В последние годы технологии искусственного интеллекта стремительно меняют облик многих сфер человеческой деятельности, и наука — не исключение. Одним из важнейших нововведений стало появление и быстрое распространение больших языковых моделей (LLM), таких как ChatGPT. Эти алгоритмы способны генерировать и редактировать текст на человеческом уровне, помогая исследователям в подготовке научных публикаций. Однако влияние LLM на научное письмо долго оставалось недооцененным, поскольку считалось, что это лишь вспомогательный инструмент, не меняющий фундаментально научную коммуникацию. Новейшие исследования показывают, что внедрение LLM привело к ошеломляющим сдвигам в лексике и стиле биомедицинских публикаций, что может изменить не только характер научного текста, но и профессиональные стандарты в академическом мире.
С огромным корпусом из более чем 15 миллионов аннотаций статей, опубликованных с 2010 по 2024 год и доступных через PubMed, международная команда исследователей провела целенаправленный анализ изменения частоты употребления слов в биомедицинских текстах. Итогом стала убедительная демонстрация резкого всплеска использования определённых слов и стиля изложения в период после появления и широкого применения LLM. Авторы работы сравнили современные изменения с лексическими сдвигами, вызванными глобальными событиями, такими как пандемия COVID-19, и пришли к выводу, что влияние искусственного интеллекта превзошло даже эти знаковые факторы. Уже с первых лет применения LLM в науке учёные начали замечать появление своеобразных маркерных слов, которые не были связаны с контентным наполнением исследования, а скорее относились к стилистическим элементам текста. Такие слова, например, как «delve», «underscore» или «showcase», в 2024 году резко начали встречаться значительно чаще, чем ожидалось по трендам предыдущих лет.
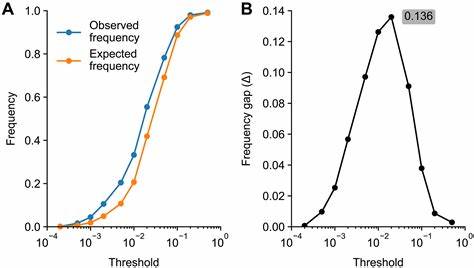
В отличие от таких контентных терминов, как «коронавирус» или «пандемия» в период COVID, эти новые слова не отражают тематику исследований, а скорее изменённый стиль научной речи — более «цветистый», «экспрессивный» и «выразительный», что является отличительной чертой текстов, сгенерированных или переработанных с помощью LLM. Анализ слова за словом продемонстрировал, что в биомедицинской литературе 2024 года около 13,5% аннотаций, по меньшей мере, отчасти были созданы с помощью LLM. При этом это значение является только нижней границей оценки. Реальное число может быть значительно выше, поскольку многие статьи, над которыми работали с использованием искусственного интеллекта, могут не содержать в тексте выделяющихся маркерных слов, либо авторы искусно редактируют и изменяют предложенные модели фразы, скрывая следы применения алгоритмов. Важной особенностью этого исследования стало выявление значительного различия в уровне применения LLM по разным странам, дисциплинам и изданиям.
К примеру, отрасли, связанные с вычислительной биологией и биоинформатикой, показали самые высокие показатели — до 40% материалов с элементами LLM-помощи. Аналогично, страны с доминирующим вторым языком — например, Китай, Южная Корея и Тайвань — характеризовались более активным обращением к LLM, возможно, ввиду необходимости делового и научного общения на английском языке. В то время как в англоязычных регионах, таких как Великобритания и Австралия, использование LLM оказалось ниже, тем не менее, оно всё же значимо и растёт. Также было отмечено, что крупные престижные журналы — Nature, Science, Cell — демонстрируют более консервативные показатели по LLM-участию, тогда как в журналах с быстрым процессом рецензирования и открытым доступом, таких как MDPI Sensors или Cureus, процент экспериментов с искусственным интеллектом значительно выше. Это может отражать разные подходы и ожидания качества в зависимости от уровня строгости издательской политики.
Тенденции использования LLM отличаются не только по географическому и дисциплинарному признаку, но и по лингвистическим особенностям. Например, носители английского языка могут тщательнее редактировать текст, отбросив излишне «машинные» обороты, в то время как авторы, для которых английский — второй язык, скорее охотно используют готовые стилистические конструкции, предлагаемые LLM. Это создаёт интересный лингвистический пласт влияния, при котором искусственный интеллект не только ассистирует, но и частично формирует новые языковые модели научного письма. Стилистические изменения включают активное внедрение в тексты глаголов и прилагательных, которые повышают выразительность и эмоциональную насыщенность научного изложения. Взять, к примеру, слова «notably», «crucial» и «exhibited» — они стали встречаться заметно чаще, что добавляет статьям яркости и подчёркивает авторитетность высказываний.
Такое семантическое богатство ранее было характерно преимущественно для редакционных доработок и художественной литературы, но теперь входит в инструментарий современных академиков благодаря сотрудничеству с LLM. Однако стоит понимать, что массовое использование языковых моделей вызывает и определённые опасения. Главной проблемой является риск распространения фактических неточностей, неуместных генераций и даже плагиата, что подрывает научную достоверность. Авторы, применяющие LLM, обязаны внимательно проверять сгенерированные тексты, чтобы избежать ошибок и недоразумений. Кроме того, внедрение единого стиля и шаблонных формулировок, зачастую свойственное LLM, грозит снижением разнообразия научных идей и креативности, что негативно скажется на прогрессе и инновациях.
Появление электронных инструментов массовой генерации текста также наталкивается на этические и нормативные вызовы. Многие издатели и научные сообщества уже вводят правила, ограничивающие или требующие раскрывать участие искусственного интеллекта при подготовке статей. Ряд агентств финансирования и журналов запрещают использование LLM при рецензировании, а также требуют прозрачности при использовании ИИ в исследовательских процессах, чтобы гарантировать честность и подлинность научной работы. Будущее научной публикации неизбежно будет связано с дальнейшим усложнением и совершенствованием LLM. Разработка моделей с возможностью интеграции проверки фактов, а также поддержка корректных ссылок помогут смягчить риски и повысить качество текстов.