В эпоху стремительного развития искусственного интеллекта большие языковые модели (Large Language Models, LLM) становятся все более востребованными в различных сферах — от чата и автоматического перевода до создания контента и аналитики. Однако вместе с их популярностью растут вопросы не только о качестве и эффективности, но и об экологической и финансовой стоимости их эксплуатации. Одним из ключевых аспектов является количество энергии, потребляемой для генерации одного токена при работе LLM. Этот показатель становится особенно важным, учитывая усилия по снижению воздействия технологий на окружающую среду и оптимизации затрат на вычисления. В этой статье рассматривается, сколько энергии требуется для производства одного токена крупной языковой моделью, а также какие факторы влияют на эту величину, каковы способы её оценки и уменьшения.
Понимание данных аспектов помогает специалистам и пользователям осознанно подходить к использованию ИИ и развивать более устойчивые методы его внедрения. Большие языковые модели — что это и как работают Прежде чем углубиться в энергозатраты, важно понять, что такое LLM и как они функционируют на техническом уровне. LLM — это нейросетевые архитектуры с сотнями миллиардов параметров, обученные на огромных объемах текстовых данных. Эти параметры — своеобразные веса модели, которые влияют на результаты при генерировании текста. При запросе (например, при написании следующего слова или фразы) модель совершает вычисления, применяя математические операции к подмножеству параметров, чтобы определить вероятный ответ.
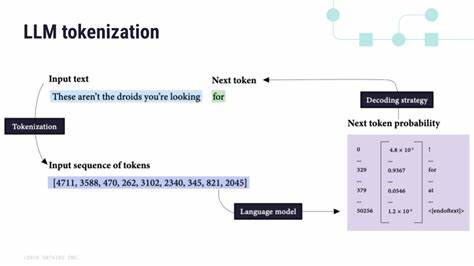
Каждый отдельный генерируемый элемент текста называют токеном, и именно вычисления, связанные с созданием этого токена, определяют энергопотребление в процессе инференса (прогнозирования). Роль параметров модели и тип архитектуры влияют на количество необходимых операций. Например, в плотных (dense) моделях задействованы все параметры при вычислении каждого токена, тогда как модели с экспертным выбором (Mixture-of-Experts, MoE) активируют лишь подмножество параметров, что снижает нагрузку и энергозатраты на единицу токена. Калькуляция энергопотребления генерации токена из научных данных Чтобы определить точное количество энергии, затрачиваемой на генерацию одного токена, исследователи используют методы вычисления количества операций с плавающей точкой (FLOPs) и принимают во внимание эффективность аппаратного обеспечения и особенности инфраструктуры дата-центров. Основной формулой является: энергия = 2 × активное количество параметров × число токенов × коэффициент эффективности железа, выраженной в FLOPs на джоуль.
Здесь активные параметры — те, которые реально задействуются в вычислениях для генерации конкретного токена. Важно отметить, что учитываются не все параметры модели одновременно, особенно для MoE. Например, по расчетам для модели Kimi K2 с 32 миллиардами активных параметров и общим числом параметров в 1 триллион во время генерации миллиона токенов потребляется около 0,016 киловатт-часов энергии, что эквивалентно примерно 1,6 × 10⁻⁸ киловатт-часа на токен. Этот уровень потребления соответствует очень низким затратам энергии на отдельный токен при использовании современных аппаратных решений, таких как NVIDIA H100, с высокой эффективностью порядка 6,59 × 10¹¹ FLOPs на джоуль. Учет инфраструктуры дата-центра также критически важен из-за понятия PUE — Power Usage Effectiveness, характеризующего эффективность использования энергии.
Средние показатели PUE около 1,2 означают, что на охлаждение и работу систем, отличных от вычислительных, уходит порядка 20% дополнительной электроэнергии. Кроме того, энергетическая цена сильно зависит от места расположения серверов. В разных регионах углеродная интенсивность сети, или количество выбросов CO₂ на киловатт-час (кг CO₂/kWh), варьируется. Например, для датцентра Google в US-central1 это около 0,243 кг CO₂/kWh. Именно поэтому даже при одинаковом энергопотреблении уровень углеродных выбросов отличается в зависимости от источников энергии, используемых в конкретном регионе.
Экологические последствия и углеродный след производителей LLM Вычисление углеродных выбросов строится на умножении потребленной энергии на региональную углеродную интенсивность. Для упомянутой модели Kimi K2 за миллион сгенерированных токенов выбросы составляют менее четырех граммов CO₂, что по сравнению с традиционными цифровыми операциями является вполне приемлемым уровнем. Однако, учитывая масштабы глобального использования ИИ, эти небольшие показатели в сумме могут накапливаться до значительных значений. Для сравнения, обучение крупных языковых моделей и проведение больших инференсов требуют значительно больше ресурсов, особенно при выполнении миллионов или миллиардов запросов ежедневно. Развитие аппаратуры и оптимизация головных вычислений направлены на снижение энергозатрат и воздействия на климат.
Тенденции снижения энергопотребления и стоимости инференса Большинство современных разработок уделяют особое внимание снижению энергопотребления без потери качества результата. Технологические улучшения включают переход на вычисления с пониженной точностью, например, FP16 или FP8, которые повышают эффективность работы оборудования в 2 и 4 раза соответственно. Такие оптимизации позволяют выполнять больше операций на джоуль энергии, снижая тем самым общий расход. Кроме того, модели с использованием Mixture-of-Experts архитектуры снижают энергозатраты на токен, так как не все параметры задействованы одновременно. В реальных условиях затраты будут выше из-за нагрузки на память и дополнительного маршрутизирования, но общая тенденция — уменьшение энергетической стоимости.
Другой важный фактор — выбор дата-центров в регионах с низкой углеродной интенсивностью. Переход на возобновляемые источники энергии и развитие «зеленых» дата-центров снижают общий углеродный след. Финансовый аспект включает стоимость электроэнергии, которая варьируется от нескольких центов до более полуметра доллара за киловатт-час в зависимости от страны и поставщика. Для одного миллиона токенов при среднем американском тарифе ($0.152 за kWh) цена энергетических затрат на инференс может составлять около 0.
0025 доллара. Это очень низкий показатель, который подтверждает экономическую доступность современных моделей. Практические рекомендации для разработчиков и пользователей Специалисты должны учитывать энергетические и экологические последствия при проектировании и развертывании моделей ИИ. Использование аппаратно оптимизированных библиотек, переход на более эффективные платформы и расчет углеродного следа на разных этапах жизненного цикла модели позволяют сделать цикл инференса устойчивым и экономически выгодным. Пользователи же должны понимать, что запросы, использование сложных моделей и непрерывный поток информации — это не только вопрос вычислительной мощности, но и энергетических ресурсов, влияющих на окружающую среду.