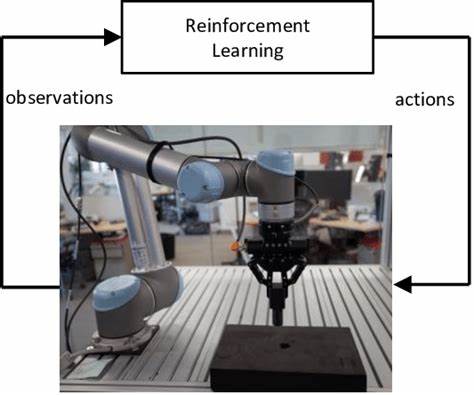
Современное развитие робототехники достигло такого уровня, при котором выполнение очень точных и деликатных задач стало реальностью благодаря синергии с передовыми методами искусственного интеллекта. Одной из ключевых задач, которые давно привлекают внимание исследователей и инженеров, является классическая проблема вкладывания штыря в отверстие — peg-in-hole. Эта задача требует высокой точности позиционирования и аккуратности, чтобы избежать повреждения деталей при сборке. В последние годы внедрение глубокого обучения с подкреплением (Deep Reinforcement Learning, DRL) существенно расширило возможности автоматизации подобных задач. В частности, симуляция и обучение реального робота UR5 выполнять peg-in-hole задачу с помощью визуальной обратной связи на основе изображений с камеры показали впечатляющие результаты.
Основой успешного применения DRL в данной области стала высокоточная симуляция с использованием среды PyBullet и Gymnasium, что позволило создать интерактивный и удобный для обучения агент в полностью виртуальной среде. В основе решения стоит роботический манипулятор UR5, оборудованный захватом с штырем и визуальной системой. Камера установлена непосредственно на «конце руки», что обеспечивает eye-in-hand вид — взгляд робота со своей собственной точки зрения. Снимки представляют собой монохромные изображения разрешением 100 на 100 пикселей, что позволяет значительно уменьшить размер входных данных для алгоритмов без существенной потери визуальной информации. Такой подход к восприятию значительно облегчает задачу визуального сервоуправления.
Среди используемых алгоритмов глубокого обучения с подкреплением особое внимание уделялось Soft Actor-Critic (SAC), который продемонстрировал быстрое обучение, стабильную работу и значительно лучший итоговый результат по сравнению с другими популярными методами, такими как Proximal Policy Optimization (PPO) и Advantage Actor-Critic (A2C). SAC пришёл к успеху с коэффициентом успешных вставок штыря в отверстие около 95.6% после 250 тысяч обучающих шагов — что по масштабам можно считать отличным достижением для задачи с непрерывным управлением и визуальной обратной связью. Основное преимущество SAC заключается в его устойчивости к шумам и способностях рассматривать непрерывное действие в пространстве мелких смещений по осям X, Y и Z, что именно требуется для аккуратного позиционирования детали по отношению к отверстию. Кроме технической стороны, стоит отметить удобство и открытость созданной среды.
Она совместима со Stable-Baselines3 — одной из самых популярных и постоянно обновляемых библиотек для разработки и тестирования алгоритмов DRL. Это позволяет другим исследователям и инженерам быстро внедрять, тестировать и улучшать свои модели, ускоряя тем самым развитие сферы. Среда обеспечивает не только получение визуального наблюдения, но и отслеживание контактов штыря с поверхностями — с объектом и столом, что помогает формализовать сигнал вознаграждения, направляя обучение агента на избегание нежелательных столкновений. Вознаграждающая функция продумана так, чтобы поощрять приближение к цели и успешное вкладывание, а также быстро завершать эпизоды в случае неудачи, что способствует эффективной оптимизации политики управления. Для обучения и тестирования модели используется мощное оборудование — например, ноутбук с графическим процессором NVIDIA RTX 3050, обеспечивающий ускорение вычислений и приемлемое время прогона в несколько часов.
Примечательно, что среда предусматривает автоматическое сохранение контрольных точек — checkpoints — каждые 10 тысяч шагов, позволяя контролировать процесс обучения и возвращаться к успешным версиям моделей. Со своей стороны, визуализация результатов происходит через построение графиков сходимости вознаграждения, что даёт наглядное представление о стабильности и прогрессе алгоритма на протяжении всего процесса обучения. Важно, что вся разработка ведётся на базе открытого программного обеспечения с использованием языка Python, что делает её доступной и интегрируемой в существующее ПО или встраиваемой в производственные системы. Основной вызов задачи peg-in-hole заключается в необходимости точного позиционирования деталей с учётом возможных вариаций положения, небольших ошибок восприятия и нестабильности окружающей среды. Применяемый подход с eye-in-hand визуальной обратной связью позволяет роботу самостоятельно корректировать свои движения, основываясь на реальном видении ситуации и обновлении информации после каждого шага.
Это существенно повышает универсальность и надёжность алгоритма. Кроме того, данные исследования вносят вклад в понимание того, как DRL можно эффективно комбинировать с физическими моделями и симуляторами для достижения производственных целей. Подобные технологии имеют потенциал революционизировать автоматизацию в таких сферах, как сборка электронных устройств, производство микроустройств, роботизированные склады и другие области, где чувствительность к точности операций критична. Перспективы расширения включают интеграцию с более сложными сенсорными системами — например, использование цветных камер или 3D-датчиков, что может улучшить качество восприятия. Также возможен переход к мультиагентным системам, где несколько роботов работают совместно.
В заключение, проект, симулирующий задачу peg-in-hole с использованием глубокого обучения с подкреплением на платформе UR5, является наглядным примером успешного применения современных AI-технологий в реальном мире робототехники. Высокая точность, скорость обучения и стабильность алгоритма SAC, в сочетании с удобной и открытой средой обучения, делают этот подход важным этапом в дальнейшем развитии автоматизированных систем с визуальным восприятием и сложными манипуляциями. Учитывая открытость, масштабируемость и доступность, внедрение таких решений будет способствовать повышению эффективности производства и качества продуктов, создавая фундамент для инноваций в индустрии робототехники и искусственного интеллекта.