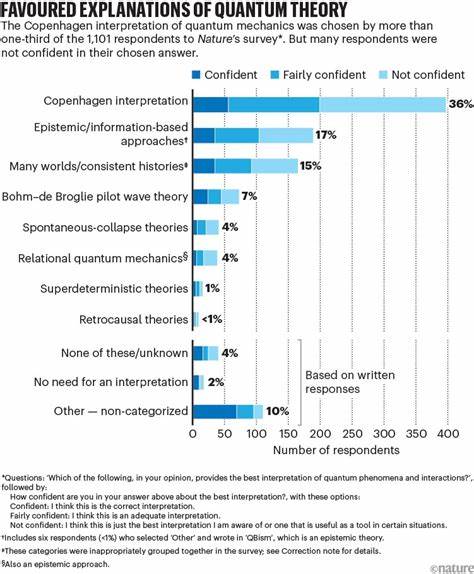
Ретросинтетическое планирование играет ключевую роль в области органического синтеза, позволяя химикам прогнозировать последовательность реакций, необходимых для создания сложных молекул из более простых исходных веществ. Эффективность и точность таких прогнозов существенно влияют на успех разработки новых веществ, лекарств и промышленных материалов. С быстрым развитием искусственного интеллекта и методов глубокого обучения этот процесс начал переживать качественный скачок, продвигаясь от традиционных шаблонных методов к более гибким и мощным технологиям. Одним из ярких представителей современных решений в области ретросинтетического планирования стала модель RSGPT — генеративная трансформерная архитектура, специально разработанная для решения задач предсказания реакции ретросинтеза на основе огромных данных и передовых алгоритмов машинного обучения. RSGPT, или Retro Synthesis Generative Pre-Trained Transformer, базируется на архитектуре LLaMA2, адаптированной для работы с химической информацией, представленной в виде строковых кодировок SMILES (Simplified Molecular Input Line Entry System).
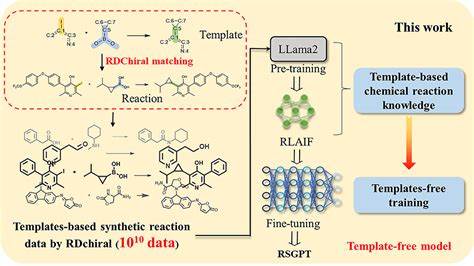
В отличие от традиционных шаблонных или полушаблонных методов, RSGPT действует как шаблонно-свободная модель, способная непосредственно генерировать последовательности реагентов исходя из заданного продукта, что упрощает и ускоряет процесс синтеза. Главной инновацией, которая обеспечила уникальные возможности RSGPT, стала идея масштабного предобучения модели на синтетических данных объемом в 10 миллиардов химических реакций, сгенерированных при помощи инструмента RDChiral. Эта программа позволяет извлекать и применять шаблоны реакций из обширных баз данных, таких как USPTO, и создавать новые реакционные пары, расширяющие химическое пространство возможных реакций. Подобный масштаб данных стал вполне сопоставим с объемами, которые используют современные крупные языковые модели, что позволило RSGPT эффективно учиться распознавать сложные взаимосвязи между продуктами, реагентами и химическими шаблонами. Процесс обучения RSGPT состоял из нескольких ключевых этапов.
Сначала проводилось предобучение на синтетических данных, где модель училась по четырем взаимодополняющим задачам, включая предсказание реагентов по продукту, продукции по реагентам, а также генерацию шаблонов и взаимных связей между ними. Далее применялся метод обучения с подкреплением, где модель получала обратную связь на основе проверки того, насколько правильно сгенерированные реагенты и шаблоны позволяют восстановить исходный продукт по правилам химической реакции. Такая система позволила эффективно подстраивать параметры модели, усиливая ее способность к осмысленному и точному предсказанию. Наконец, для повышения точности во вспомогательных задачах применялось дообучение на специализированных и более мелких наборах данных, таких как USPTO-50k, USPTO-MIT и USPTO-FULL. Преимущества модели RSGPT очевидны при сравнении с существующими решениями.
Во-первых, она достигает рекордного уровня точности предсказания реакций — Top-1 точность на USPTO-50k достигает 63,4%, что на несколько процентов превышает лучшие предыдущие модели, даже несмотря на то, что модель не использует шаблоны и атомное сопоставление при работе на этапе инференса. Во-вторых, благодаря предобучению на сгенерированных данных, модель способна выходить за рамки ограниченного набора реакций в реальных патентных данных, предлагая химические решения в расширенном химическом пространстве с уникальными молекулярными структурами и реакциями. Особое внимание заслуживает способность RSGPT к мультиступенчатому ретросинтетическому планированию. Хотя изначально модель обучалась на задачах одношагового анализа, она успешно демонстрирует возможность последовательного построения сложных синтетических маршрутов для таких фармацевтических препаратов, как осимертиниб, февуксостат и вонопразан. Это открывает новые горизонты в автоматизации разработки синтетических стратегий и значительным образом сокращает время поиска путей получения целевых соединений.
Технология генерации данных на основе RDChiral стала неотъемлемой частью успеха RSGPT. Используя обширные библиотеки фрагментов из баз PubChem, ChEMBL и Enamine, эти данные состоят из миллиардов реакций, покрывающих широкий ассортимент химических трансформаций. Анализ химического пространства с помощью методов визуализации, таких как TMAP, подтвердил, что сгенерированные данные не только повторяют известные реакции, но и расширяют границы возможных химических преобразований. При этом качество синтетических данных проверяли эксперты, подтверждая приемлемый уровень адекватности и реалистичности реакций. Обучение с подкреплением с искусственным интеллектом (RLAIF) стало важным этапом улучшения модели.
Вместо ресурсозатратного и трудоемкого обучения с человеческой обратной связью, RLAIF позволяет получать обучающие сигналы от AI-оценщиков, которые программно проверяют корректность предсказанных реакций на основе шаблонов. Этот метод не только повышает эффективность тренировки, но и способствует большей адаптивности модели при генерации химически обоснованных реакций. Для практического применения RSGPT предоставляет открытый доступ к весам модели и исходному коду, что способствует интеграции в научно-исследовательские и производственные процессы, ускоряя путь от идей к решениям. Кроме того, модель может быть дополнительно дообучена на специализированных наборах данных, что особенно актуально для областей с ограниченным доступом к большим объемам реакций, например, при синтезе природных продуктов или изучении биосинтетических путей. Среди существующих ограничений RSGPT стоит отметить необходимость улучшения генерации синтетических данных с учетом более сложных реакционных условий, а также работу с реакциями, в которых участвует больше трех реактантов.
Кроме того, на данный момент модель не учитывает параметры реакции, такие как растворители, температура и катализаторы, что ограничивает полноту прогноза. Решение этих проблем откроет еще более широкие возможности для создания точных и интерпретируемых синтетических путей. В целом, RSGPT становится значительным шагом вперед в области компьютерного планирования синтеза. Ее разработка демонстрирует, как современные методы машинного обучения, масштабные синтетические данные и обучение с подкреплением могут объединяться для решения сложных химических задач. Модель способствует не только повышению точности предсказаний, но и расширяет границы возможностей автоматизации в химической индустрии.
При дальнейшем развитии и интеграции RSGPT может значительно повлиять на процессы разработки новых лекарств, материалов и технологий производства, делая науку более эффективной и доступной. С учетом тенденций развития искусственного интеллекта и возрастающей роли больших данных, модели типа RSGPT открывают новую эру синтетической химии, где знания о реакции формируются не только экспертами, но и машинами, способными обрабатывать и создавать знания на суперчеловеческом уровне. Это направление обещает углубить понимание химических реакций, расширить их применение и значительно ускорить научно-технический прогресс в области молекулярного дизайна.