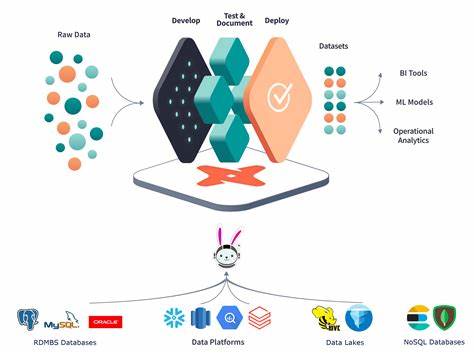
Trino — мощный распределённый движок для выполнения запросов, способный обрабатывать данные из множества источников, будь то облачные платформы, локальные хранилища, базы данных или файловые системы с открытыми форматами. Его гибкость и универсальность делает его привлекательным инструментом для объединения данных в масштабах всей организации. Однако использование Trino без должного понимания его внутренней архитектуры и особенностей взаимодействия с источниками данных может привести к серьёзным проблемам с производительностью, которые проявляются в виде узких мест при доступе к данным. Важно понять причины этих ограничений и способы их устранения, чтобы эффективно эксплуатировать возможности Trino и максимально повысить скорость обработки запросов. Основная функциональность Trino заключается в том, что это движок выполнения запросов и обработки данных, а не система хранения.
В отличие от традиционных систем управления базами данных, которые объединяют хранение и обработку в одном продукте, Trino отвечает только за выполнение запросов, обращаясь к удалённым и распределённым источникам данных. Такая архитектура накладывает свои особенности на работу с данными и требует специальных подходов для обеспечения эффективного взаимодействия с разнородными системами хранения. Одна из основных проблем в производительности Trino возникает из-за способа передачи и получения данных между движком и хранилищами. Многие источники данных поддерживаются через универсальные, или generic, коннекторы, в частности через JDBC. Несмотря на широкую распространённость и удобство JDBC, этот интерфейс демонстрирует крайне низкую пропускную способность при передаче больших объёмов данных.
Причина в том, что JDBC работает методом получения строк по одной (tuple-at-a-time) в одном потоке, что значительно замедляет процессы чтения, особенно при обработке больших датасетов в сотни гигабайт и терабайт. Такая организация обмена данными практически блокирует потенциал масштабирования Trino — даже на мощных кластерах и высокоскоростных сетях скорость передачи через JDBC остаётся узким местом. Поскольку данные идут по одному ряду, Trino не может воспользоваться преимуществами хранения данных в колоночном формате, что ещё больше снижает общую производительность. Это обстоятельство часто становится определяющим фактором в снижении эффективности работы и требует особого внимания при проектировании систем с использованием Trino. Для смягчения этой проблемы Trino применяет различные техники, включая попытки передачи части обработки запросов на сторону источника данных, что называется pushdown.
Под запросы попадают фильтры, агрегации, ограничение количества строк и иногда простые соединения. Чем больше операций удаётся реализовать на стороне базы данных, тем меньше будет объём данных, передаваемых через JDBC, и тем выше итоговая производительность. Тем не менее, pushdown имеет свои ограничения и не покрывает все виды операций, особенно когда речь идёт о сложных джойнах между разными источниками данных или сложной логике в запросах. Узкие места при передаче данных через JDBC сохраняются и нуждаются в иных подходах для их устранения. Одним из ключевых достоинств Trino является его модульная архитектура с использованием коннекторов.
Существует два типа таких интеграций: generic и specific. Generic-коннекторы предназначены для обеспечения совместимости с множеством источников и поэтому не учитывают специфические особенности систем хранения. Они обычно используют универсальные протоколы, такие как JDBC, что ведёт к низкой эффективности и появлению узких мест. В свою очередь specific-коннекторы разрабатываются с учётом особенностей конкретных систем, что позволяет более эффективно организовать взаимодействие и задействовать внутренние механизмы хранения данных для повышения производительности. Важной функциональной частью specific-коннекторов является поддержка партицирования данных.
Партиционирование — это разделение большого объёма данных на независимые части на основе выбранного атрибута, например, времени, региона или идентификатора пользователя. Это позволяет выполнять параллельную загрузку данных из разных партиций, существенно увеличивая пропускную способность и уменьшая время выборки. При корректном партиционировании Trino может выполнять множественные параллельные запросы, что смягчает эффект однопоточного ограничения JDBC. Если партиционирование данных отсутствует или не оптимально, можно столкнуться с полными сканированиями таблиц, что обрушивает производительность Trino. В таких сценариях стоит рассмотреть возможность переконфигурации источника данных с добавлением партиционирования.
Это часто доступно с помощью простых команд SQL или административных настроек в системе хранения. Некоторые specific-коннекторы также позволяют более агрессивно выполнять pushdown, передавая сложные операции обработки запросов в исходную систему. Это дополнительно снижает нагрузку на Trino и уменьшает объём транзакционных данных которые движок должен получить и обработать. На практике, чтобы выявить причины замедления в Trino, необходимо анализировать, к каким источникам обращаются проблемные запросы. Обычно узкие места возникают при обращении к системам, использующим generic JDBC-коннекторы.
Проблемы с передачей из форматов данных, размещённых в озерах данных или HDFS, встречаются реже благодаря оптимизации под работу с колоночными форматами и параллелизмом. Если в вашей архитектуре используется множество источников, нужно провести аудит и выяснить, какие из них вызывают наибольшие задержки. Если используется generic-коннектор и нет возможности заменить его на specific, стоит рассмотреть переход на более продвинутые дистрибутивы Trino, например, коммерческие версии Starburst Enterprise или Galaxy. Они поставляются с расширенным набором optimized-коннекторов, которые справляются с передачей данных гораздо эффективнее и поддерживают более глубокий pushdown и партиционирование. При наличии specific-коннектора нужно проверить, настроено ли корректное партиционирование на стороне источника.
Если отсутствует, попробуйте реализовать его, исходя из особенностей вашего бизнеса и типа данных. Иногда смена атрибута для партиционирования улучшает производительность заметно больше, чем изначально ожидалось. Также стоит рассмотреть стратегию использования более узких и агрессивных фильтров в запросах. Поскольку Trino умеет создавать параллельные JDBC-соединения при разделении выборок, выполнение нескольких небольших запросов вместо одного большого может значительно ускорить общую операцию. Этот подход требует дополнительных усилий по организации запросов и обработки результатов, но оправдывает себя при работе с большими объёмами данных.
Если ни один из методов не приносит желаемых улучшений, рекомендуется подумать о построении ETL-процессов для регулярного снятия снимков (snapshot) данных из источников и их сохранения в формате Parquet или других открытых колоночных форматах в дата-лаке. Такой подход минимизирует проблемы с производительностью, так как Trino эффективно работает с данными в этих форматах и хорошо масштабируется. Стоит принять во внимание, что при таком способе данные реплицируются и возникает некоторая задержка их актуализации. Для предприятий, использующих инструменты Starburst Enterprise и Galaxy, существуют дополнительные возможности автоматизации таких процессов через Table Scan Redirections. Этот механизм позволяет автоматически перенаправлять запросы к оптимизированным репликам данных в дата-лаке, что уменьшает время отклика и повышает общую эффективность обработки.
В заключение, Trino — это крайне мощный и гибкий движок для анализа данных, однако без понимания и учёта его архитектурных особенностей легко столкнуться с падением производительности при доступе к определённым типам источников. Проблема с JDBC как узким местом передачи данных особенно актуальна и требует грамотного подхода к проектированию систем и выбору коннекторов. Уделяя внимание корректной настройке партиционирования, использованию specific-коннекторов и оптимизации запросов, а при необходимости – организации ETL-процессов с загрузкой в дата-лейк, можно значительно повысить скорость и эффективность работы Trino. Следует помнить, что не все источники данных равнозначны с точки зрения производительности, и именно выбор подходящих механизмов доступа и интеграций помогает раскрыть весь потенциал Trino в современных масштабах обработки данных.