В эпоху цифровой трансформации и облачных технологий вопросы хранения и обработки данных приобретают все большую важность. Одним из многообещающих проектов, претендующих на роль единого стандарта для аналитических данных, стал формат Iceberg. Его концепция – создать единую таблицу и формат метаданных, которые позволят избавиться от зависимости от конкретных движков баз данных. Впервые идея кажется невероятно привлекательной, но глубокий анализ спецификации Iceberg выявляет серьезные недостатки, которые могут привести к повторению ошибок, допущенных в подобных системах в прошлом. История стандартизации и взаимодействия с данными далеко не нова.
В конце 1980-х годов компьютерная индустрия столкнулась с хаосом в вопросах кодировок символов. Каждая операционная система использовала собственные стандарты — DOS-кодовые страницы в Windows, ASCII и ISO-8859 в Unix, EBCDIC на мейнфреймах, MacRoman в MacOS. Все это приводило к сложностям совместного использования информации. Лишь с появлением и распространением UTF-8 удалось объединить разные системы и облегчить обмен данными. Однако и сегодня, несмотря на накопленный опыт, мы наблюдаем изобретение новых форматов, призванных заменить уже имеющиеся, что свидетельствует о сложностях в достижении универсальности.
Помимо форматов данных, значительную проблему представляли файловые системы. Несмотря на обилие разных решений — FAT в Windows, FFS в Unix, MFS и HFS у MacOS — все они строились на единой схеме: иерархии каталогов и файлов с базовым набором операций. Однако отсутствовал универсальный стандарт, полностью реализуемый всеми производителями. В результате каждый производитель по-своему решал задачи организации и доступа к данным. Базы данных же апеллируют к совершенно иной абстракции — строкам, отражающим измерения реального мира, а не файлам.
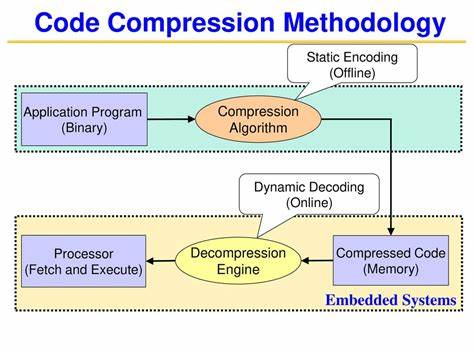
При этом физическая работа с данными ведется на уровне блоков фиксированного размера, кратных степеням двойки, что соответствует внутренней организации дисков. Такая рассогласованность требует специальных алгоритмов для оптимизации операций чтения и записи, чтобы минимизировать нагрузку и сохранить производительность. Фрагментация является еще одним важнейшим аспектом, влияющим на эксплуатационные характеристики систем хранения. При удалении или замене данных необходимо освобождать занятую ими память, что может происходить как синхронно, так и асинхронно, с различным влиянием на производительность. Накопление фрагментов данных неизбежно ведет к деградации скорости работы систем.
Одной из ключевых проблем традиционных файловых систем является организация параллельного доступа. Обеспечение согласованности при одновременном чтении и записи требует механизмов блокировок и транзакций, которые на уровне файловой системы часто либо отсутствуют, либо имеют слишком грубую детализацию. Базы данных умело используют в памяти снимки (snapshot) данных и механизмы блокировок с тонкой настройкой для повышения параллелизма и уменьшения конфликтов. Еще одной важной темой является атомарность операций. Совмещенное изменение нескольких файлов с гарантией, что изменения будут либо выполнены все, либо не выполнены вовсе, традиционными файловыми системами почти не поддерживается.
Напротив, базы данных давно разработали устойчивые алгоритмы для решения этой задачи — от классических транзакций до современных техник восстановления. С появлением облачных технологий ситуация обострилась с появлением объектных хранилищ. Объектное хранение, основанное на HTTP-интерфейсах, стало доминирующим в облаке, но при этом принесло новые вызовы. Несмотря на широкое распространение и простоту масштабирования, объектные хранилища имеют большое количество ограничений — повышенную латентность, сложности с обновлением мелких фрагментов данных, отсутствие эффективных механизмов блокировок и атомарных операций. Возникает логичный вопрос: зачем индустрия отказалась от отлаженных блоковых устройств с файловыми системами в пользу объектных хранилищ? Среди причин называют экономические мотивы крупных поставщиков облачных услуг, желание увеличить маржинальность и привязать клиентов к собственным экосистемам, а также упрощение инфраструктуры с их стороны.
Однако эти преимущества облачных вендоров приходится оплачивать сложностью разработки и эксплуатации клиентских приложений, которые теперь несут ответственность за все нюансы взаимодействия с хранилищем. Исторически сложилось так, что базы данных уже давно решили проблемы управления пространством, оптимизации доступа и защиты данных от повреждений. Возможно, именно поэтому Oracle, Microsoft и другие крупные игроки смогли закрыть рынок на долгие годы, создавая собственные экосистемы, трудно совместимые с конкурентами. В 1990-х и 2000-х годах, несмотря на появление стандартных протоколов, таких как ODBC, JDBC и ADO.NET, подлинной независимости от конкретных баз данных добиться не удавалось из-за их закрытых и проприетарных форматов хранения.
Начало века ознаменовалось расцветом систем хранения и обработки аналитических данных — Data Warehousing. Появились архитектурные подходы к централизации данных и их аналитике, однако они часто усиливали проблему зависимости от конкретных поставщиков, с тяжелыми последствиями для заказчиков. В конце 2000-х и в 2010-х на горизонте возникает облако. Оно меняет правила игры, предоставляя новые возможности, но одновременно создавая новые сложности. В частности, объектное хранилище становится основой для современных аналитических платформ, таких как BigQuery, RedShift, Snowflake и DataBricks, применяющих стратегию «эпhemeral storage on top of Object Storage», то есть временного быстрого хранилища поверх объектного слоя.
Еще одним важным достижением современности стало появление открытого формата Parquet, оптимизированного для аналитических задач. Это помогло существенно унифицировать представление столбцовых данных, облегчив обмен и совместное использование информации между разными платформами. При этом хранение и управление метаданными — крайне тонкая и важная проблема. Метаданные, хоть и занимают относительно небольшой объем по сравнению с основными данными, критически важны для обеспечения быстрого доступа, масштабируемости, предсказуемой производительности и транзакционной целостности. Метаданные должны быть легко индексируемы и способны выдерживать поток частых изменений без деградации производительности.
Традиционные объектные хранилища с их ограниченной функциональностью и высокой латентностью плохо подходят для решения задач, связанных с метаданными. Логично предположить, что требуется специализированное решение или как минимум глубокая переработка концепции, чтобы достичь необходимого уровня надежности и эффективности. В такой ситуации открытые базы данных, в частности PostgreSQL, начинают играть новую роль. Прежде считавшийся «игрушкой», он доказал свою зрелость и надежность, став равноценной альтернативой проприетарным решениям, при этом сохраняя полный контроль клиента над его данными без риска блокировки. Подводя итоги, можно выделить несколько важных уроков из истории, связанных с современными системами хранения данных и спецификацией Iceberg.
Во-первых, блокировка на любом уровне стека технологии является вредной и приводит к зависимости от конкретных поставщиков. Во-вторых, объектное хранилище, хоть и широко распространено и обладает некоторыми удобствами, по своей сути является технически ограниченным и далеко от идеального решения. В-третьих, проблемы управления пространством и метаданными давно и качественно решены в рамках классических СУБД, и именно эти решения служат надежной основой для построения систем нового поколения. Формат Parquet доказал свою пригодность в аналитических задачах, но проблема управления метаданными все еще остается сложной. В итоге, по мнению многих экспертов, Iceberg как спецификация в текущем виде не способен стать универсальным решением метаданных, что влечет за собой риски повторения исторических ошибок.
Понимание этих исторических и технических аспектов крайне важно для разработки и выбора будущих решений по хранению и обработке больших данных. Оно позволит избежать типичных ловушек и направит усилия на создание по-настоящему эффективных и открытых систем, соответствующих требованиям динамически развивающегося цифрового мира.