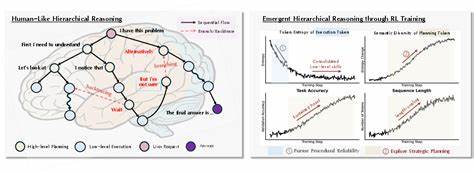
В последние годы большие языковые модели (LLM) превратились в мощный инструмент для решения сложных задач, связанных с естественным языком, включая генерацию текста, перевод, ответ на вопросы и многие другие функции. Одним из наиболее перспективных направлений в развитии LLM стало применение методов обучения с подкреплением (reinforcement learning - RL), что позволило существенно улучшить их способности к сложному рассуждению и стратегическому мышлению. Несмотря на очевидные успехи в этой области, механизмы, обеспечивающие эффективное обучение и развитие иерархических структур мышления, остаются малоизученными и требуют глубокого анализа. Недавно исследовательская группа во главе с Хаожэ Ваном представила значимый вклад в понимание динамики обучения LLM посредством RL, обнаружив явление, которое можно назвать "возникновением иерархического рассуждения". Их работа демонстрирует, что успешное улучшение модели в процессе обучения происходит не просто как результат равномерного улучшения всех аспектов мышления, а вследствие формирующегося разделения на два уровня: высокоуровневое стратегическое планирование и низкоуровневое процедурное исполнение.
Такое разделение напоминает устроение человеческой когниции, где абстрактные общие планы соотносятся с детализированным исполнением конкретных операций. В ходе обучения с подкреплением первоначально модель сосредотачивается на освоении базовых процедурных навыков, обеспечивающих корректное выполнение элементарных шагов задачи. Эта начальная фаза характеризуется строгими ограничениями, вызванными потребностью в точности и воспроизводимости действий. Лишь после успешного преодоления данных ограничений исследование и развитие модели переключаются на более сложный уровень - стратегическое планирование, включающее разметку иерархий, формирование планов, оценку долгосрочных целей и выбор оптимальных направлений действий. Описание такого двухфазного процесса обучению позволило понять природу загадочных явлений, наблюдаемых ранее исследователями за LLM.
Среди них - "моменты озарения" ("aha moments"), резкие скачки в качественном уровне рассуждения; масштабируемость по длине ("length-scaling"), наблюдаемая в способности модели оперировать с большими объемами информации без потери эффективности; а также динамика энтропии, связанная с постепенным снижением неопределенности и повышением уверенности в принятии решений. Все эти феномены обнаруживаются как естественные проявления формирования иерархии принятия решений. Однако исследователи отметили и важное ограничение существующих алгоритмов RL, таких как GRPO, которые применяют оптимизационное давление без учета вклада отдельных компонентов модели. Другими словами, оптимизация происходит равномерно по всем токенам и частям рассуждения, что приводит к размыванию сигналов обратной связи и снижению эффективности обучения. В ответ на этот вызов была предложена новая методика - Hierarchy-Aware Credit Assignment (HICRA), или иерархически осознанное распределение кредитов.
HICRA направлена на концентрирование оптимизационных усилий именно на тех токенах, которые оказывают максимальное влияние на формирование высокоуровневых стратегий. Такой подход позволяет не просто улучшать механические навыки, но и стимулировать модель к глубокому анализу и разработке продвинутых планов. Практические эксперименты с HICRA показали значительное превосходство этого метода перед существующими базовыми алгоритмами, что подтверждает потенциал иерархического подхода к обучению LLM. Значение открытия иерархического рассуждения в LLM выходит далеко за рамки чисто технических достижений. Оно открывает новые горизонты в понимании того, как сложные когнитивные функции могут возникать и развиваться в искусственных системах.
Подход, симулирующий человеческий стиль мышления с разделением на планы и действия, позволяет не только создавать более эффективные модели, но и лучше прогнозировать их поведение в сложных сценариях. Сегодня на стыке методов глубокого обучения и когнитивных наук формируются передовые стратегии развития ИИ, и иерархические алгоритмы обучения оправдывают свое место в этом процессе. В частности, преимущества HICRA отражаются в повышенной интерпретируемости модели, что важно для внедрения ИИ в критически значимые сферы, такие как медицина, юридические консультации и управление промышленными системами. Дополнительно концепция иерархического рассуждения может стать базисом для дальнейших исследований в таких областях, как мультиагентные системы, где требуется согласованное планирование на разных уровнях абстракции, а также адаптивные модели, способные быстро переключаться между стратегиями в зависимости от контекста. Для разработчиков и исследователей, работающих в области искусственного интеллекта, понимание этой динамики обучения становится ключевым элементом для создания новых, более мощных языковых моделей.
Она открывает путь к тому, чтобы искусственный интеллект не только выполнял инструкции, но и проявлял гибкость, творческое мышление и способность к самосовершенствованию в реальном времени. В итоге, появление иерархического рассуждения через обучение с подкреплением представляет собой значительный шаг вперед в эволюции искусственного интеллекта. Лингвистические модели, обладающие такими способностями, будут играть ключевую роль в создании интеллектуальных систем нового поколения, способных справляться с задачами любой сложности и адаптироваться к меняющемуся миру. Понимание механизмов, лежащих в основе этого явления, стимулирует дальнейшее развитие методик обучения и оптимизации языковых моделей, делая их более мощными, надежными и применимыми в разнообразных сферах деятельности человека. Вполне очевидно, что именно иерархический подход станет фундаментом для будущих инноваций в области искусственного интеллекта.
.