Современный мир технологий и искусственного интеллекта стремительно развивается, а сфера обработки и поиска информации не стоит на месте. Одним из новых и перспективных направлений является DeepSearch – сложный подход к поиску, благодаря которому можно получить максимально релевантные и точные ответы на самые сложные запросы. Одной из наиболее интересных разработок в этой области стала минималистичная реализация jdr, способная продемонстрировать состояние современного искусства (SOTA) в DeepSearch, сохраняя при этом лаконичность и простоту. В данном обзоре мы подробно рассмотрим особенности проекта, его возможности, технические детали и влияние на будущее исследований и интеллектуального поиска. DeepSearch – это методика, объединяющая итеративный процесс поиска, чтения и рассуждений, что значительно повышает качество выдаваемой информации.
Это зависит не только от силы модели искусственного интеллекта, но и от эффективности взаимодействия с внешними инструментами, такими как поисковые системы или парсеры страниц. Проект jdr построен на базе модели gemini-2.5-flash-preview-05-20 и использует интеграцию с такими инструментами, как SERP для поиска и JINA Reader для извлечения контекста с веб-страниц. Такой выбор направлен на оптимизацию процесса получения точных данных и глубокого анализа полученной информации. Одной из уникальных характеристик jdr является внедрение механизма «двойной проверки».
После первого ответа агента система перепроверяет результаты на предмет пропусков или ошибок, что позволяет снизить уровень галлюцинаций модели и улучшить точность. Это решение обеспечило заметный прирост производительности на проверочных наборах данных, например, увеличив точность на бенчмарке FRAMES на 6 процентных пунктов. Для использования jdr необходимо обеспечить наличие соответствующих API-ключей для работы с внешними сервисами, такими как GEMINI, SERPAPI и JINA. Установка реализована через удобный менеджер пакетов pip, что позволяет быстро развернуть среду и приступить к работе. Кроме того, разработчики рекомендуют использовать pixi для более упрощенного управления зависимостями и удобного запуска команд.
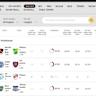
В сравнении с аналогами jdr демонстрирует впечатляющие показатели. На бенчмарках FRAMES, SimpleQA и SEAL0 система достигает новых высот, что особенно ценно, учитывая минимальную сложность реализации в чуть менее чем 1500 строк кода. Это подчеркивает потенциал проекта для быстрого прототипирования и масштабируемости при сохранении качества результатов. Несмотря на то, что в данной сфере нет единого централизованного рейтинга, jdr показывает лучшие или сопоставимые результаты с другими известными системами, такими как kimi-researcher и OpenDeepSearch. Это значит, что проект можно использовать как основу для построения более сложных агентных систем и экспериментальных решений в области обработки естественного языка и интеллектуального поиска.
Важным аспектом при оценке качества систем DeepSearch является проблема единых метрик и авто-грейдеров, так как большинство бенчмарков требуют оценки с помощью языковых моделей, что создаёт сложность в сравнении результатов. jdr предлагает собственные варианты автоматизированных оценщиков, учитывающих специфику тестов и обеспечивающих максимальную объективность. Эти оценщики реализованы для нескольких наборов данных и позволяют стандартизировать подход к проверке качества ответов. В отличие от DeepResearch, куда входит формирование развернутых научных отчетов, DeepSearch ориентирован на эффективный цикл поиска и рассуждений для нахождения оптимального ответа. В этом плане jdr служит отличным примером инструмента DeepSearch, демонстрирующего, что глубокий интеллектуальный поиск можно реализовать компактно, функционально и качественно.
Для специалистов в области AI, исследователей и разработчиков инструмент jdr представляет ценный ресурс, позволяющий понять базовые принципы создания агентных систем с поддержкой сторонних инструментов и механизмов улучшения качества итогового результата. Простота реализации делает проект отличной отправной точкой для обучения и дальнейших разработок. Перспективы развития jdr связаны с расширением функциональности, интеграцией новых источников данных и улучшением алгоритмов двойной проверки. В сочетании с ростом возможностей языковых моделей такие системы смогут кардинально трансформировать способы поиска и обработки информации, сделать их более интеллектуальными, динамичными и максимально приближенными к потребностям пользователей. В конечном итоге jdr демонстрирует, что даже минималистичные реализации могут конкурировать с более громоздкими решениями, если грамотно сбалансированы архитектура и логика работы.
Это открывает двери для широкого внедрения подобных подходов в практику – от образовательных проектов до коммерческих продуктов с искусственным интеллектом, работающих с большими объемами данных и сложно структурированной информацией. Экосистема вокруг jdr продолжит расти и привлекать внимание, а сотрудничество сообщества и обмен опытом позволят разработать общепринятые стандарты для оценки и использования DeepSearch-технологий. В итоге этот проект станет отправной точкой на пути к более интеллектуальным и надежным системам поиска и исследований, отвечающим самым высоким требованиям современной эпохи информации.