Современный мир доставки и онлайн-сервисов стремительно развивается, и вместе с ростом количества клиентов и пользователей увеличивается объем запросов к чат-ботам, которые обеспечивают первую линию поддержки. В условиях динамичных изменений в продуктах, услугах и политиках компаний традиционные подходы к обновлению базы знаний оказываются слишком медленными и трудозатратными. Поэтому компании вынуждены искать более эффективные и масштабируемые решения для улучшения качества и точности ответов чат-ботов. Одним из таких современных решений является использование больших языковых моделей (LLM) в сочетании с анализом пользовательского контента (UGC). Благодаря этому можно автоматически выявлять самые важные пробелы в базе знаний и создавать первые черновики статей в рекордно короткие сроки.
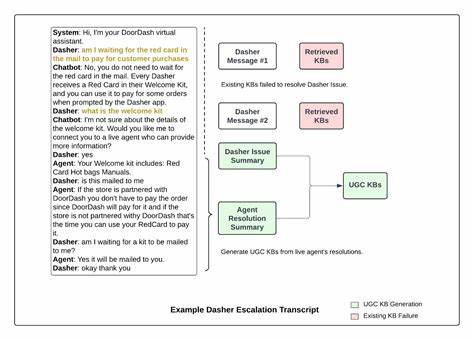
В основе подхода лежит обработка огромного количества анонимизированных транскриптов разговоров между пользователями и чат-ботом, особенно тех, что были перенаправлены на живых операторов. Это позволяет фокусироваться на наиболее сложных и проблемных вопросах, где бот не справился с задачей. Использование алгоритмов кластеризации помогает группировать схожие обращения, выявляя отдельные темы и проблемы, которые требуют улучшения базы знаний. Путём оценки частоты и серьёзности каждой кластеры создаётся приоритетный список задач по созданию новых или улучшению существующих ответов и инструкций. Для кластеризации применяются современные модели эмбеддингов, которые эффективно оценивают семантическое сходство текстов.
Каждое сообщение преобразуется в векторное представление, и схожие обращения объединяются, если косинусное сходство превышает определённый порог. Этот процесс требует тонкой настройки, поскольку слишком высокий порог приведёт к созданию множества мелких кластеров, а слишком низкий - к объединению разнородных тем. После автоматической группировки часть кластеров дополнительно проверяется и корректируется вручную, чтобы исключить дублирование и максимально точно определить суть каждой проблемы. Следующим этапом является работа самой большой языковой модели с выявленными темами. Она выполняет две важные функции - классифицирует каждую проблему как либо решаемую с помощью конкретных действий и политик, либо как информационный запрос, отвечающий на часто задаваемые вопросы.
Этот процесс помогает определить, где именно нужно создавать новые статьи базы знаний, а где - запускать автоматизированные процедуры решения проблем для пользователей. Для информационных запросов LLM создаёт черновики статей, используя не только описание проблемы, но и примеры решений от живых операторов. Это позволяет создавать точные, понятные и полезные инструкции, которые уже прошли предварительную подготовку и готовы к экспертной проверке. Важно отметить роль человека в этом процессе, несмотря на высокую автоматизацию. Контент-специалисты и операционные партнёры тщательно проверяют сгенерированные статьи, оценивая соответствие политическим нормам, корректность информации и подходящий стиль изложения.
Часто внутри одной темы встречаются различные варианты решения, зависящие от типа заказа, статуса доставки или временных исключений. Специалисты вносят необходимые правки, создавая дифференцированные версии материалов или добавляя разъяснения для корректной работы чат-бота уже на стадии взаимодействия с пользователем. Для повышения качества и полноты создаваемого контента была увеличена выборка транскриптов, а также уточнены инструкции для модели. Совершенствовались промты - специальные подсказки, которые регулируют логику и структуру создаваемых ответов. Благодаря этому удалось значительно снизить количество неопределённостей и пропущенной логики, сократив время на редактирование с нескольких дней до нескольких минут.
Кроме того, вся история изменений фиксируется и используется для обучения и улучшения следующих версий модели. Особое внимание уделяется технологии Retrieval-Augmented Generation (RAG), позволяющей чат-боту эффективно использовать созданные базы знаний во время реального общения с пользователями. Для этого статьи переводятся в векторные представления и сохраняются в специализированных векторных базах данных. При поступлении запроса модель извлекает наиболее релевантный контент, учитывая историю диалога и текущий контекст, что позволяет гарантировать точность и актуальность ответов. Для обеспечения стабильности и высокого качества системы необходимо соблюдение единых стандартов в подготовке данных.
Таким образом, модели, которые используются для создания и обновления базы знаний, должны быть максимально совместимы с теми, что работают в чат-боте. Использование одинаковых алгоритмов эмбеддинга и схожих промтов для суммирования проблем позволяет уменьшить вероятность несоответствия и повысить точность сопоставления запросов с нужной статьёй. В практике DoorDash была выбрана стратегия встраивания векторных представлений только той части статьи, которая содержит краткое описание проблемы пользователя, а не всего текста материала. Это минимизирует шум и повышает точность поиска соответствующего решения. Чат-бот получает пользовательский запрос, преобразует его в эмбеддинг и ищет максимально похожий в базе, после чего выдаёт соответствующий релевантный ответ.
Результаты применения данной технологии впечатляют. По результатам оффлайн-экспериментов с использованием LLM-жюри и онлайн A/B тестирований, удалось заметно повысить релевантность предлагаемых материалов и снизить уровень эскалаций сложных запросов на обслуживание живыми агентами. Так, в наиболее часто возникающих проблемных кластерах количество переходов на оператора сократилось с 78% в контрольной группе до 43% в тестовой. Более 70% обращений, обработанных чат-ботом, содержат только пользовательский сгенерированный контент, что свидетельствует о значительном закрытии критически важных пробелов в знаниях. Такая интеграция искусственного интеллекта и пользовательских данных меняет подходы к поддержке клиентов, делая её более умной, быстрой и точной.
Освобождение экспертов от необходимости ручного анализа огромных массивов текстов позволяет концентрироваться на самых сложных случаях и улучшать качество обслуживания. При этом качество ответов не страдает, а даже значительно растёт, создавая положительный опыт взаимодействия для пользователей. DoorDash не останавливается на достигнутом. Продолжаются эксперименты с использованием персонализированных данных, учитывающих статус заказа, уникальные особенности клиентов и их историю взаимодействия. Такой подход поможет создавать не просто универсальные инструкции, а динамически адаптированные решения, максимально подкреплённые конкретным контекстом, что ещё больше повысит удовлетворённость пользователей и качество работы чат-ботов.
В итоге описанный опыт показывает, что масштабируемое использование больших языковых моделей и кластеризации пользовательских данных - это эффективный путь к созданию современных систем поддержки, способных быстро адаптироваться к изменениям, работать с огромным количеством данных и обеспечивать высокое качество взаимодействия. Компании, стремящиеся к инновациям и улучшению клиентского сервиса, могут взять на вооружение эти методы, чтобы повышать эффективность своих чат-ботов и добиваться выдающихся результатов. .