В современном мире технологий редко что-то происходит мгновенно и без последствий, особенно когда речь идет о базах данных и продакшн-системах. Одним из таких примеров стала ситуация с нашей продакшн API, которую неожиданно вывел из строя простой в своей сути запрос к базе данных PostgreSQL — команда ALTER TABLE. История началась с того, что будучи занятым подготовкой презентации, я был вынужден проснуться посреди ночи из-за тревоги в системе мониторинга Google Cloud, сигнализирующей о превышении порога ошибок в базе данных. Первым естественным порывом было найти виновника среди последних изменений в инфраструктуре, и на первый взгляд подозрение упало на недавно развернутые реплики для чтения базы данных. В попытке быстро восстановить работоспособность, репликация была остановлена, а основной экземпляр базы рестартован.
Это временно помогло, однако с ростом нагрузки проблема вернулась. Самое удивительное заключалось в том, что метрики нагрузки на процессор, память и ввод-вывод не показывали аномалий, как и задержка репликации отсутствовала. Внимательное изучение ситуации выявило накопление размера бинарных логов на основном сервере после остановки репликации, что заставило меня вручную удалить репликационные слоты PostgreSQL и даже самих реплик в надежде устранить причину. Тем не менее корень проблемы оказался гораздо глубже и коварней. Постепенно анализ медленных и висящих запросов выявил паттерн — большое количество блокирующих инструкций SELECT FOR UPDATE, множества ALTER TABLE add column, а также вставок с условием ON CONFLICT DO NOTHING, все они пытались получить доступ к одной и той же таблице malware_analyses.
Именно эта таблица, используемая для хранения результатов сканирования OSS пакетов и постоянно обновляемая как фоновыми заданиями, так и API-запросами, стала эпицентром коллизии блокировок. Понимание происходящего требовало углубленного взгляда на архитектуру, в частности тех процессов, которые взаимодействовали с данной таблицей. Можно выделить три ключевых компонента: Submission API, обеспечивающий идемпотентное создание заданий для анализа пакетов; фоновый механизм обработки задач с использованием долгих транзакций и удержанием блокировок на строках; а также встроенный инструмент миграции схемы, который отвечает за применение изменений в структуре таблиц. Submission API выполнял свои операции в транзакциях для сохранения консистентности, включая проверку существования задачи и создание новой с гарантией отсутствия дубликатов за счет уникальных индексов. Фоновые воркеры держали блокировки строк, ожидая завершения длительных внешних вызовов, порой длительностью до нескольких минут.
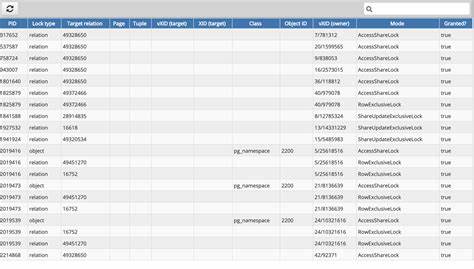
Однако одновременно с этими процессами была запущена миграция схемы, в ходе которой выполнялась команда ALTER TABLE для добавления двух новых колонок с индексами типа GIN. В PostgreSQL такое изменение требует экслюзивной блокировки AccessExclusiveLock, которая конфликтует со всеми прочими блокировками и не позволяет доступ к таблице до завершения операции. В результате по цепочке блокировок Background Jobs удерживали рядовые замки, что не позволило миграции установить запретительный AccessExclusiveLock. Новые запросы Submission API встали в очередь, ожидая освобождения таблицы, что привело к блокировке всех гошутин из приложений и полной остановке API. Именно это и стало причиной каскадного фиаско в продакшн-системе.
Такая ситуация — яркий пример того, что наличие даже поверхностно незначительных изменений, как ALTER TABLE с добавлением колонки, может вызвать системный коллапс, если не учитывать особенности работы блокировок в СУБД и взаимодействия с длительными транзакциями приложений. Переосмысление проблемы привело к выводу, что решения необходимо искать в изоляции блокировок. Длительные транзакции, особенно те, кто удерживает locks на таблицах с высокой нагрузкой, создают угрозу стабильности. Основная идея решения состояла в отделении механизмов синхронизации и сериализации от самой бизнес-логики, хранящейся в таблицах предметной области. Это было реализовано путем введения отдельной таблицы resource_locks, назначенной исключительно для управления блокировками по ресурсам с использованием строковых ключей.
Фоновые работы и сервисы начали использовать эту специализированную таблицу для получения и удержания блокировок, сводя к минимуму необходимость захватывать блокировки непосредственно на бизнес-таблицах. Такой подход позволил упростить схему миграций, снизив вероятность конфликтов с AccessExclusiveLock и устранив длительные блокировки на таблицах бизнес-логики. Реализованный паттерн позволил выполнять операции с сегрегированными локами, сохраняя при этом целостность данных и последовательность бизнес-процессов. Пользовательский код был пересмотрен таким образом, чтобы держать долгие операции вне транзакций с блокировками на критичных таблицах, а также обеспечить работу с общей таблицей блокировок, которая потенциально меняется чрезвычайно редко. Деплой изменений осложнялся необходимостью временной приостановки фоновых заданий с последующим ожиданием окончания активных транзакций, что позволило применить миграцию безопасно и без риска подвесить систему.
Эта история подчеркивает фундаментальный вызов работы с распределёнными системами и особенно с базами данных, вытекающий из теоремы CAP, когда попытка одновременно гарантировать согласованность и доступность приводит в сложных сценариях к неожиданным сбоям на продакшнах. Полученный опыт учит не только правильному планированию и исполнению миграций, но и проактивному подходу к архитектуре локов и транзакций, их изоляции для облегчения обслуживания и масштабирования систем. Кроме того, данный кейс демонстрирует, что системные инструменты вроде Google Cloud мониторинга и анализа запросов PostgreSQL являются незаменимыми при расследовании и поиске корня проблем. В конечном итоге, развёрнутое решение с выделенной таблицей resource_locks снизило риск блокировок и позволило команде продолжать развитие без опасений внезапных остановок продакшн API. Методы, основанные на изоляции синхронизации от бизнес-логики, могут служить ориентиром для разработчиков и инженеров по надежности, стремящихся минимизировать простои и повысить устойчивость приложений на PostgreSQL.
Этот опыт полезен для всех, кто работает с базами данных на высоконагруженных продуктах и желает понять тонкости внутренних блокировок и возможных ловушек, способных остановить работу целых сервисов. На пути к безопасной и эффективной работе с миграциями стоит учитывать все причины, включая длительные операции, уникальные индексы, и распределённые процессы, и применять проверенные практики, чтобы минимизировать влияние изменений на пользователей и бизнес.