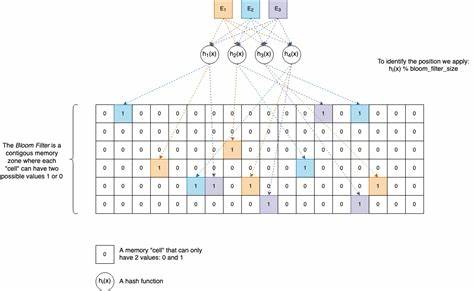
Фильтры Блума занимают особое место среди структур данных благодаря своей способности эффективно решать задачи поиска с ограничением по памяти. Они представляют собой вероятностный, компактный механизм проверки принадлежности элемента множеству. В то время как классические структуры, такие как хеш-таблицы, хранят сами данные, фильтры Блума лишь указывают на возможное присутствие или гарантированное отсутствие элемента. Этот инструмент отлично подходит для систем, где важно сэкономить пространство, а не всегда критична абсолютная точность. Основу фильтра Блума составляет битовый массив и несколько хеш-функций.
При добавлении в структуру нового элемента вычисляется набор значений хеш-функций, которые соответствуют индексам бит в массиве. Соответствующие биты устанавливаются в 1. Проверка наличия элемента заключается в повторном вычислении тех же хешей и проверке состояния соответствующих битов: если все они установлены в 1, фильтр отвечает, что элемент, скорее всего, присутствует; если хотя бы один бит равен 0, можно с уверенностью сказать, что элемент отсутствует. Главное преимущество фильтров Блума — небольшое потребление памяти вне зависимости от количества хранимых элементов. Однако за это приходится платить некоторой вероятностью ложноположительных срабатываний.
При выборе параметров фильтра важно учитывать компромисс между объемом памяти, числом хеш-функций и допустимой вероятностью ошибок. В реальных задачах этот баланс подбирается в зависимости от требований приложения. Разработка эффективной реализации фильтра Блума на C требует понимания особенностей работы с битовыми операциями. В языке C нет встроенного типа данных для отдельных битов, поэтому для хранения битового массива обычно используют массивы с элементами типа uint32_t или uint8_t, применяя побитовые сдвиги и маскировку для управления конкретными битами. Это позволяет компактно хранить состояние фильтра и быстро менять отдельные значения.
Расширяемость и производительность зависят от качества хеш-функций. Для простых приложений часто используют классические алгоритмы, такие как djb2 и sdbm, которые хорошо себя зарекомендовали в деле обработки строк. В более требовательных к качеству хеширования задачах применяют MurmurHash или другие современные функции. Удобной практикой является использование двух основных хешей и генерация дополнительного набора с помощью математических операций, что снижает накладные расходы на вычисления. При создании фильтра Блума в C обычно формируют структуру, которая содержит указатель на битовый массив, массив указателей на хеш-функции и служебные данные о размере и количестве функций.
Для управления памятью следуют стандартным подходам — выделение, обработка ошибок и освобождение ресурсов. Реализация методов добавления и проверки работает итеративно с набором хеш-функций, преобразуя вычисленное значение в позицию бита и устанавливая либо проверяя его. Простота интерфейса делает фильтр Блума привлекательным для встраивания в разнообразные системы — от кэширования до защиты от нежелательной информации. К примеру, в системах масштабируемой фильтрации спама или управления большими списками блокировок фильтры позволяют быстро отсеивать запросы, значительно снижая нагрузку. Значимым аспектом является выбор размера битового массива.
Если система слишком малы и содержит большое число элементов, уровень ложноположительных результатов резко растет, снижая эффективность механизма. Правильное изначальное планирование и понимание цели использования позволяют минимизировать риски. Важно следить, чтобы число элементов и размер фильтра поддерживались в адекватном соотношении. В дополнение к основной реализации можно расширить функционал за счет генерации хешей с помощью одной функции и множества ключей-переменных, что способствует уменьшению затрат на вычисления. Такой подход доказал свою эффективность и нашел широкое применение в практике.
Прикладываемые к статье примеры кода демонстрируют процесс создания и эксплуатации фильтра Блума, начиная с реализации битового массива и завершая функциями добавления и проверки элементов. На практике этот код легко интегрируется и адаптируется под специфические задачи. Фильтры Блума — отличный образец компромисса между скоростью, памятью и точностью. Они не заменяют полноценные структуры хранения данных, но играют важную роль в тех сценариях, где требования к ресурсам жесткие, а аварийные ситуации при ложных срабатываниях допустимы. В перспективе стоит отметить развитие альтернативных структур — например, фильтров Куку, которые позволяют работать с удалением элементов, сохраняя компактность и низкую ошибочность.
Однако фильтры Блума остаются классическим и практически востребованным решением, благодаря простоте и гибкости. Осваивая реализацию фильтров Блума на языке C, разработчик получает мощный инструмент, способный эффективно решать задачи поиска и фильтрации с минимальными затратами ресурсов. Такой опыт полезен не только для учебных проектов, но и для построения реальных, производительных систем, где важна скорость и минимальный объем используемой памяти.







