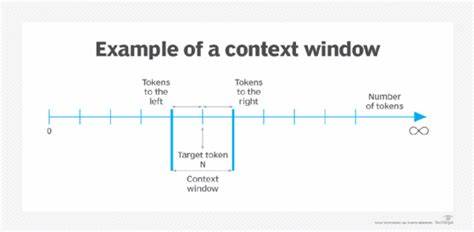
Современная индустрия искусственного интеллекта стремительно развивается, и одной из наиболее обсуждаемых тем является расширение контекстных окон языковых моделей. Последние достижения в области моделей, таких как GPT и Gemini, позволяют обрабатывать миллионы токенов в рамках одного запроса, что открывает широкие возможности для работы с объемными данными. Однако стоит ли рассматривать это как универсальный ключ к решению всех проблем, связанных с обработкой информации и поиском в AI? Ответ на этот вопрос ровно такой же сложный, как и сама экосистема искусственного интеллекта. Прежде всего, необходимо понять, что представляют собой контекстные окна. Речь идет о максимальном количестве текста, который языковая модель способна учесть в рамках одного запроса.
Чем больше контекстное окно, тем больше данных можно передать модели для анализа и последующего ответа. Это кажется очевидным преимуществом — например, суммаризация длинных документов или анализ больших объемов логов становится действительно проще и даже возможен впервые в таких масштабах. Тем не менее, практика показывает, что просто увеличивать объем обрабатываемой информации в одном запросе недостаточно и имеет ряд существенных ограничений. Одним из ключевых аспектов выступают затраты. Чем больше токенов вы передаете модели, тем больше ресурсов и вычислительной мощности потребуется для обработки запроса, а значит и выше стоимость.
В условиях, когда обработка миллиона токенов стоит несколько долларов, необходимость часто использовать такие большие контексты становится экономически невыгодной для многих приложений, особенно если речь идет о массовых сервисах, таких как техподдержка или генерация программного кода. Немаловажным фактором является и скорость обработки. Современные модели на основе механизма внимания вычисляют свой ответ с трудозатратностью, которая растет квадратично от длины входа. Другими словами, если количество токенов увеличивается в 20 или 100 раз, время вывода модели увеличится в 400-10 000 раз. Это приемлемо для задач пакетной обработки, где ответ может формироваться в течение минут или часов, но совершенно неприемлемо для интерактивных приложений, где пользователь ожидает быстрый и точный результат в реальном времени.
Еще одна сложность связана с природой данных, которые необходимо обработать. Например, при работе с огромными лог-файлами или телеметрией может потребоваться выделить тысячи релевантных фрагментов текста, чтобы сделать разумные выводы или помочь пользователю в решении проблемы. Простое подключение такого объема данных к модели без выдержанного этапа фильтрации приведет к необходимости захватывать ненужную информацию, что скажется на качестве ответа и эффективности системы. При усложнении задач, особенно в многоэтапных вычислительных системах, проблема еще более обостряется. Современные архитектуры включают множество вызовов языковой модели для одной задачи — иногда от 30 до 50 раз и более.
Если на каждом шаге передавать всю релевантную информацию без фильтрации, расходы и задержки станут критичными. Ведущие компании в области AI уже сегодня работают над агентными планировщиками и сложными системами, где рациональное использование контекста является ключевым элементом архитектуры. Качество выдачи и надежность результата тоже зависят от умения правильно выбирать информацию для передачи в контекст. Чем больше лишних данных, тем выше шанс, что модель запутается, предоставит противоречивую информацию или ошибется в выводах. Это особенно болезненно в случаях, когда нужно сравнить несколько похожих версий кода или найти уникальное решение в большом наборе данных.
В таких случаях неуместное расширение контекстного окна ухудшит качество ответа. Несмотря на все перечисленные ограничения, длинные контекстные окна открывают новые горизонты, прежде недоступные с традиционными моделями. Они позволяют анализировать большие документы целиком, делать глубокие суммаризации и работать с объемной текстовой или структурированной информацией на новом уровне. Такие возможности уже находят применение в отраслях с большими объемами данных — от анализа журналов событий и технической диагностики до обработки историй болезни пациентов. Однако ключевой посыл заключается в том, что даже в эпоху развивающихся масштабов контекстных окон ни одна модель не сможет полностью заменить умение эффективно искать и фильтровать данные.
Поиск релевантной информации становится неотъемлемой частью построения интеллектуальных систем, позволяя сократить объем передаваемого контекста и повысить качество результатов. Таким образом, грамотное сочетание расширенных контекстов и продвинутых методов поиска обеспечивает оптимальный баланс между точностью, скоростью и стоимостью. Взгляд в будущее показывает, что развитие AI тесно связано с внедрением сложных композитных систем и агентных архитектур, использующих многоэтапные вычисления и планирование. Именно здесь управляемое хранение, классизация и поиск информации создадут превосходство и позволят создавать действительно умные, адаптивные решения. В итоге, длинные контекстные окна — это значительный шаг вперед, открывающий новые возможности в масштабировании и глубине обработки данных.
Но они не являются панацеей, способной решить все проблемы, связанные с обработкой больших объемов информации. Ключ к успешной реализации AI-решений лежит в сбалансированном подходе, объединяющем мощь больших моделей и эффективные методы поиска и отбора данных. Только так можно создавать системы, которые работают быстро, эффективно и с минимальными затратами, принося реальную пользу бизнесу и конечным пользователям.