gRPC давно зарекомендовал себя как надёжная и высокопроизводительная платформа для межсервисного взаимодействия. Благодаря использованию протокола HTTP/2, gRPC обеспечивает мультиплексирование запросов и оптимизированные коммуникации между клиентами и серверами. Однако, несмотря на заявления о высокой производительности, реальная эксплуатация gRPC в условиях сетей с низкой задержкой выявила неожиданный клиентский узкий место, препятствующий достижению максимально возможной пропускной способности и низкой латентности. В современных распределённых системах, таких как базы данных и микросервисы, где важна скорость и масштабируемость, подобные проблемы могут привести к потерям в производительности и увеличению используемых ресурсов. В YDB, открытой распределённой SQL базе, активно применяется gRPC для реализации клиентских API.
Недавние внутренние тесты и нагрузочные эксперименты выявили один любопытный феномен. При уменьшении количества узлов в кластере не только ухудшалась способность нагрузочного генератора эффективно загружать систему, но и наблюдалось резкое повышение задержки на стороне клиента при одновременном наличии большого количества простаивающих ресурсов на сервере. Это неожиданное явление было связано именно с клиентским узким местом в gRPC, а не с сетевой инфраструктурой или серверной стороной. Чтобы лучше понять динамику и причины, специалисты YDB разработали микро-бенчмарк, позволяющий воспроизводить проблему и наглядно демонстрировать возможные решения. Основой анализа стало понимание структуры gRPC клиентов.
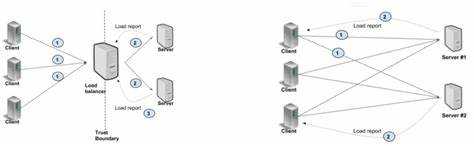
Каждый клиент использует один или несколько каналов (channels), где каждый канал управляет множеством RPC-потоков, соответствующих HTTP/2 stream. Неочевидно, но все каналы с одинаковыми параметрами по умолчанию разделяют один и тот же TCP-сокет, используя HTTP/2 для его мультиплексирования. Из-за этого появляется ограничение на число одновременных активных потоков внутри одной TCP-сессии — обычно 100 потоков, установленное как стандарт. При достижении этого лимита новые запросы начинают ставиться в очередь и ждут, пока активные RPC завершатся. На практике это ведёт к очередям именно на клиентской стороне, замедляя обработку запросов и повышая задержку.
Официальная документация gRPC предлагает два основных способа решения: создание отдельных каналов для участков с высокой нагрузкой либо использование пула каналов, каждый со своими уникальными параметрами, чтобы избежать их объединения в одну TCP-сессию. Однако, как показал опыт YDB, эти решения фактически представляют собой два этапа одного и того же исправления. В качестве эксперимента была создана простая microbenchmark-система на C++, которая моделировала ситуацию. Сервер реализован с использованием асинхронного API gRPC, распределяя рабочие потоки по нескольким completion queues для повышения параллелизма и снижения задержек. Клиент выполнял RPC-запросы в закрытом цикле с разным числом параллельных потоков, имитируя высоконагруженную среду.
Для тестирования использовалась выделенная аппаратная платформа с мощными многоядерными процессорами Intel Xeon и скоростной сетью 50 Гбит/с с минимальной задержкой. Результаты подтвердили, что при использовании одного TCP-соединения на все запросы рост количества параллельных запросов не приводит к линейному увеличению пропускной способности. При увеличении числа активных запросов в 10 раз, пропускная способность возросла лишь примерно в 3,7 раза, а при увеличении в 20 раз – только в 4 раза, при этом задержка росла практически пропорционально числу клиентов. Это говорит о том, что общая производительность ограничена именно клиентским узким местом, а не сетью или сервером. Анализ tcpdump и профилирование сетевых пакетов исключили проблемы с сетью: не было задержек, нет нигеля, окно TCP работало стабильно, а сервер отвечал быстро.
Таким образом, основная сложность была связана с очередностью обработки запросов внутри gRPC на клиенте. Еще один важный факт – даже попытки создать отдельные каналы для каждого рабочего потока без изменения параметров канала не решают проблему, так как каналы по умолчанию всё равно используют общую сессию TCP. Для того, чтобы добиться реального разделения TCP-соединений и, соответственно, разделения нагрузки, необходимо создавать каналы с различными аргументами конфигурации или же использовать специальный параметр GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL. Это позволяет каждому каналу работать на своём собственном подканале и TCP-соединении, что существенно снижает взаимное влияние и минимизирует очереди. В эксперименте с пулом каналов, где каждый канал имел уникальные параметры или активировался локальный пул, производительность возросла существенно.
Пропускная способность увеличилась почти в шестикратно по сравнению с одиночным соединением без потоковой передачи и в 4,5 раза при использовании стриминга. При этом рост задержки при увеличении количества подключений происходил значительно медленнее, что обеспечивает более предсказуемое и стабильное поведение даже при высоких нагрузках. Также стоит отметить, что при работе в сетях с высокой задержкой (например, около 5 миллисекунд), различия между подходами практически нивелировались. В таких условиях серверные и сетевые задержки доминировали и скрывали клиентский узкий место. Но сетевые инфраструктуры с минимальными задержками (например, внутри дата-центров и между узлами кластера) сталкиваются именно с этой проблемой, которую необходимо решать в первую очередь.
Результаты исследования имеют практическое значение для разработчиков систем, использующих gRPC в высоконагруженных и низкозадержанных средах. Разработчики могут оптимизировать клиентскую часть, учитывая топологию каналов и создавая отдельные уникальные каналы для каждого рабочего потока или операции, что приводит к снижению латентности и повышению общей пропускной способности. Подводя итог, важно понимать, что привычные рекомендации из официальной документации по работе с gRPC — например создавать отдельные каналы для разных областей нагрузки или использовать пул каналов — на самом деле представляют собой комплексное и взаимодополняющее решение. Вместо использования одного подхода, сочетание обоих методов с продуманным распределением нагрузки по каналам позволяет избежать клиентского узкого места и добиться эффективности, близкой к теоретическому максимуму. В то же время сфера оптимизации gRPC клиентов открыта для дальнейших исследований и улучшений.
Возможно, существуют другие более тонкие способы устранения проблем с очередями и контенжами, которые могли бы еще больше повысить производительность на уровне клиентской библиотеки или приложения. Авторы открытого микро-бенчмарка поощряют разработчиков и инженеров к сотрудничеству и обмену опытом, чтобы вместе двигать вперед качество инструментов межсервисного взаимодействия. Таким образом, понимание внутренней архитектуры gRPC каналов и TCP соединений, а также тщательное тестирование и настройка параметров клиента становятся ключевыми факторами для достижения максимально производительных и масштабируемых систем с использованием gRPC в средах с сегодня актуальными требованиями к низкой задержке и высокой пропускной способности.