В современном программировании часто возникает задача обмена сообщениями между процессами с максимальной скоростью и минимальными накладными расходами. Одна из наиболее эффективных технологий для решения этой задачи — lock-free очереди с двойным отображением памяти, обеспечивающие непрерывный адресный пространство для кольцевого буфера без необходимости копирования данных. Подобные очереди особенно полезны при передаче переменного размера сообщений, когда стандартные решения зачастую сталкиваются с проблемами производительности и сложностями управления памятью. В данной статье рассматриваются основы, архитектура и особенности реализации контекста lock-free очереди с двумерным отображением памяти, а также анализируются преимущества и сфера применения такой технологии. Одним из ключевых вызовов при создании эффективной межпроцессной коммуникации (IPC) является возможность одновременно гарантировать непрерывность памяти, минимальные задержки и отсутствие копирования данных.
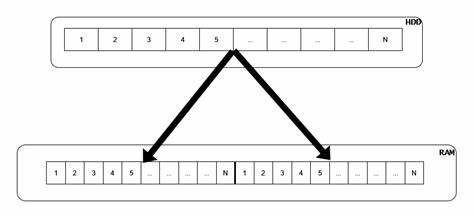
Традиционные кольцевые буферы хорошо справляются с фиксированными размерами сообщений в режиме единственного производителя и единственного потребителя, обеспечивая сравнительно простое и быстродействующее решение. Однако при работе с переменными по длине сообщениями материализуется сложность в поддержке согласованности данных и гарантии, что сообщение не окажется разбитым на две части в кольце — в конце и начале буфера. Для решения этой проблемы чаще всего используют дополнительные копирования, что негативно сказывается на производительности и увеличивает задержки. Инновационный подход, реализованный в концепции двумерно отображенной очереди (doubly-mmapped queue), позволяет эффективно управлять кольцевым буфером так, чтобы область памяти с данными была видна непрерывно в процессе чтения и записи. Суть метода заключается в создании одного региона памяти размером, например, N байт, и маппинга этого региона дважды в виртуальном адресном пространстве процесса так, чтобы вторая копия располагалась непосредственно следом за первой.
В итоге получается виртуальное непрерывное окно из 2N байт, где область от 0 до N совпадает с областью от N до 2N. Это решение устраняет необходимость копирования, ведь даже если сообщение начинается в конце буфера, оно будет непрерывно доступно из-за второго отображения. Основу реализации составляют системные вызовы, такие как mmap и munmap в Unix-подобных системах. Для управления памятью применяется RAII-обертка, отвечающая за корректное отображение и снятие отображения, что значительно упрощает код и повышает надежность. Особое внимание уделяется контролю кэш-линий и выравниванию данных, чтобы не возникало ложного совместного использования кэш-линий (false sharing), что негативно сказывается на производительности в многопоточных и межпроцессных системах.
Для этого в структуре контроля используются атрибуты, выравнивающие соответствующие переменные по размеру кэш-линий процессора. Структура управления очередью состоит из атомарных счетчиков для позиций чтения и записи, а также версии, что позволяет не блокировать потоки и избежать состояния гонок. Благодаря использованию атомарных операций обеспечивается корректное взаимодействие между производителем и потребителем. Важным элементом является реализация интерфейсов как со стороны читателя (consumer), так и со стороны писателя (producer). Читатель получает константный буфер, который ссылается непосредственно на общий буфер без дополнительного копирования, что позволяет прочитать сообщение напрямую.
После обработки данных вызывается метод pop, сдвигающий внутренний указатель чтения и освобождающий пространство для писателя. Соответственно, писатель через метод get_buffer получает изменяемый буфер, куда записывает данные, после чего фиксирует новые данные вызовом push. Такой дизайн устраняет необходимость в блокировках и снижает задержки в обмене. В предоставленном примере использования очередь оснащена пользовательским заголовком сообщения, который строго упакован и выровнен для правильного и безопасного считывания без смещений. Заголовок содержит версию сообщения, размер и временную метку, что позволяет читателю корректно обработать структуру и данные, а также отслеживать задержки передач.
Производительность данной реализации была измерена на тестовом стенде с использованием таймера с точностью до тактов процессора (TSC). При передаче миллиона сообщений с имитацией «редких событий» среднее время обработки составило околo 60 наносекунд, что соответствует чрезвычайно низкой задержке и высокой пропускной способности. Такой уровень достигается благодаря отсутствии копирований, lock-free архитектуре и эффективному кэшированию. Использование подобной технологии может быть особенно полезно в системах высокопроизводительных вычислений, финансовых приложениях с высокочастотной торговлей, системах реального времени, игровых движках, а также везде, где критично минимизировать время обмена данными между процессами или потоками. Несмотря на очевидные преимущества, стоит учитывать некоторые моменты: успешное применение требует внимательного тестирования и профилирования в реальных условиях, так как оптимизации на микроуровне и взаимодействие с аппаратной архитектурой процессора могут существенно влиять на итоговую эффективность.
Использование таких низкоуровневых техник требует глубоких знаний в области системного программирования и особенностей работы с памятью. Кроме того, перенести такую очередь на разные операционные системы с отличающимися моделями управления памятью может быть непросто, так как метод двойного отображения зависит от особенностей адресного пространства и работы с файлами. В итоге технология двумерно отображенной lock-free очереди с непрерывной разделяемой памятью представляет собой мощный инструмент для организации высокоскоростного межпроцессного обмена с переменными по размеру сообщениями без необходимости копирования и блокировок. Правильная реализация и настройка такой очереди позволяет существенно повысить производительность и уменьшить задержки в критически важных приложениях. Для дальнейшего развития темы полезно интегрировать такие очереди в реальные проекты, проводить глубокий анализ с инструментами профилирования, а также изучать оптимизации на уровне ассемблера и процессора.
Таким образом, данный подход открывает перспективы в создании современных архитектур обработки данных с максимальной эффективностью и масштабируемостью.