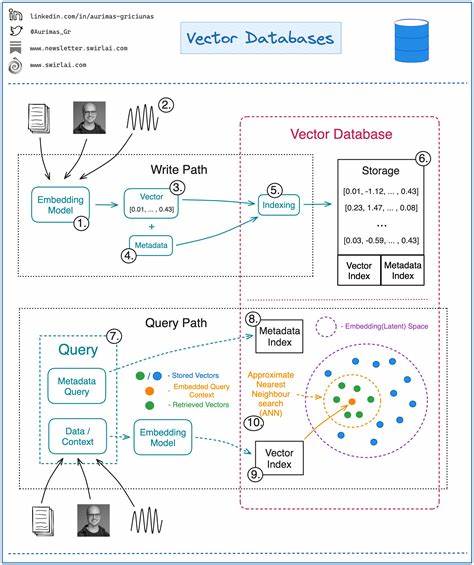
В последние годы векторные базы данных привлекают все больше внимания со стороны специалистов в области информационных технологий и искусственного интеллекта. Эти системы находятся на переднем крае развития технологий хранения и поиска данных, позволяя обрабатывать сложные и объемные наборы информации, которые традиционные реляционные базы данных зачастую неспособны эффективно анализировать. Особенно это актуально в эпоху активного распространения искусственного интеллекта и машинного обучения. Но что же такое векторные базы данных и почему они стали настолько востребованными? В основе любой векторной базы данных лежит концепция представления информации в виде векторов — числовых массивов, которые отражают различные характеристики и особенности данных. Сегодня около 80% всей создаваемой информации в мире — это неструктурированные данные, то есть данные, которые не помещаются в привычные таблицы с фиксированными столбцами и строками.
Это могут быть текстовые сообщения, изображения, аудио и видеофайлы, документы, публикации в социальных сетях и многое другое. Традиционные системы управления базами данных (СУБД), ориентированные на структурированные данные, неэффективны при работе с такими форматами. Для удобного и точного поиска по неструктурированным данным приходится вручную назначать ключевые слова или теги, что далеко не всегда оправданно и не всегда точно отражает содержание файлов. Здесь на сцену выходят векторные базы данных. Их революция заключается в том, что вместо поиска строгих совпадений по ключевым словам или идентификаторам, они применяют математические модели для измерения похожести объектов с помощью вычисления расстояния между векторами.
Например, в словесном контексте эти системы понимают, что слова «бордовый», «оранжевый» и «черный» хоть и разные, но могут быть близки по смыслу или характеристикам, что невозможно отследить при классическом точечном поиске. Чтобы получить векторное представление данных, используются специализированные алгоритмы и модели машинного обучения, которые превращают текст, изображения, аудио и другие типы данных в многомерные векторы чисел. Эти числовые массивы становятся координатами в абстрактном пространстве, где расстояния и углы между векторами отражают степень схожести между объектами. Рассмотрим пример с цветом. В цветовом пространстве RGB каждый цвет кодируется тремя числами — уровнем красного, зеленого и синего.
Красный цвет будет иметь вектор [1.0, 0.0, 0.0], зеленый — [0.0, 1.
0, 0.0], а пурпурный — [0.5, 0.0, 0.5], что указывает на равное сочетание красного и синего.
Если необходимо найти цвета, наиболее похожие на пурпурный, используются вычисления, которые определяют, что пурпурный ближе к красному, чем к зеленому, исходя из близости по координатам. Аналогично, в обработке текста применяются более сложные методы, такие как нейросетевые модели и трансформеры, которые масштабируют векторное представление до сотен и даже тысяч измерений. Важной особенностью таких векторов является то, что значения в них базируются не просто на статистических связях, но и на семантической близости. Например, векторы для слов «седан» и «внедорожник» (SUV) будут близки друг к другу, отражая сходство в категориях автомобилей, в то время как «шоколад» будет располагаться в отдаленной части векторного пространства. Для вычисления степени похожести между двумя векторами применяются различные математические методы.
Наиболее популярными являются косинусное сходство и евклидово расстояние. Косинусное сходство оценивает угол между двумя векторами: чем меньше угол, тем выше сходство. Если два вектора направлены в одинаковую сторону, значение косинусного сходства будет равно 1, что означает максимальную похожесть. Евклидово расстояние, в свою очередь, оценивает прямое линейное расстояние между точками в пространстве. Чем меньше это расстояние, тем ближе объекты друг к другу.
Применение этих метрик позволяет системе эффективно сравнивать и фильтровать объекты по степени их семантической или визуальной близости. Однако с ростом базы данных возникает вопрос масштабируемости: как эффективно находить похожие векторы среди миллионов и миллиардов записей? На помощь приходят методы индексирования векторных данных. Векторные индексы работают по принципу организации пространства таким образом, чтобы ускорить поиск похожих объектов, сокращая количество необходимых проверок. Для этого используют специальные алгоритмы, такие как приближенные методы поиска ближайших соседей (ANN), которые ценят баланс между скоростью и точностью. Распространенным подходом являются графовые структуры, например иерархические навигируемые маломирные графы (HNSW), а также техники квантизации, которые позволяют хранить и обрабатывать данные при оптимальном использовании памяти и ускорении вычислений.
На практике векторные базы данных уже нашли широкое применение. Поисковые системы, например Google или Яндекс, используют векторные индексы для обработки запросов пользователей, превращая текст запросов и содержимое документов в векторы и сопоставляя их друг с другом. Это позволяет находить релевантную информацию, даже если запрос сформулирован иначе, чем содержимое страницы, благодаря пониманию семантики текста. Социальные сети и мультимедийные платформы применяют векторные представления для анализа изображений, видео и аудио. Instagram, например, преобразует фотографии в векторные описания, учитывая цвета, формы и стили, что дает возможность рекомендовать похожие изображения, обнаруживать дубли и следить за соблюдением правил сообщества.
Аналогично видео-сервисы используют векторные данные для индексации сцен, автоматического поиска и формирования рекомендаций. Творческие и бизнес-приложения также выигрывают от использования векторных баз данных. Системы рекомендаций фильмов, музыки и товаров становятся более персонализированными, а аналитика больших данных приобретает новую глубину благодаря возможности обрабатывать неформатированный контент. Важно понимать, что векторные базы данных — не панацея для всех задач. Для некоторых простых проектов достаточно классических реляционных систем или традиционных методов обработки данных.
Но когда дело касается анализа больших объемов неструктурированной информации, возможности векторных баз выходят на первый план. С постоянным развитием технологий машинного обучения и вычислительных мощностей векторные базы данных продолжают расширять сферу своего применения, меняя представление о том, как мы можем организовать, хранить и искать данные в эпоху цифровой информации. Их использование открывает путь к созданию более интеллектуальных и отзывчивых приложений, способных понимать контекст и смысл, а не просто искать простые совпадения, что является новым шагом в эволюции информационных систем.

![Zig Roadmap 2026 [video]](/images/2615B6F6-D285-446D-9396-1A93712E99B6)