В последние годы большие языковые модели (LLM), такие как GPT, LLaMA и PaLM, произвели революцию в области обработки естественного языка. Их способность понимать и генерировать текст позволяет применять их в самых разнообразных сферах — от машинного перевода до создания контента и интеллектуального анализа данных. Несмотря на всю мощь этих моделей, в реальных приложениях часто требуется адаптировать их под узкоспециализированные задачи или домены, что связано с необходимостью дообучения модели. Полное дообучение всех параметров больших моделей, имеющих сотни миллионов или даже миллиарды параметров, является дорогостоящим и затратным по времени процессом, требующим мощных вычислительных ресурсов. Здесь на помощь приходит метод Low-Rank Adaptation, более известный как LoRA, который позволяет эффективно подстраивать огромные модели, обучая лишь небольшое количество параметров, сохраняя всю насыщенность и функциональность изначальной модели.
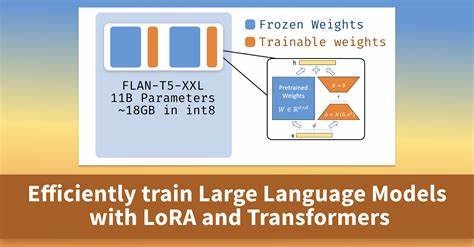
Дообучение больших языковых моделей традиционно предполагает обновление всех весов модели, что требует значительных вычислительных затрат и риска «катастрофического забвения» — потери ранее усвоенных знаний. В этом контексте LoRA предлагает уникальный компромисс, позволяющий обновлять лишь низкоразмерные представления весов без модификации основной структуры. Эта стратегия базируется на предположении, что необходимые изменения весов при адаптации модели лежат в подпространстве низкой размерности. Таким образом, модель обучается новым навыкам, не теряя при этом изначальной информации. Основы LoRA заключаются во введении двух малых обучаемых матриц низкого ранга в ключевые слои трансформера, чаще всего — слои внимания.
Вместо модификации всей матрицы весов W0, LoRA добавляет к ней произведение матриц A и B, где A и B имеют значительно меньшие размеры по сравнению с W0. Это сильно сокращает количество обновляемых параметров, повышая эффективность обучения и снижая требования к памяти и процессорной мощности. Одним из важных преимуществ LoRA является возможность выполнять дообучение на ограниченных наборах данных, что особенно ценно при работе с узкоспециализированными сферами, где сбор больших объемов размеченных данных затруднен или невозможен. При этом сохранение неизменной основной части модели помогает избежать переобучения и ухудшения общей производительности. Чтобы проиллюстрировать преимущества LoRA, рассмотрим наглядный пример с использованием большого языкового модели LLaMA 3.
2-1B-Instruct и набора данных о покемонах. Изначально, используя подход промпт-инжиниринга, модель при попытке предсказать тип покемона по его имени демонстрировала точность около 17,5%. Это свидетельствует о том, что без дообучения модель слабо справляется с задачами, выходящими за рамки её предобучения. Полное дообучение позволяет повысить точность, однако сопряжено с серьёзными ресурсными издержками и риском утраты ранее приобретённых знаний. При полном дообучении, если обновлять все параметры модели на небольшом количестве примеров, возникает эффект «забывания» прежних способностей — модель начинает выдавать однотипные ответы на разные входные данные, что снижает её универсальность.
С LoRA же достигается баланс: благодаря обучению лишь малой части параметров удаётся значительно улучшить точность, в нашем примере — до 67,21%, без риска катастрофического забвения. Такой подход позволяет адаптировать модели с минимальной потерей общей функциональности и при значительно меньших вычислительных затратах. Для работы с LoRA существует развитая экосистема инструментов. В частности, библиотека PEFT от Hugging Face предоставляет удобные средства для интеграции LoRA-адаптеров в трансформеры и управления обучением. Конфигурационные параметры LoRA, такие как ранг матриц (r), коэффициент масштабирования (lora_alpha) и вероятность дропаута (lora_dropout), позволяют гибко настраивать процесс дообучения под конкретные задачи.
Например, меньший ранг снижает размер обучаемых параметров, что полезно при ограниченных ресурсах, а коэффициент масштабирования влияет на силу обновлений весов. Первый шаг при использовании LoRA — загрузка предобученной языковой модели и токенизатора. Токенизация играет ключевую роль: преобразование текста в числовые представления, понятные модели, обеспечивая корректную обработку неоднородных и сложных языковых конструкций. Оптимальным считается использование того же токенизатора, с которым модель была изначально обучена — это обеспечивает максимальную совместимость и качество результатов. Подготовка данных под LoRA включает создание специализированных промптов, имитирующих конечную задачу.
В случае с покемонами, в систему подаётся сообщение с названием покемона, а модель должна выдать его тип. При этом учитывается, что покемоны могут иметь один или два типа, что отражается в ответах модели. Обработка данных осуществляется с маскированием токенов запроса в целях расчёта ошибки только на выходных токенах, что улучшает качество обучения. Обучение проводится с помощью класса Trainer из transformers с параметрами, позволяющими эффективно контролировать размеры батчей, скорость обучения, количество эпох и стратегии логирования. Такой подход упрощает настройку и наблюдение за процессом обучения, снижая вероятность ошибок.
После дообучения LoRA-адаптеры можно сохранять и переиспользовать, что упрощает распространение специализированных моделей без необходимости распространять полный объём исходных весов модели. Это особенно важно для коммерческих и исследовательских проектов, где размеры моделей и скорость развертывания играют ключевую роль. Кроме того, LoRA отлично сочетается с современными методами токенизации и генерации текста. Гибкое управление специальными токенами, такими как начало и конец последовательности, а также токены заполнения, позволяет создавать более точные и контекстно осмысленные ответы — важный аспект при внедрении LLM в реальные продукты. Подытоживая, LoRA представляет собой прорыв в области адаптации больших языковых моделей.