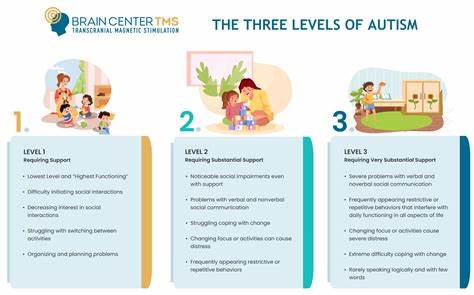
В последние годы искусственный интеллект, а особенно большие языковые модели (LLM), стремительно вошли в повседневную жизнь и бизнес-процессы. Их возможности по генерации текста, пониманию контекста и выполнению задач впечатляют. Однако с ростом популярности AI-агентов, которые используют LLM для автоматизации сложных рабочих процессов, появилось и множество новых вызовов, связанных с их непредсказуемостью и нестабильностью работы. Как раз за счёт явной непредсказуемости и «хаотичного» поведения подобных систем инженерам приходится изобретать подходы, чтобы снизить уровень неопределённости и сделать AI-агентов более полезными и надёжными в реальных условиях. В статье рассматривается опыт и принципы, которые помогают «инженерно выстроить» работу AI, минимизируя эффекты хаоса и создавая комфортный инструментарий для разработчиков и пользователей.
Одним из центральных вызовов при создании AI-агентов на основе LLM является то, что их вывод по своей природе не детерминирован. Это означает, что при одних и тех же входных данных модель может выдавать разный результат — от вариаций формулировок до принципиально разных вариантов решения. Для инженеров традиционного программного обеспечения такая ситуация кажется непривычной и даже неприемлемой, поскольку они привыкли к чётко прогнозируемому поведению. Взаимодействие с LLM нелинейно и зависит от множества факторов — состава и содержания промпта, внутреннего обучения модели, текущей загруженности сервера и даже версии самой модели. Чтобы создать рабочий AI-агент, который автоматизирует задачи, например, в области DevOps, тестирования или поддержки CI/CD, необходимо как минимум признать, что полностью убрать погрешности и вариации в поведении нельзя.
Важно понять, что сам подход к проектированию и тестированию AI должен строиться с учётом принятия этой особенности как исходной. При этом стоит учиться работать с LLM как с полноценным «пользователем», способным ошибаться, упускать детали инструкций и нуждаться в отладке и корректировке на основе обратной связи. Один из ключевых принципов, которые доказали свою эффективность, — начинать с малого и оперативно тестировать динамику работы с реальными данными. Нельзя сразу создавать универсального агента, который будет выполнять широкий спектр задач. Такой подход слишком сложен в реализации и неизбежно приведёт к «размазыванию» внимания и неэффективности.
Вместо этого лучше сфокусироваться сначала на конкретной задаче, например, на анализе причин падения тестов в CI системе. Выбор узкой и чётко определённой области позволяет на ранних этапах понять особенности взаимодействия с LLM, наладить корректность ответов, протестировать инструмент на рабочих сценариях и получить ценный фидбек от пользователей. Благодаря такой дисциплине появляется возможность быстро фиксировать причины ошибок или нестабильности, а значит — повышать качество и успех итераций по улучшению агента. Кроме того, разумно использовать предварительные методы подготовки данных перед передачей их модели. Например, группировка схожих сбоев, удаление нерелевантной информации или сокращение объёма логов для укладывания в ограниченный размер контекстного окна значительно повышают эффективность работы.
Таким образом, LLM может сосредоточиться на самой важной информации, а не перегружаться лишними данными. При работе с LLM нельзя забывать, что не существует «волшебного промпта», который решит все проблемы. Хотя создание хорошего системного промпта остаётся важным, стоит помнить об ограничениях и необходимости экспериментов с разными языковыми моделями. Иногда смена модели может радикально улучшить воспроизводимость результатов и поведение агента, снижая количество ошибок в вызовах инструментов и упрощая отладку. Например, известны случаи, когда одна модель плохо справлялась с методичной последовательностью вызовов, а другая, менее «умная» в рассуждениях, оказалась более детерминированной и стабильно выдающей результаты.
Такой подход системной замены помогает инженерам подобрать оптимальный силовой агрегат для конкретных нужд. Важным фактором успеха является активное использование собственного AI-агента в рабочих процессах компании. Отказаться от концепции «разработать и забыть» помогает практика «есть свою еду» (eat your dog food), то есть применять создаваемый инструмент внутри команд и получать постоянную обратную связь. Такой режим эксплуатации ускоряет выявление проблем, понимание реальных сценариев использования и налаживание механизма сбора отзывов. Разработка кнопочного или интегрированного в CI интерфейса для передачи комментариев и предложений пользователями дополнительно мотивирует команду разработки на качественные улучшения.
Не стоит забывать про традиционные методы тестирования в окружении AI-агентов. Несмотря на включение LLM как важного компонента, саму систему необходимо покрывать юнит-тестами и интеграционными проверками, особенно для инструментов, которые взаимодействуют с AI или парсят его вывод. Мокирование ответов LLM через специализированные SDK помогает отсекать класс ошибок и воспроизводить граничные сценарии. При этом интеграционные и энд-ту-енд тесты с реальными вызовами модели выявляют неожиданные случаи и способствуют выработке более грамотной обработки ошибок и откликов. Особенное внимание уделяется формату вывода агента, ведь даже максимально правильная информация теряет смысл, если она подаётся в сложном или избыточно развёрнутом виде.
Опыт показывает, что пользователи хотят быстро получить понятный и лаконичный ответ, который сразу можно применить без дополнительного анализа. Поэтому форматирование вывода, ограничение длины и создание структурированных ответов — это не просто приятные «фишки», а критически важные моменты UX для пользователей, в том числе для других автоматизированных систем, которые могут потреблять данные агента. Повторные попытки генерации при несоответствии ограничений осуществляются c разумными лимитами, чтобы не потерять контроль над затратами и временем отклика. Главная ценность полученных выводов — именно достигнутый баланс между уровнем автоматизации и контролем качества по мере прогресса развития моделей и инфраструктуры. Отказ от жёсткой ориентации на «идеальный» первичный запуск и переход к постепенному улучшению агентов, позволяющему со временем нарастить долю успешных «one-shot» решений, является более разумной тактикой.