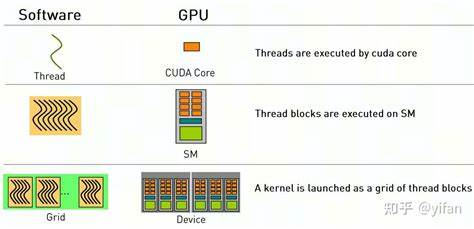
В последние годы технологии параллельных вычислений стремительно развиваются, и GPU стали неотъемлемой частью вычислительных систем благодаря своей способности выполнять огромное количество операций одновременно. Одной из самых популярных платформ для разработки параллельного кода на GPU является CUDA от NVIDIA. Несмотря на значительную документацию и доступность ресурсов, у новичков часто возникают вопросы, связанные с архитектурой и принципами работы CUDA. Один из таких вопросов звучит так: если Streaming Multiprocessor (SM) может одновременно обрабатывать только один WARP, значит ли это, что часть Streaming Processors (SP) внутри этого SM остаётся неактивной или простаивает? Чтобы ответить на этот вопрос, нужно глубже понять, как работает параллелизм на уровне CUDA, и разобраться в ключевых понятиях архитектуры GPU. Архитектура CUDA и её компоненты GPU, работающий по архитектуре CUDA, состоит из множества Streaming Multiprocessors, каждый из которых содержит набор вычислительных подразделений — Streaming Processors (SP) или CUDA cores.
Эти вычислительные ядра отвечают за выполнение инструкций, они аналогичны ALU в CPU, но рассчитаны на одновременную обработку большого числа потоков. SM играет роль управляющего блока, распределяя работу между ядрами и управляющими структурами. Параллельные вычисления в CUDA реализованы через крупные группы потоков, называемые блоками, которые дальше разбиваются на более мелкие группы — WARP. Один WARP состоит из 32 потоков, которые выполняются синхронно. То есть в момент времени все потоки WARP выполняют одну и ту же инструкцию над разными наборами данных.
Так как GPU ориентированы на SIMD-подобную модель (Single Instruction, Multiple Data), это позволяет добиться высокой производительности при обработке больших объемов однородных данных. Обработка одного WARP в SM и роль SP Важный момент заключается в том, что SM не «одновременно» обрабатывает только один WARP, а фактически имеет возможность переключаться между несколькими WARP'ами с высокой скоростью благодаря аппаратному мультипрограммированию. Это позволяет скрывать задержки, связанные с доступом к памяти или зависимостями между инструкциями, посредством переключения контекста между WARP'ами. Когда говорится, что SM обрабатывает один WARP за такт, это означает, что все 32 потока внутри этого WARP выполняют одну инструкцию одновременно. Компьютерные ядра (SP) соответствуют этим 32 потокам и в идеале все должны быть заняты обработкой инструкции.
Однако реальные архитектуры более сложны из-за следующих причин. Почему SP могут оставаться неактивными Во-первых, не все инструкции требуют участия всех потоков. Если в WARP есть ветвление (например, условные операторы), части потоков могут выполнять разные пути, и часть SP в этот момент простаивает, ожидая завершения другой ветви. Такая ситуация называется divergence, и она снижает эффективность использования вычислительных ресурсов. Во-вторых, задержки, связанные с памятью, играют ключевую роль.
Если WARP обращается к памяти и ожидает данные, то SM переключается на другой WARP, но во время ожидания часть SP может быть не задействована, особенно если количество активных WARP в SM недостаточно для полного скрытия задержек. Кроме того, некоторые инструкции сами по себе не нагружают все SP. Например, инструкции управления, операции с плавающей точкой высокой точности, или специализированные операции (например, тензорные ядра) могут использовать лишь часть блоков или даже отдельные специализированные компоненты. Архитектура современных SM подразумевает, что в каждом такте могут выполняться разные части инструкции на соответствующих SP. При этом эффективное использование ресурсов зависит не только от количества потоков, но и от характера вычислительной задачи, распределения данных и структуры программы.
Как оптимизировать загрузку SP Для максимизации производительности стоит стремиться к написанию кода, который минимизирует divergency, обеспечивает регулярный доступ к памяти для эффективного кеширования и позволяет SM иметь достаточное количество активных WARP для перекрытия задержек. Вместо того, чтобы думать, что SM может обрабатывать только один WARP, нужно рассматривать возможность параллельной работы нескольких WARP'ов и использование множества потоков для заполнения ресурсов вычислительных ядер. Умелое проектирование алгоритмов с учетом архитектуры CUDA позволяет снизить время простоя SP и повысить общую производительность приложения. Это связано с балансировкой вычислительной нагрузки, детальным анализом ветвлений и вниманием к специфике памяти GPU. Заключение Понимание того, что SM в CUDA действительно управляет одним WARP на исполнение инструкции в каждый момент, но при этом переключается между множеством WARP, помогает объяснить, почему отдельные SP могут находиться в состоянии ожидания или простоя.
Особенно это актуально в случае дивергенций потоков внутри WARP или ограничений, связанных с задержками памяти. Однако грамотное программирование и оптимизация алгоритмов могут значительно уменьшить эти эффекты, обеспечивая более полное использование всех вычислительных ресурсов GPU. CUDA — это мощный инструмент, и глубокое понимание его архитектуры помогает максимально эффективно использовать возможности современных видеокарт для параллельных вычислений.