В современном мире распределённых систем и микросервисов gRPC стал одним из самых популярных протоколов для организации взаимодействия между сервисами благодаря своей производительности, удобству и поддержке множества языков программирования. Однако, несмотря на все преимущества gRPC, разработчики часто сталкиваются с неожиданными проблемами, связанными с производительностью, особенно в высокоскоростных сетях с низкой задержкой. Одним из таких открытий стала выявленная командами YDB.tech проблема узкого места, ограничивающего пропускную способность и увеличивающего задержку на стороне gRPC-клиента. YDB — это распределённая SQL-база данных с поддержкой высокой доступности, масштабируемости и строгой консистентности.
Для взаимодействия с базой YDB использует gRPC, и в процессе нагрузочного тестирования команда разработчиков столкнулась с парадоксальной ситуацией: при уменьшении количества узлов кластера нагрузка на кластер падает, но при этом задержка на стороне клиента растёт, а вычислительные ресурсы остаются недозагруженными. Это означало, что узким местом была именно клиентская часть. Глубокий анализ показал, что gRPC в своей реализации использует HTTP/2 и мультиплексирует множество RPC-вызовов по ограниченному числу TCP-соединений. В частности, по умолчанию один gRPC-канал использует одно TCP-соединение и ограничение на количество параллельных потоков (streams) в HTTP/2 — по умолчанию 100 активных потоков. Когда эта граница достигается, новые запросы встают в очередь на стороне клиента, что приводит к росту задержек.
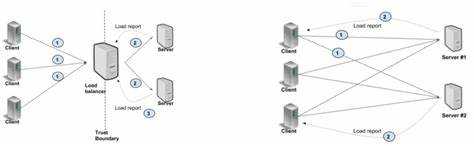
Разработчики YDB изучили две рекомендуемые официальной документацией gRPC практики: создание отдельных каналов для разных областей высокой нагрузки и использование пула каналов с разными настройками, чтобы избежать повторного использования одного TCP-соединения. Несмотря на то что вариант распределения нагрузки по нескольким каналам обычно предлагается как два самостоятельных решения, исследование показало, что на самом деле это два шага одного комплексного подхода. Для более детального анализа была разработана микро-бенчмарк программа, реализованная на C++ с использованием асинхронного API gRPC. Клиент выполнял параллельные работы с одним запросом в полёте (in-flight) для каждого рабочего потока на отдельном канале. Сервер и клиент запускались на отдельных машинах с мощными CPU и 50 Гбит/с сетью с минимальной задержкой порядка 40 микросекунд.
Выполненные тесты показали, что при увеличении количества параллельных запросов пропускная способность не масштабируется линейно. При увеличении количества клиентов в 10 раз прирост производительности составил лишь около 3,7 раза, при двадцатикратном увеличении — около 4. Причём задержка на стороне клиента росла практически линейно с числом параллельных запросов, оставаясь намного выше внутренней сетевой задержки. Подробный анализ трафика и поведения TCP-подключения подтвердил, что внутри пакетов не наблюдалось проблем с сетью: отсутствовали задержки из-за агрегации пакетов (Nagle), TCP-окно было оптимально настроено, не было ни потерь, ни задержек подтверждений. Главным источником лагов выявилась клиентская очередь внутри gRPC.
Попытки создать для каждого рабочего потока отдельный gRPC-канал, но с одинаковыми параметрами, показали, что несмотря на внешнее разделение, все каналы продолжают использовать одно TCP-соединение, следовательно, ограничение по количеству параллельных потоков HTTP/2 сохраняется. Благодаря же изменению параметров каналов так, чтобы они не совпадали (например, явно задавая уникальный аргумент channel number), удалось заставить клиент gRPC использовать несколько TCP-соединений и эффективно распределять нагрузку. Режим с несколькими TCP-соединениями обеспечил до 6-кратного увеличения пропускной способности для обычных RPC и около 4,5-кратного — для стриминговых RPC. При этом рост задержки при увеличении числа параллельных запросов был очень плавным и минимальным. Интересно отметить, что при тестах в сети с высокими задержками порядка 5 мс различия между одно- и многоканальным режимом сглаживались, поскольку сетевой фактор становился доминирующим и заслонял внутренние ограничения gRPC-клиента.
Это иллюстрирует, что выявленная проблема становится актуальной именно в быстрых сетях с низкой задержкой, что характерно для современных ЦОДов и кластеров. Для достижения максимально хорошей производительности и низкой задержки при использовании gRPC в условиях высокоскоростных каналов так, как видно из опыта YDB, необходимо отказаться от подхода с единственным gRPC-каналом для множества параллельных вызовов. Вместо этого рекомендуется создавать уникальные каналы для каждого рабочего потока или активировать опцию GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL. Это решение позволяет клиенту распределять соединения и запросы по нескольким TCP-подключениям, избегая внутренней конкуренции и очередей. Кроме того, использование taskset или равноценных средств закрепления потоков на заданных ядрах процессора и NUMA-узлах помогает минимизировать системные накладные расходы и повышает предсказуемость производительности.
Оптимальное распределение потоков для завершения очередей (completion queue workers) и коллбеков на сервере также играет роль для достижения высокой пропускной способности. На фоне представленной работы становится очевидно, что несмотря на репутацию gRPC как масштабируемой и производительной технологии, реализация и конфигурация клиента оказывают решающее влияние на итоговую производительность системы. Для систем с высокими требованиями к быстродействию и с низкой сетевой задержкой необходимо внимательно подходить к проектированию клиентской части и следить за тем, чтобы внутренние ограничения HTTP/2 и gRPC не становились «бутылочным горлышком». Проблемы, подобные описанной, на первый взгляд сложно выявить, поскольку они проявляются именно на очень быстрых сетях и при достаточно высоких нагрузках. Подобные исследования и публикации важны для широкой аудитории разработчиков и инженеров, работающих с распределёнными системами, поскольку позволяют понять глубинные особенности реализации популярных инструментов.
Стоит также отметить, что в экосистеме gRPC ведётся постоянная работа по оптимизации как серверных, так и клиентских частей. Возможно, в будущем появятся встроенные механизмы для автоматического распределения каналов и более гибкого управления потоками в HTTP/2. Однако уже сегодня опыт команд, подобных YDB, позволяет внедрять практические решения и добиваться значительного прироста производительности. В итоге, подход к проектированию gRPC-клиента должен учитывать не только количество параллельных RPC, но и особенности HTTP/2 мультиплексирования, ограничение числа потоков на соединение, а также возможности создания независимых TCP-соединений. Разработка микро-бенчмарков и внимательное профилирование системы в условиях, максимально приближённых к реальным, станут основой для принятия правильных инженерных решений.
Современные системы требуют от инженеров постоянного баланса между сложностью архитектуры и максимальной производительностью. Выявление и устранение подобных узких мест играет ключевую роль в создании высокоэффективных распределённых приложений, способных обрабатывать большие объёмы данных с минимальными задержками. Таким образом, опыт YDB демонстрирует, что понимание внутренних механизмов gRPC и грамотное использование его настроек на клиентской стороне являются необходимым шагом к построению быстрой и устойчивой инфраструктуры для современных распределённых систем.