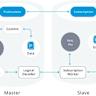
Логическая репликация в PostgreSQL сегодня является одним из ключевых инструментов для организации масштабируемых, отказоустойчивых и безопасных систем управления базами данных. В отличие от физической репликации, которая копирует блоки данных на уровне физических файлов, логическая репликация работает на уровне изменений в строках таблиц, предлагая значительно больше гибкости, что особенно важно для современных прикладных решений и распределённых архитектур. Для тех, кто уже знаком с первичными шагами настройки репликации, пришло время углубиться и понять, как эффективно управлять этим процессом в реальных условиях эксплуатации. Одним из первых аспектов, на который стоит обратить внимание при настройке подписчика, является выбор способа первоначального копирования данных. По умолчанию PostgreSQL использует механизм с автоматическим копированием таблиц от публикации к подписке, основанный на моментальных снимках данных с применением MVCC.
Этот процесс осуществляется одной процедурой, которая одновременно делает снимок, переносит данные и запускает потоковую передачу изменений. Несмотря на удобство и простоту, подобный подход может быть неэффективен при работе с большими объёмами данных, особенно если таблицы содержат гигабайты информации. В этом случае использование однопоточного копирования накладывает значительные задержки, и задача может занять часы или даже дни. Хотя существует параметр max_sync_workers_per_subscription, позволяющий настроить параллелизм копирования, он не всегда способен существенно сократить время начальной синхронизации. Для контроля статуса копирования таблиц доступна системная таблица pg_subscription_rel, предоставляющая информацию о текущем состоянии каждой таблицы, включая стадии ожидания, синхронизации и полноценной потоковой репликации.
Режим "r" свидетельствует о завершении копирования и начале применения изменений, однако важно помнить, что при этом создавшаяся задержка в потоке изменений приводит к удержанию WAL-файлов на стороне издателя, что требует контроля и мониторинга с целью предотвращения переполнения дискового пространства. Для производственных систем, где надежность и производительность критичны, рекомендуется использовать ручную синхронизацию. Такой подход подразумевает создание логического слота репликации до или одновременно с точкой восстановления данных, чтобы обеспечить согласованность начальной копии с моментом начала репликации. Это особенно важно при использовании резервного копирования с Point-in-Time Recovery (PITR), позволяющего восстановить базу данных на определённый момент времени. Для больших систем и полнообъемных резервных копий оптимальным инструментом является pgBackRest, который позволяет заранее подготовить резервную копию и снизить временные затраты на начальную синхронизацию за счёт применения лишь последующих изменений, начиная с установленного LSN.
В случае необходимости работы с небольшими подмножествами таблиц можно использовать pg_dump с возможностью создания синхронизированного снимка с помощью pg_export_snapshot. Этот метод гарантирует согласованность данных в момент резервного копирования, однако для комплексных резервных стратегий он уступает инструментам уровня PITR. Мониторинг процесса логической репликации занимает не менее важное место в управлении потоками обновлений. Основным источником информации служит системный каталог pg_replication_slots, в котором отображается активность каждого слота, а также размер удерживаемых WAL-файлов. Значение флага активности указывает, используется ли слот в текущий момент.
Продолжительно неактивный слот может сигнализировать о проблемах с подписчиком или неправильной конфигурации репликации. Возрастающий размер неотправленных WAL-файлов предупреждает об отставании получателя и риске заполнения диска. В случае «зависших» слотов, связанных, например, с удалением подписчика без корректного удаления слота, необходимо вручную удалять слоты с помощью pg_drop_replication_slot. Для более детальной диагностики можно использовать представление pg_stat_replication, предоставляющее разнообразные показатели, включая задержку воспроизведения. Рекомендуется интегрировать данные мониторинга в системы визуализации и оповещений, например в Grafana, чтобы своевременно обнаруживать и устранять сбои.
Реальная эксплуатация логической репликации предполагает динамическое изменение репликируемых структур. Ежедневные операции создания и удаления таблиц требуют внесения соответствующих изменений в публикации. PostgreSQL предоставляет команды для добавления и удаления таблиц в публикациях, однако для того, чтобы подписчик узнал о таких изменениях, необходима операция обновления подписки. Она позволяет либо повторно синхронизировать данные, либо продолжить потоковое воспроизведение без копирования. Важно понимать, что, если добавить таблицу на стороне издателя без обновления подписки, изменения по этой таблице не будут применяться на стороне подписчика, несмотря на то, что логический поток будет обрабатывать информацию.
В ядре логической репликации лежит механизм логического декодирования. В том числе он реализован в плагинах, таких как pgoutput, который преобразует низкоуровневые записи WAL в более дружелюбные изменения строк таблиц с указанием схемы, имени таблицы, колонок и значений до и после изменений. Этот уровень абстракции делает возможным потоковую репликацию на уровне данных. Для отладки и ознакомления с внутренним устройством можно воспользоваться плагином test_decoding, который выводит изменения в читаемом виде, что существенно облегчает понимание последовательности операций и структуры транзакций. При этом очень важна корректная настройка параметра REPLICA IDENTITY для таблиц, так как от этого зависит полнота передаваемых данных.
При значении по умолчанию идентификация происходит по первичному ключу, что сокращает объём информации. Установка REPLICA IDENTITY FULL заставляет репликацию передавать полные строки как старые, так и новые данные для операций обновления и удаления, увеличивая нагрузку, но улучшая точность при отсутствии первичных ключей или в сложных сценариях. Важным аспектом, способствующим снижению лишней нагрузки на репликацию и улучшению безопасности, является возможность настройки публикации с ужесточенными ограничениями на уровне колонок и операций. Отключение ненужных полей позволяет исключить из реплики конфиденциальные данные и уменьшить трафик. Также можно выбрать, какие действия (вставка, обновление, удаление, обрезка) попадут в поток репликации.
Это особенно полезно при построении аналитических подсистем или агрегаторов, где важны лишь определённые типы событий. Безопасность репликации существенно зависит от правильного разграничения прав доступа. Роль пользователя, загружающего данные, должна быть ограничена минимумом необходимых разрешений: подключение к базе, использование схемы и право на чтение нужных таблиц и колонок. Построение доступа с опорой на модель наименьших привилегий предотвращает возможность утечки данных и снижает риски компрометации. PostgreSQL строго следует стандартной модели безопасности и интегрирует репликацию с разграничением доступа, учитывая настройки политик RLS.
Настройка прав для ролей с логической репликацией требует учёта всех уровней — от базовых прав до детального контроля над колонками и условиями выборки. Так называемые "репликационные" роли получают специальные права, позволяющие подключаться к слоту и производить репликацию без предоставления чрезмерных полномочий. Такой подход помогает организовать безопасные и управляемые среды, соответствующие корпоративным политикам и требованиям законодательства по защите данных. Углублённое понимание и грамотная настройка логической репликации в PostgreSQL открывает возможности по созданию масштабируемых, надежных и безопасных систем. Это не только сокращает время отклика и уменьшает нагрузку на основные базы, но и упрощает интеграцию с аналитическими и резервными подсистемами.
Современные инструменты мониторинга и контроля позволяют поддерживать высокое качество сервиса и эффективно реагировать на возникающие проблемы, а продуманная настройка безопасности предотвращает утечки и злоупотребления. Использование всех описанных возможностей открывает новые горизонты для эксплуатации PostgreSQL в самых требовательных сценариях, делая логическую репликацию неотъемлемой частью инфраструктуры любой компании, стремящейся к успеху и устойчивому развитию.