Регулярные выражения давно стали неотъемлемой частью работы разработчиков, аналитиков данных и специалистов по обработке текста. Несмотря на их мощь и универсальность, классические движки часто сталкиваются с проблемами производительности при использовании более сложных конструкций, таких как lookbehind'ы. В частности, многие популярные движки, которые поддерживают lookbehind, использовали алгоритмы с backtracking, что приводило к экспоненциальному росту времени обработки при определённых ситуациях. Однако недавние исследования и внедрения постепенно меняют эту парадигму, одним из ярких примеров чему стало добавление поддержки линейно-временных lookbehind’ов в движок RE2. RE2 — это высокопроизводительный движок регулярных выражений, разработанный компанией Google с прицелом на безопасность, потокобезопасность и предсказуемую производительность.
В отличие от backtracking-движков, RE2 использует гибридный подход, сочетая NFA-симуляцию и ленивые DFA, что гарантирует линейное время работы при большинстве сценариев. Ранее поддержка lookbehind была ограничена либо отсутствовала ввиду сложности и потенциальной потери производительности. Но новые исследования доказывают, что с правильными алгоритмами возможно реализовать lookbehind’ы в линейное время без ущерба. Основой для изменений стал алгоритм, представленный в 2023 году учёными из Systems and Formalisms Lab, опубликованный в статье «Linear Matching of JavaScript Regular Expressions». Они продемонстрировали, что lookaround-конструкции, включая lookbehind, могут обрабатываться линейно, благодаря инновационному использованию таблиц позиций сопоставления и одновременной симуляции множества автоматов.
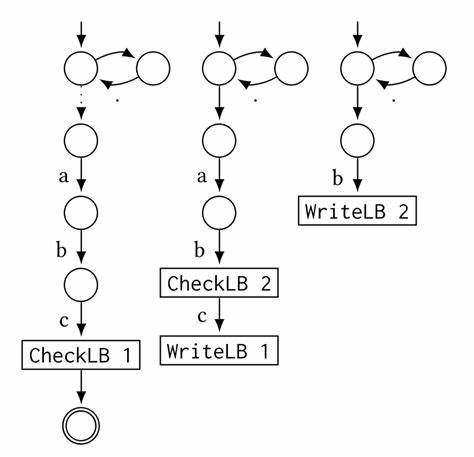
Это стало настоящим прорывом, позволяющим отказаться от затратных backtracking-подходов. Реализация в RE2 опирается на модификацию NFA-движка. Главная идея вызывает вспоминание классической симуляции NFA с дополнительной таблицей, которая хранит последние позиции, где текущее lookbehind-выражение было успешно сопоставлено. Каждый lookbehind компилируется в отдельный автомат, в котором конечные состояния заменены на команды WriteLB, пишущие текущую позицию в таблицу. Основной автомат же заменяет lookbehind на команду CheckLB, которая обращается к таблице для проверки соответствия.
Все автоматы запускаются синхронно, при этом отдаётся приоритет вложенным lookbehind’ам, чтобы корректно отрабатывать состояние таблицы. В RE2 эти изменения потребовали трансформаций в нескольких ключевых компонентах. Во-первых, парсер был расширен для распознавания синтаксиса captureless lookbehind — конструкций типа (?<=r). Добавлены новые токены, аналогичные уже существующим для группировки и альтернатив. При этом обработка скобок смотрит на такую конструкцию и собирает внутренний AST, помещая её в отдельный узел типа позитивного или негативного lookbehind.
Далее компилятору пришлось научиться переводить новые AST-узлы в инструкции LBWrite и LBCheck. В присутствующих файлах re2/compile.cc и re2/prog.cc были созданы методы для генерации соответствующих автоматов, а также методы для встраивания посылок из lookbehind’а в основной автомат. Важно, что для каждого lookbehind создаётся отдельный автомат с началом в определённой точке, а их начальные состояния аккуратно упорядочены по уровню вложенности.
Также была добавлена локальная таблица в NFA-движок, которая хранит указатели на последние позиции текста, удачно сопоставленные с каждым lookbehind. При выполнении LBWrite позиция сохраняется, а при LBCheck проверяется наличие соответствия. Таким образом, основной автомат может принимать решения на основании истории проверок lookbehind’ов, не прибегая к дорогостоящему возврату. Обязательным изменением стала доработка логики выбора движка, поскольку поддержка линейных lookbehind’ов пока реализована только в NFA-движке. В случаях присутствия lookbehind’а RE2 отказывается от попыток использовать оптимизированные алгоритмы DFA или OnePass, напрямую используя модифицированный NFA для корректного и эффективного сопоставления.
Для подтверждения работоспособности и корректности реализации были добавлены новые тесты, покрывающие позитивные и негативные lookbehind'ы на различных строках и сценариях. Кроме того, было проведено исследование производительности, демонстрирующее, что время выполнения остаётся линейным, даже при увеличении длины текста. Такие результаты внушают уверенность в том, что предложенный подход не только теоретически верен, но и практичен для реальных задач. Подобное нововведение открывает дверь для более широкого применения сложных регулярных выражений в системах, требующих высокой производительности и надёжности, включая парсеры, системы поиска, мониторинга и обработки данных. Разработчики теперь могут использовать lookbehind’ы без опасений замедления, что повышает выразительность и удобство написания паттернов.
Перспективы дальнейшей работы включают расширение поддержки для captureless lookahead’ов и групп, где, согласно исследованию, можно использовать похожие идеи, хотя и с определёнными ограничениями в памяти и семантике, свойственной JavaScript. Возможно также последующий перенос этих улучшений в другие движки, основанные на DFA или гибридных алгоритмах, что расширит охват и возможности. Таким образом, интеграция линейно-временных captureless lookbehind’ов в мощный движок RE2 — это важный шаг на пути к развитию технологий работы с регулярными выражениями. Этот прорыв сочетает в себе научные исследования и инженерную практику, открывая новые возможности для программирования и обработки текстовой информации, позволяя обеспечивать высокую скорость и надёжность даже при использовании сложных и вложенных регулярных конструкций.