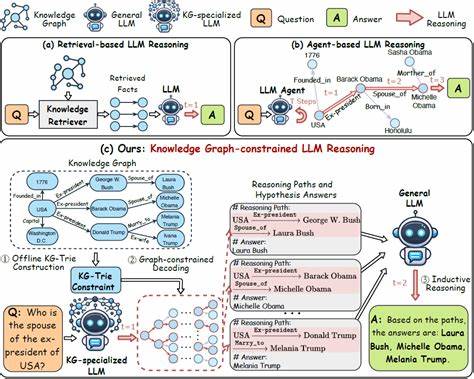
Современные большие языковые модели (LLM) демонстрируют впечатляющие способности к решению сложных задач благодаря развитию методов явного структурированного мышления. Однако длительность процесса рассуждения оказывает значительное влияние на качество конечного ответа. Если этап размышлений слишком короткий, модель может не учесть все аспекты задачи, что приводит к неполному или неточному результату. С другой стороны, слишком длинный процесс рассуждений способствует избыточным вычислениям, замедляет работу и иногда ухудшает результаты из-за переосмысления — так называемого эффекта «перемышления». Понимание и управление длиной мыслительного пути становятся ключевыми для эффективного использования LLM в реальных приложениях.
Недавно представленная методика, которая условно можно назвать «overclocking» — или «разгон» процесса рассуждений — открывает новые возможности для оптимизации работы LLM за счёт мониторинга и управления этапом мышления. Исследования учёных из Тель-Авивского университета и IBM Research позволили выявить, что большие языковые модели внутренне кодируют свой прогресс в процессе рассуждений. Эта особенность даёт возможность создать визуализацию в виде индикатора загрузки, который отражает процент завершения размышлений модели в режиме реального времени. Такое отображение не только улучшает интерпретируемость работы модели, но и помогает глубже понять логику планирования текста и рассуждений, что ранее было недоступно. Основой для этой работы стало разделение процесса генерации ответа на этапы с явными токенами, обозначающими начало и конец «фазы мышления».
Анализ внутренних состояний модели позволил сопоставить каждую скрытую репрезентацию токена с его нормализованной позицией в общей последовательности рассуждений. Это дало учёным возможность выявить тесную связь между внутренним состоянием модели и текущим этапом размышлений. Специально обученные регрессионные модели смогли предсказывать относительный прогресс мышления, что подтверждает идею о существовании в модели скрытого индикатора прогресса. Для более точного моделирования временных связей в серии токенов исследователи применили простую сеть с рекуррентными связями — однослойный GRU. Эта архитектура лучше справлялась с обобщением информации на различных наборах данных, что демонстрирует её универсальность и способность выявлять закономерности в течении процесса рассуждения.
Ключевой инновацией стала возможность контролировать процесс размышлений путём вмешательства в скрытые состояния модели. Посредством добавления управляемого сдвига вдоль направления, отвечающего за прогресс мышления, была разработана техника «overclocking». Вставляя определённый коэффициент влияния на скрытое состояние после слоя внимания, исследователи смогли «ускорять» внутрений ход рассуждений, принуждая модель завершать размышления раньше без потери качества ответа. Применение такого подхода позволило добиться существенного сокращения длины цепочек рассуждений, в ряде случаев уменьшив количество токенов более чем в шесть раз. При этом, точность и качество решений сохранились, а иногда даже улучшились за счёт устранения избыточных раздумий и колебаний, которые наблюдаются в стандартных траекториях мышления.
Эти свойства существенно снижают задержки при выводе модели и делают её ответы более лаконичными и уверенными. Визуализация процесса размышлений в виде прогресс-бара облегчает понимание внутренних состояний языковой модели. Пользователи и разработчики могут наглядно видеть, на каком этапе находится модель и насколько близко она к завершению рассуждений. Эта прозрачность позволит создавать новые виды интерфейсов с возможностью динамического вмешательства в ход вычислений, адаптируя процесс генерации ответа под конкретные задачи и требования к времени отклика. Управление длиной процесса мышления можно рассматривать как важный шаг к созданию более интерактивных и адаптивных систем с искусственным интеллектом.
Способность LLM не только содержать, но и контролировать состояние собственного рассуждения раскрывает перспективы развития архитектур, которые смогут самостоятельно регулировать глубину анализа и объём вычислений в зависимости от поставленной задачи. Помимо улучшения производительности и снижения вычислительной нагрузки, «overclocking» способствует повышению интерпретируемости моделей, что является одним из фундаментальных вызовов в современных исследованиях искусственного интеллекта. Глубже понимая, как модели обрабатывают и структурируют информацию, исследователи смогут создавать более надёжные, объяснимые и эффективные ИИ-системы. Текущие результаты показывают, что скрытые представления в LLM не только представляют смысл и контекст текста, но также несут в себе метаинформацию о ходе внутреннего мышления модели – своего рода «хронометраж» процесса рассуждения. Использование этой метаинформации открывает широкий спектр возможностей для дальнейших исследований, включая автоматическую адаптацию глубины рассуждений в зависимости от сложности вопроса и требований пользователя.
В долгосрочной перспективе такие технологии могут быть интегрированы в платформы интеллектуального анализа данных, системы автоматизированной помощи и обучения, а также в разработку новых архитектур языковых моделей, которые смогут управлять своей вычислительной активностью с большей эффективностью и точностью. Использование методов мониторинга и регулирования мышления больших языковых моделей открывает двери к новому поколению ИИ, способного к более рациональному использованию ресурсов, улучшению качества решений и повышению удобства взаимодействия с человеком. Благодаря подобным инновациям искусственный интеллект становится не только мощным инструментом для решения сложных задач, но и более понятным, надёжным и адаптивным партнёром в различных сферах деятельности.

![I Left the U.S. for India and Built a $23M Burrito Business [video]](/images/B9E239FB-8CAE-4CD2-83DD-B7C628F38E45)