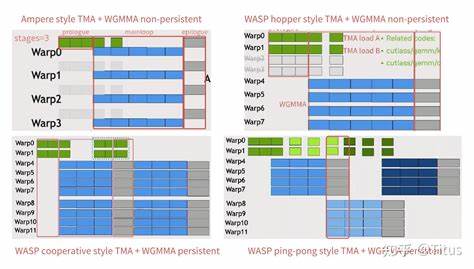
Архитектура Hopper представлена NVIDIA как новейший этап в развитии GPU с целью максимизации производительности и эффективности вычислений в области искусственного интеллекта и высокопроизводительных вычислений. В контексте оптимизации работы GPU основные методики организации вычислительных потоков серьезно влияют на итоговую производительность. Среди них выделяются warp-specialization и multi-stage — две концепции, применяемые для управления исполнением и координацией потоков на уровне warp'ов. Именно в архитектуре Hopper warp-specialization демонстрирует явные преимущества над multi-stage, которые обосновываются с точки зрения внутренней структуры, особенностей исполнения и оптимизации ресурсов. Первоначально нужно понять, что такое warp-specialization.
Это методика, при которой каждый warp — группа из 32 потоков — специализировано выполняет конкретную задачу или часть вашего вычислительного процесса. Благодаря такой специализации достигается высокая степень локализации и фокусировки ресурсов, минимизируются накладные расходы на синхронизацию и переключения контекста. Warp становится практически миниатюрным вычислительным блоком, сфокусированным на определенной функции, что способствует эффективному использованию локальных регистров и кеша. В то же время multi-stage предполагает более сложную, многоступенчатую обработку вычислений. В ней потоки проходят через несколько фаз, часто требующих обмена данными между разными стадиями или warps и синхронизации.
Хотя такой подход позволяет разбивать задачу на логические блоки, он порождает дополнительные накладные расходы на синхронизацию, управление конвейером данных и повышает вероятность простоя вычислительных ресурсов. Архитектура Hopper получила существенные изменения по сравнению с предыдущими поколениями, включая расширенные возможности по работе с памятью, улучшения в конвейеризации инструкций и поддержку новых видов параллелизма. Благодаря внедрению warp-specialization, реализованному на уровне железа, достигается снижение латентности и повышение эффективности работы с потоками. В частности, архитектура может более оптимально распределять ресурсы кэш-памяти и регистров, исходя из специфики задач конкретного warp’а. Одним из ключевых достоинств warp-specialization является возможность снизить конфликт за доступ к внутренним ресурсам GPU.
Поскольку полный warp централизованно обрабатывает однообразный тип операций, уменьшается необходимое число контекстных переключений, снижается нагрузка на диспетчер. Такая оптимизация напрямую отражается на пропускной способности и сокращении энергетических затрат, что становится особенно критично в приложениях ИИ, где используется массивная параллельность и высокие требования к вычислительной мощности. В отличие от multi-stage, где задача управлением и переходами между стадиями ложится на программное обеспечение, warp-specialization максимально вытягивает производительность из аппаратных возможностей. Например, в Hopper встроены специализированные механизмы отслеживания состояния warp’ов, оптимизированные для работы в таком режиме, что упрощает и ускоряет обработку сложных вычислительных графов, характерных для нейросетей. Еще один аспект, который выделяет warp-specialization — улучшенное управление энергопотреблением.
Оптимизация и упрощение инструкций внутри одного warp’а позволяют уменьшить количество переключений и пропусков, что автоматически ведет к более низкому энергопотреблению на единицу выполненной работы. Для дата-центров и облачных сервисов, применяющих GPU на базе Hopper, это означает сокращение расходов и повышение устойчивости вычислительной инфраструктуры. Кроме того, warp-specialization способствует более эффективной масштабируемости приложений. Поскольку каждый warp обрабатывает автономно заданный участок работы, масштабирование вычислений на несколько GPU или многокастомных систем переносится проще, чем в случае с многоступенчатой обработкой, где необходим глубокий контроль синхронизации и балансировки нагрузки. В контексте современных задач, связанных с глубоким обучением, симуляциями и обработкой больших данных, архитектура Hopper с использованием warp-specialization обеспечивает лучшие показатели производительности.