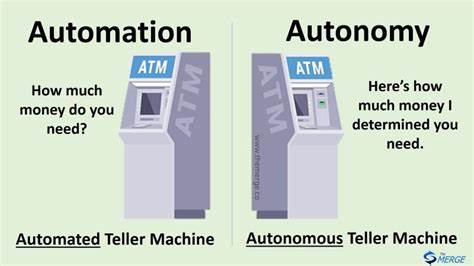
С развитием технологий искусственного интеллекта и появлением больших языковых моделей (LLM) многие разработчики и компании стремятся создавать всё более автономные и мощные системы, способные принимать решения и взаимодействовать с пользователями без постоянного вмешательства. Однако с ростом автономии таких программ возникает ряд сложных задач, связанных с непредсказуемым поведением моделей, ошибками и неправильным использованием инструментов. В связи с этим все активнее обсуждается концепция, известная как «Автономия на последнем месте» (Autonomy Last), которая предлагает альтернативный взгляд на процесс создания ИИ-приложений, способных работать более надежно и предсказуемо. Основная идея данной методики заключается в том, что программисты сначала максимально реализуют логику и управление на уровне традиционного кода, а уже затем добавляют элементы автономии, передавая сложные задачи на обработку большим языковым моделям. Такой подход помогает систематизировать взаимодействие компонентов, сократить количество случайных или неуправляемых решений и значительно упростить отладку и сопровождение.
Одной из ключевых проблем при использовании полностью автономных LLM-программ является их нестабильность при изменении моделей. Примером служит ситуация, когда одна версия модели может адекватно справляться с задачей, а другая начинает чрезмерно создавать памятные записи или выполнять ненужные действия. Это происходит из-за того, что автономные агенты внутри приложения принимают решения сами, используя инструменты и информацию, иногда отклоняясь от приветствуемого сценария. Стратегия «Автономия на последнем месте» помогает избежать таких ситуаций за счёт централизованного управления процессами, таких как поиск и создание памятных записей, вынесенных из-под контроля агента в более контролируемую программную логику. Такой контроль позволяет разработчикам грамотно определять моменты создания новых вспомогательных данных, а не полагаться на решение модели, что снижает зависимость от конкретной реализации и поведения LLM.
Пример успешной реализации данного подхода на практике — разработка чатбота с памятью по имени Elroy. Создатель сталкивался с традиционными проблемами, характерными для автономных решений: при смене модели менялось поведение приложения, что влияло на качество и корректность взаимодействия с пользователем. Реализовав логическую часть обработки памяти на уровне кода и лишь затем предоставляя модели ограниченный набор простых задач, он добился значительно более предсказуемой работы бота. При этом бот автоматически осуществляет поиск памятных записей с сообщениями, добавляя их в контекст для дальнейшей работы, а создание новых памяток происходит согласно фиксированному алгоритму — например, после обработки определённого количества сообщений. Такой метод помогает поддерживать баланс между гибкостью и контролем, избегая хаотичности.
Помимо повышения качества и надежности, подход «Автономия на последнем месте» способствует масштабируемости приложений. Сложность современных проектов требует чёткого разграничения зон ответственности между кодом и ИИ, что позволяет легче поддерживать продукт, оптимизировать его работу под различные модели и расширять функциональность без риска разрушить основную логику. В мире, где доступно множество языковых моделей с разной архитектурой и поведением, использование автономии строго по верхам управления значительно облегчает адаптацию продукта. Также стоит отметить, что данная стратегия помогает избежать частых ошибок, связанных с чрезмерным усложнением подсказок и контекста для модели, которые часто используют в попытках «заставить» ИИ работать иначе. Накопление больших и сложных подсказок не только увеличивает нагрузку на контекстные окна моделей, но и делает систему чувствительной к смене версии или даже «настроек» ИИ.
В итоге качество работы системы может колебаться, провоцируя ошибки или галлюцинации данных. В то время как с подходом «Автономия на последнем месте» такие процессы упрощаются и стандартизируются на уровне программной логики. Методика имеет свои ограничения и требует продуманной архитектуры приложения с разделением нагрузок. Не всякая задача подходит для жесткого контроля кода — некоторые сценарии требуют именно высокой степени автономии ИИ-системы. В таких случаях целесообразно использовать комбинированные подходы, тщательно выбирая зоны, где модель работает самостоятельно, а где действует код.