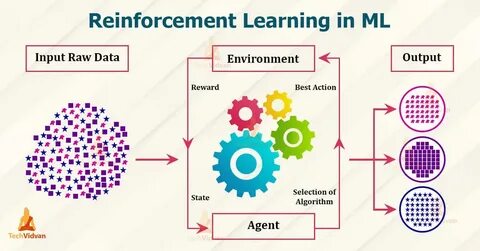
Обучение с подкреплением (Reinforcement Learning, RL) долгое время было одной из самых амбициозных и перспективных областей искусственного интеллекта, способной решать сложнейшие задачи, от автономного вождения до генерации контента. Однако сложности в настройке, обучении и интеграции моделей RL часто создавали серьезные барьеры для широкого внедрения таких методов. Появление RunRL, проекта из акселератора Y Combinator (пакет X25), меняет правила игры, предлагая Reinforcement Learning как услугу и делая продвинутые методы обучения простыми и доступными для компаний и исследователей любого уровня. RunRL предоставляет уникальную возможность обучать специализированные модели с подкреплением без необходимости глубоких знаний в области ML. Платформа предлагает интуитивно понятные инструменты для постановки задач, создания индивидуальных функций вознаграждения и последующей оптимизации моделей.
Пользователи определяют, что для них является положительным и отрицательным результатом, а RunRL берет на себя всю сложную работу по обучению и улучшению модели по заданным критериям. Особенность RunRL - поддержка интеграции с множеством популярных API-поставщиков, таких как OpenAI, Anthropic и LiteLLM. Это позволяет seamlessly встраивать оптимизированные модели в существующие рабочие процессы без кардинальной переделки инфраструктуры. Кроме того, разработчики получают доступ к мощным Python-пакетам, что упрощает процесс запуска экспериментов и мониторинга прогресса моделей в реальном времени. На фоне возросшего спроса на кастомные интеллектуальные агенты, способные эффективно выполнять специализированные задачи, RunRL выделяется возможностью обучения узкоспециализированных моделей, значительно превосходящих по качеству стандартные обобщенные решения.
Платформа уже продемонстрировала впечатляющие результаты, например, смогла обучить модель, опережающую Claude 3.7 при в 50 раз меньшей размерности, а также модель, способную эффективно использовать инструменты для выполнения сложных сценариев. RunRL ориентирован не только на бизнес пользователей, но и на исследователей. Возможность сразу начать обучение с минимальными временными затратами дает свободу быстро проверять гипотезы и экспериментировать с новыми методами RL. Встроенная статистика и детальный анализ позволяют отслеживать рост показателей и принимать обоснованные решения по корректировкам задач и критериев вознаграждения.
Особое внимание уделяется непрерывному улучшению моделей - агенты способны самостоятельно обучаться на основе внешних сигналов, что помогает компаниям создавать системы с постоянным повышением качества без дополнительного ручного вмешательства. Это становится особенно актуально для отраслей, где условия быстро меняются, а требования к точности и надежности - крайне высоки. Финансовая модель RunRL предлагает гибкость: разработчики могут оплачивать использование по узловым часам с возможностью масштабирования под нужды конкретного проекта. Корпоративные клиенты получают доступ к расширенным опциям - запуск инфраструктуры на сотнях и тысячах GPU, кастомные интеграции и поддержку со стороны экспертов. Такой подход делает RunRL привлекательным вариантом для компаний разных размеров и направлений.
Одной из ключевых задач, которую решает RunRL, является сокращение времени и ресурсов на обучение сложных моделей с подкреплением. Традиционные методы требуют от специалистов глубоких знаний, большого количества данных и мощных вычислительных мощностей. RunRL автоматизирует большую часть процессов, предоставляя высококачественные оптимизации с минимальными затратами. Особенно ярко платформа проявляет себя в таких сферах, как химия, разработка веб-агентов и генерация кода. Для химических моделей RL помогает ускорять процессы поиска новых соединений и оптимизации свойств веществ.
В области веб-агентов RunRL способствует улучшению интерактивности и эффективности взаимодействия с пользователями. Для генерации кода обучение с подкреплением позволяет создавать более точные и контекстно-зависимые программные решения. RunRL позиционирует себя как демократизатор обучения с подкреплением - инструмент, который делает сложные технологии доступными и понятными, позволяя широкому кругу специалистов максимально эффективно использовать потенциал искусственного интеллекта. Команда экспертов по RL оказывает поддержку в формулировке задач, разработке кастомных функций вознаграждения и интеграции результатов, что значительно повышает качество конечных продуктов пользователей. Акцент на простоту использования, гибкость, масштабируемость и поддержку делают RunRL перспективным выбором как для крупных корпораций, стремящихся к инновациям, так и для стартапов и научных лабораторий, желающих быстро внедрять новейшие методы RL.
Платформа постоянно развивается и совершенствуется, что открывает широкие возможности для новых кейсов использования и интеграций в разнообразные отрасли. Таким образом, RunRL не просто предлагает обучение с подкреплением как услугу, а создает экосистему, в которой современные алгоритмы становятся инструментом доступного и эффективного решения сложных задач для каждого. Благодаря этому подходу RL перестает быть уделом ограниченного числа специалистов и становится настоящим драйвером инноваций в индустрии искусственного интеллекта. .