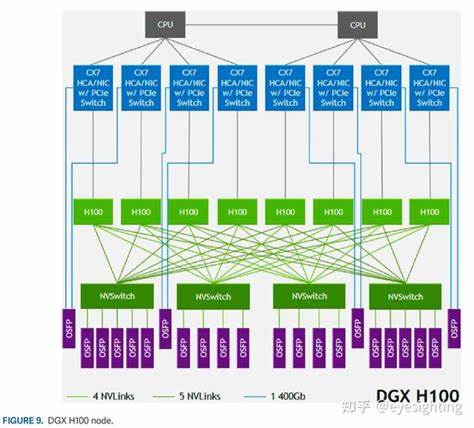
Современное развитие графических процессоров и систем ускорения вычислений никогда не стояло на месте. В последние годы мы наблюдаем стремительный рост технологических возможностей, которые открывают новые горизонты в сфере искусственного интеллекта, машинного обучения и обработки больших данных. Одним из ярких примеров таких достижений стала Nvidia H100 PCIe - графический процессор последнего поколения, предоставляющий впечатляющую пропускную способность памяти, достигающую 1.86 Терабайт в секунду при операциях memcpy, а также обеспечивающий восьмикратное ускорение по сравнению с предыдущими показателями. Эти результаты стали возможны благодаря новым методам оптимизации памяти и архитектурным улучшениям, значительно повышающим производительность и эффективность вычислений в реальных приложениях.
H100 PCIe является флагманским решением Nvidia для задач с высокими требованиями к скорости передачи данных и вычислительной мощности. Тесты с использованием A/B-бенчмарков на 80-гигабайтной версии данного GPU продемонстрировали непрерывную пропускную способность копирования памяти в районе 1.86 ТБ/с. Причем эта скорость сохранялась как в базовом варианте, так и после оптимизации, что говорит об отсутствии накладных расходов на оптимизированные методы. При работе с непрерывной последовательной памятью (contiguous memcpy) показатели стабильно держались на максимальном уровне.
Однако существенный прирост был достигнут именно при обработке более сложных шаблонов доступа к памяти, таких как страйдовые (strided) и смещённые (misaligned) обращения. В стандартных условиях производительность при таких типах доступа составляла порядка 230 ГБ/с, что ограничивало общую эффективность обработки данных. Оптимизированный же вариант достиг впечатляющих 1.86 ТБ/с, что эквивалентно примерно восьмикратному росту. Такое улучшение особенно важно для сценариев, где происходит нерегулярный или разреженный доступ к данным, что характерно для многих алгоритмов машинного обучения и нейронных сетей.
Также подтверждена высокая производительность при работе с большими объемами данных, варьирующимися от 8 до 24 гигабайт, позволяющая сохранять максимальную пропускную способность на уровне 1.86 ТБ/с. При исследовании канонических CUDA-ядр, используемых в операциях memcpy, страйд-доступе, KV-cache и LayerNorm, наблюдалось значительное повышение эффективности. Ранее эти операции работали в диапазоне 220-330 ГБ/с, но после оптимизации показатели возросли до 1.8-1.
86 ТБ/с, что сопровождается минимальными флуктуациями в скорости выполнения. Такая стабильность и высокая производительность выходят за привычные рамки и открывают новые возможности для ускорения вычислений, особенно в работе с большими языковыми моделями. Одним из ключевых аспектов стала иллюстрация влияния оптимизаций, основанная на простой модели оценки стоимости расчета декодирования в больших языковых моделях (LLM). В частности, при использовании базовой производительности с пропускной способностью памяти, рассчитанной как 1.13 МБ на токен, пропускная способность обработки достигала примерно 161.
9 тыс. токенов в секунду. После внедрения оптимизированных подходов этот показатель вырос до 225.1 тыс. токенов в секунду, что составляет около 1.
39 раза увеличения. Это указывает на то, что узкие места, связанные с памятью, такие как операции KV-cache и страйдовые загрузки, можно эффективно устранить и приблизиться к предельной пропускной способности памяти (roofline bandwidth). Оптимизации памяти в контексте расчётов больших нейросетевых моделей являются критически важными, поскольку именно они часто становятся узким местом на пути повышения производительности в задачах обучения и инференса. Для обучения моделей нагрузка на память обычно выше из-за необходимости хранения больших батчей данных и промежуточных результатов, тогда как для инференса востребована максимально быстрая обработка и отдача результатов в режиме реального времени. Успешный рост пропускной способности памяти, как показано в кейсе H100 PCIe, позволяет не только ускорить инференс, но и потенциально снизить время обучения, если данные и промежуточные вычисления оптимально распределены и ускорены.
При этом существует интересный вопрос, насколько данные оптимизации повлияют на долгосрочные и масштабируемые сценарии обучения больших моделей с длительным контекстом (например, от 8 до 32 тысяч токенов). Существуют различные бенчмарки, позволяющие оценить работу моделей с длинным контекстом, однако их стандартизация в публичном доступе пока остается открытой. Разработка таких бенчмарков поможет определить реальные преимущества новых технологий и предложенных алгоритмов, позволяя исследователям и разработчикам выбирать оптимальные решения для своих задач. Помимо технических характеристик, важным фактором при анализе производительности является отсутствие заметных задержек или флуктуаций в скорости работы, что играет большую роль при развертывании систем машинного обучения в производствах и облачных сервисах. Низкое время отклика и высокая стабильность, как показали тесты с H100 PCIe, приводят к более плавной обработке запросов и значительному улучшению пользовательского опыта в приложениях с интерактивным вводом.
В целом достижения, полученные с помощью оптимизаций и архитектурных улучшений графического процессора Nvidia H100 PCIe, открывают новые горизонты как для исследовательских, так и для промышленных задач с высокими требованиями к скорости обработки данных. Рост пропускной способности памяти до 1.86 ТБ/с - это знаковый рубеж, которого ранее было сложно достичь на практике. Восемь раз повышенная эффективность при обработке сложных паттернов доступа к памяти обеспечивает заметное воздействие на производительность крупных компьютерных систем и нейросетевых моделей. В перспективе дальнейшие исследования и разработки могут сосредоточиться на оптимизации распределённой обработки данных, улучшении алгоритмов работы с кешем и снижении энергопотребления при сохранении высокой производительности.
Кроме того, разработка универсальных и доступных публичных бенчмарков для тестирования длинного контекста станет важным шагом для оценки эффективности различных методов и систем. Таким образом, результаты, достигнутые в рамках анализа производительности H100 PCIe, служат важным ориентиром для специалистов в области высокопроизводительных вычислений и искусственного интеллекта. Они демонстрируют, каким образом современные технологии могут улучшить эффективность и масштабируемость машинного обучения, предоставляя мощные инструменты для решения самых требовательных вычислительных задач будущего. .





![AI Made a Movie About Its Own Future [video]](/images/DF1EFABB-6B49-4C1F-B4BD-205BA7D58474)