Обучение с подкреплением занимает одно из ключевых мест в современной науке о данных и искусственном интеллекте. Сегодня специалисты всё чаще обращаются к методам политики градиента, которые обеспечивают эффективное обучение агентам в разнообразных средах. В последние годы благодаря росту возможностей аппаратного обеспечения и развитию программных экосистем возможности этих методов значительно расширились. Одним из наиболее перспективных инструментов разработки и экспериментов в области градиентных методов для обучения с подкреплением стал JAX — библиотека для машинного обучения от Google, которая предлагает функциональный и эффективный подход к вычислениям с автоматической дифференцировкой. В данной работе предлагается обратить внимание на тонкости реализации и усовершенствования политики градиента в JAX на примере классической задачи управления CartPole-v1.
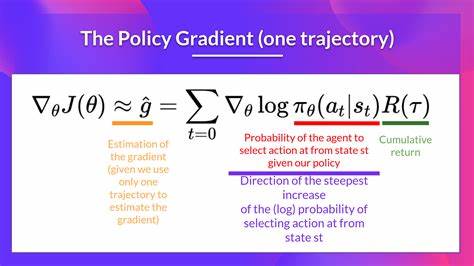
Эксперименты показывают, каким образом можно повысить стабильность и качество обучения, включив в алгоритмы такие улучшения, как вычитание базового значения, регуляризацию энтропии, обрезку градиентов и нормализацию вознаграждений по эпизодам. Важно понимать, что методы градиента политики направлены на оптимизацию параметров агентской политики посредством измерения градиентов функции вознаграждения. Однако базовая реализация VPG (Vanilla Policy Gradient) зачастую подвержена высоким колебаниям и нестабильностям в процессе обучения. Это связано с высокой дисперсией оценок градиентов из-за того, что обновления параметров зависят от конкретных значений вознаграждений в эпизодах. Для борьбы с этим в реализации на JAX были внедрены несколько ключевых улучшений.
Во-первых, применена техника вычитания базового значения из функции преимущества. Вместо прямого использования суммарных вознаграждений возвращается преимущество, которое вычисляется как разница между общим вознаграждением и средним значением вознаграждений по текущему набору эпизодов. Это значительно снижает дисперсию градиентов, делая обучающий процесс более устойчивым и предсказуемым. Во-вторых, в процесс обучения введена градиентная обрезка. Эта техника предотвращает взрыв градиентов, лимитируя их норму в пределах заданного порога.
В реализации это реализовано с помощью интеграции специализированных функций из оптимизационной библиотеки optax, позволяющей ограничивать норму градиентов при расчётах на каждой итерации, что улучшает сходимость и предотвращает чрезмерное обновление параметров модели. Третьим важным элементом оптимизации служит нормализация вознаграждений по эпизодам. Вознаграждения в рамках каждого эпизода подлежат стандартизации, чтобы приводить их к нулевому среднему и единичной дисперсии. Это позволяет нивелировать влияние разной длительности эпизодов и обеспечивает более корректное расчётное сравнение показателей эффективности между ними. Четвёртая составляющая — регуляризация энтропии.
Добавляя к функции потерь энтропийный член с некоторым коэффициентом, алгоритм стимулирует политику к сохранению разнообразия действий, что способствует лучшему исследованию среды и сокращает вероятность преждевременного застревания в локальных оптимумах. Результаты серии экспериментов показывают, что каждый из вышеназванных элементов вносит заметный вклад в улучшение качества обучения и общую стабильность процесса. Сравнительный анализ различных вариантов реализации, включая базовую VPG, вариант с вычитанием базового значения, с добавлением энтропии и полный набор улучшений, выявляет, что комбинация всех четырёх подходов значительно превосходит по итоговым результатам остальные конфигурации. Для практического внедрения методов был использован современный и эффективный инструментарий JAX, позволяющий реализовать вычислительные графы с автоматическим дифференцированием и поддержкой аппаратного ускорения. Это даёт возможность интегрировать сложные техники оптимизации без существенного увеличения вычислительной нагрузки, что важно для масштабируемых и высокопроизводительных решений в обучении с подкреплением.
Помимо базовых технологий, пользователи также могут настраивать процесс обучения под собственные задачи, задавая параметры длины эпизодов, частоты обновления модели, уровня регуляризации и возможности визуализации результатов. Все эти опции реализованы в форме командной строки, что упрощает использование и интеграцию в существующие конвейеры экспериментов. Отдельно стоит обратить внимание на легкость расширения и добавления пользовательских вариантов алгоритмов благодаря продуманной архитектуре кода. Для разработчиков открыт доступ к основной библиотеке вариантов, позволяя легко создавать и тестировать новые модификации без необходимости глубоко погружаться в базовый код. Кроме того, возможность быстрого запуска сравнительных экспериментов с визуализацией результатов помогает оперативно анализировать эффективность разных подходов.
Проведённые эксперименты с функциями потерь и тренировочными параметрами показывают, что методы улучшения стабилизируют обучение и уменьшают разброс значений, ускоряя достижение высокой средней награды в классической задаче балансировки CartPole. Это подтверждает мнение специалистов, что современные усиленные методы градиента политики, дополненные механизмами снижения дисперсии и регуляризации, являются важной вехой в развитии алгоритмов обучения с подкреплением. На сегодняшний день набор инструментов для реализации подобных решений быстро растёт, и JAX выступает в этой области мощным помощником, обеспечивающим высокий уровень производительности при гибкости и удобстве настройки. Итогом можно считать то, что опыт экспериментов с методами градиента политики в JAX показывает реальные примеры того, как комбинация нескольких проверенных техник ведёт к качественному улучшению результатов обучения агентов. Это открывает перспективы мировому сообществу исследователей и практиков расширять границы возможностей искусственного интеллекта и решать новые задачи в сферах робототехники, автоматизации и интеллектуального анализа данных.
Таким образом, устойчивая и доступная реализация алгоритмов, построенных на основе градиента политики, становится важным шагом на пути к развитию ответственных и эффективных систем автопилотирования и адаптивного поведения в сложных условиях.









