединяет такие каналы к одному TCP-соединению.
Лишь после задания уникальных параметров канала или включения специального аргумента GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL, заставляющего клиент использовать отдельные подподключения, удалось добиться значительного повышения производительности. В оптимальной конфигурации каждый клиентский поток имел свой канал с уникальными аргументами, что обеспечило распределение нагрузки на несколько TCP-соединений и уменьшение задержек, достигая почти идеальной масштабируемости. Подобные проблемы часто остаются незамеченными в сетях с высокой задержкой, например с RTT около нескольких миллисекунд, поскольку там время сетевого обмена доминирует и скрывает внутренние издержки клиента. Однако в условиях высокоскоростных дата-центров с низкой задержкой (десятки микросекунд) влияние нейтральных ранее моментов становится критичным и значительно сказывается на общей производительности. Важной практической рекомендацией для разработчиков gRPC клиентов с высокой нагрузкой является создание не одного мощного канала, а нескольких каналов с уникальными конфигурациями для перераспределения нагрузки, используя концепцию пулов или per-worker каналов, особенно в применениях с большим числом параллельных коротких вызовов.
Это позволяет избежать очередей на уровне HTTP/2 потоков и максимально использовать пропускную способность сети и вычислительные ресурсы. Промежуточные данные и тайминги из экспериментов подтвердили, что решение задачи в одном канале приводит к простою порядка 150-200 микросекунд между выходом байтов одного пакета и передачей следующего, что для сверхнизкой задержки является значительным узким местом. Разделение каналов устраняет этот «пробел» и повышает как пропускную способность, так и стабилизирует высокую производительность при росте числа запросов. В заключение можно отметить, что выявленное узкое место на стороне gRPC клиента является важным фактором, который следует учитывать при проектировании масштабируемых систем с использованием gRPC в условиях высокопроизводительных сетей. Неправильная организация каналов и соединений может нивелировать преимущества оборудования и сетевой инфраструктуры, приводя к неоправданным задержкам и ухудшению отзывчивости приложения.
Следует внимательно изучить документацию gRPC, не забывая о тонкостях ограничения параллелизма HTTP/2 и свойствах TCP соединений, а также воспользоваться опытом сообщества, в частности рекомендациями по созданию отдельных каналов с уникальными аргументами или активации локального пула подподключений. Кроме того, представленные здесь микро-бенчмарки и методики диагностики могут стать отправной точкой для собственных тестов и оптимизаций, позволяющих выявлять узкие места в реальных приложениях и эффективно их устранять. Сложности в реализации таких решений могут компенсироваться значительным приростом производительности и снижением латентности, что особенно критично для систем реального времени, финансовых приложений, больших распределенных баз данных и других сценариев, требующих высочайшей отзывчивости и пропускной способности. Таким образом, узкое место в gRPC клиенте при работе в условиях сетей с низкой задержкой является важным фактором, влияющим на эффективность сервисов. Решение задачи требует не просто масштабирования клиентских потоков, а грамотного управления каналами и правильной архитектуры взаимодействия с сетью.
Применение данных рекомендаций поможет разработчикам максимально приблизиться к теоретическому пределу производительности, обеспечивая стабильность и надежность своих систем в самых требовательных условиях.