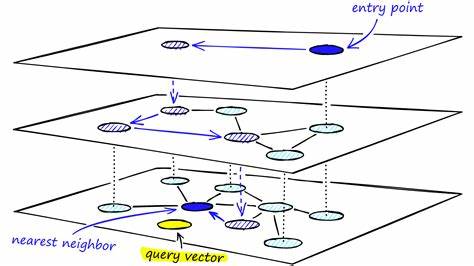
В современном мире обработка больших объемов данных и извлечение полезной информации становится задачей первостепенной важности. С ростом популярности машинного обучения и искусственного интеллекта увеличивается потребность в эффективных алгоритмах поиска ближайших соседей, особенно когда речь идет о векторных представлениях данных. Одной из наиболее перспективных и мощных технологий, решающих эту задачу, является Hierarchical Navigable Small World graph, или HNSW. В данном материале мы рассмотрим, что представляет собой HNSW как абстрактная структура данных, а также познакомимся с его применением в системе Redis Vector Sets, которая становится популярным решением для быстрого и масштабируемого поиска векторных данных. HNSW — это алгоритм, основанный на построении и навигации по графу, который стремится эффективно находить ближайшие соседние элементы в многомерном пространстве.
В отличие от традиционных методов, таких как дерево k-d или линейный поиск, HNSW предлагает более высокую скорость и точность, благодаря своей иерархической структуре и организации связей между точками в графе. Основной принцип работы HNSW заключается в создании слоев графа, где верхние уровни содержат меньшее количество узлов, а нижние — более детальную информацию о данных. При поиске алгоритм начинается с верхнего уровня итерируется вниз, сокращая пространство поиска и быстро приближаясь к искомым точкам. Такой подход существенно снижает вычислительные затраты и увеличивает производительность, что особенно важно при работе с большими объемами данных в реальном времени. Redis Vector Sets – это новый функционал внутри популярной базы данных Redis, адаптированный для хранения и поиска по векторным данным.
Внедрение HNSW в Redis позволяет использовать преимущества алгоритма в условиях быстрой обработки запросов и масштабируемости, характерных для Redis. Эта интеграция дает возможность разработчикам и компаниям создавать высокопроизводительные системы рекомендательных сервисов, поисковых движков и аналитических платформ без необходимости разрабатывать собственные решения с нуля. Важной особенностью использования HNSW в Redis является его настройка и гибкость. Пользователи могут настраивать параметры графа, такие как количество соседей и глубина уровней, под конкретные задачи и требования к точности и скорости поиска. Кроме того, Redis предлагает удобный синтаксис команд и интеграцию с большинством популярных языков программирования, что облегчает внедрение и масштабирование решений.
В сравнении с другими методами поиска ближайших соседей, такими как Annoy, Faiss или brute force, HNSW выделяется благодаря уникальному балансу между скоростью и точностью, а также своей адаптивности к изменяющимся данным. Это делает его оптимальным выбором для динамичных систем, где данные постоянно обновляются, а время отклика критично. Помимо высокой скорости выполнения, алгоритм также демонстрирует устойчивость к «проклятию размерности», которое является серьезным препятствием в задачах поиска в высокоразмерных пространствах. Графическая структура и иерархия позволяют значительно улучшить качество выборки близких точек. Кроме практических преимуществ, использование HNSW в Redis является примером того, как современные методы машинного обучения и теории графов интегрируются в инфраструктуру баз данных, повышая эффективность и возможности обработки информации.
Это открывает новые горизонты для развития интеллектуальных приложений и сервисов. Внедрение Redis Vector Sets с поддержкой HNSW значительно упрощает задачу для разработчиков, ведь теперь они могут воспользоваться преимуществами алгоритма в знакомой и мощной среде Redis. Такой подход позволяет сосредоточиться на бизнес-логике и пользовательском опыте, не тратя время на оптимизацию низкоуровневых механизмов поиска. Существует множество областей применения HNSW и Redis Vector Sets. В первую очередь это рекомендательные системы, где нужно быстро находить похожие по характеристикам объекты, будь то товары, фильмы или контент.
Также этот алгоритм эффективен в естественной обработке языка для задач сопоставления текста или поиска по семантическим признакам. Кроме того, HNSW находит применение в компьютерном зрении, биоинформатике и других областях, требующих анализа больших массивов данных с высокой точностью. Текущие тренды в развитии систем обработки данных демонстрируют, что интеграция высокоэффективных алгоритмов, таких как HNSW, с масштабируемыми технологиями хранения и управления, как Redis, будет только расти. Это связано с постоянным увеличением объемов данных и все более сложными требованиями к быстродействию и точности. В будущем можно прогнозировать появление новых улучшений и расширений HNSW, а также более тесную интеграцию с облачными платформами и распределенными системами.
В итоге HNSW как абстрактная структура данных и его реализация в Redis Vector Sets представляет собой важный этап в развитии технологий поиска и обработки векторных данных. Это мощный инструмент, объединяющий теоретические достижения и практическую применимость, который уже сегодня помогает создавать более умные, быстрые и точные системы. Для специалистов в области разработки и анализа данных понимание принципов работы и преимуществ HNSW откроет новые возможности для оптимизации проектов и достижения высоких результатов в различных направлениях. Таким образом, глубокое освоение алгоритма и его возможностей в составе Redis Vector Sets позволит не только улучшить качество и скорость обработки данных, но и значительно расширить функциональные возможности современных информационных систем.