В современном мире обработки данных и машинного обучения скорость и эффективность вычислений играют ключевую роль. С увеличением объема данных и сложности моделей возникает необходимость искать более производительные инструменты и подходы. На фоне популярности библиотеки Pandas, широко используемой для анализа и обработки данных в Python, появился конкурент, предлагающий значительно более высокую скорость – это Polars. В моей работе с алгоритмом Reduced Columb Energy (RCE) освоение Polars позволило увеличить скорость выполнения в 25 раз, что открыло новые горизонты для обработки больших и сложных наборов данных. Reduced Columb Energy (RCE) – это достаточно специализированный классфикатор, отличающийся от популярных алгоритмов, таких как K-Nearest Neighbors.
В основе RCE лежит идея построения «hit footprint», или ударного следа, для каждого класса. Алгоритм обрабатывает пространство признаков, строя вокруг каждой обучающей выборки сферу с радиусом, определенным расстоянием до ближайшей точки противоположного класса. В результате каждая сфера состоит из радиусов, называемых «лямбдами», которые играют ключевую роль при классификации новых наблюдений. Основное отличие RCE заключается в классификации наблюдений не на основе расстояния до ближайшего соседа, а путем проверки, входит ли наблюдение в сферу и тем самым «попадает в ударный след» определенного класса. Такой подход особенно полезен при работе с ограниченными объемами данных, поскольку отражает пространство классификации более точно, чем традиционные методы.
Первоначально реализация RCE выполнялась с использованием Pandas и применением лямбда-функций для построчной обработки данных. Такой функциональный стиль программирования, который основан на использовании метода apply, создает необходимую читаемость и гибкость. Однако, когда речь заходит о масштабировании и производительности, применение лямбда-функций в Pandas часто становится слабым местом из-за отсутствия эффективной параллелизации и высокого времени обработки. Polars предлагает иной подход с выраженным упором на колоночные операции и параллелизм. В отличие от Pandas, где применение пользовательских лямбда-функций ограничивает возможности многопоточной обработки, Polars рекомендует использовать собственный Expression API.
Это позволяет вести вычисления на более низком уровне, используя параллельные вычисления, строящиеся на основе Apache Arrow, а также оптимизированную архитектуру «близко к металлу». Благодаря этому было возможно перевести алгоритм RCE на Polars и добиться радикального ускорения выполнения без потери точности. Ключевой технической задачей при переходе стало инициативное использование кросс-джойнов - подхода, при котором каждый элемент обучающего набора комбинируется с каждым элементом из противоположного класса, что позволяет эффективно вычислить расстояния между точками без необходимости сложных вложенных циклов. В результате преобразований формируется большой датафрейм, в котором каждому наблюдению сопоставлено множество расстояний до противоположных классов. На основании этого затем производится вычисление минимальных расстояний и определение лямбда радиусов.
Так как Polars реализует операции в колонковом формате, то вычисления над столбцами выполняются быстро и параллельно, что значительно сокращает время обработки. Также стоит отметить, что использование квадратов расстояний вместо обычных расстояний позволяет избежать затрат на вычисление корней в первых этапах, что дополнительно ускоряет процесс. В конце уже применяется извлечение квадратного корня к минимальному значению в группе, для получения итогового радиуса. Переход к реализации классификации с Polars также был связан с применением этого же принципа: создается сетка или грид на основе главных компонент, далее производятся кросс-джойны с обучающей выборкой, просчитываются расстояния до точек обучающей выборки, и определяется, попадает ли точки гридов в hit footprint какого-либо класса. Затем с помощью агрегирующих функций суммируются попадания для каждого класс и выносится итоговое решение по классификации.
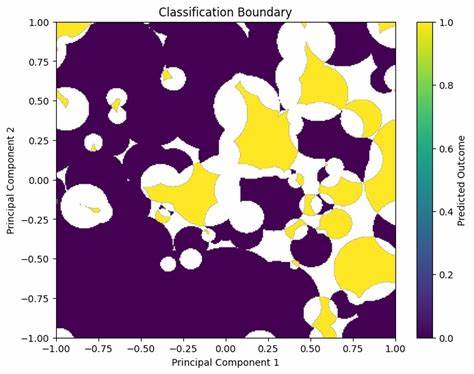
Визуализация полученных результатов в виде тепловой карты показывает четкие зоны принадлежности к классам, что подтверждает эффективность и точность реализованного подхода. Такой тип графика позволяет не только оценивать производительность, но и визуально интерпретировать границы разделения классов – важный аспект для понимания работы алгоритма. Что касается производительности, переход от Pandas к Polars оказался масштабным прорывом. В моем эксперименте общее время обработки на Pandas составило около шести минут, а на Polars — всего 14 секунд. Это означает 25-кратное ускорение, что является крайне значимым результатом для проектов, в которых быстрота анализа данных играет важную роль.
Помимо ускорения, использование Polars уменьшает нагрузку на ресурсы и раскладывает нагрузку по ядрам процессора, эффективно используя современное аппаратное обеспечение. Тем не менее, важно отметить, что такой метод с кросс-джойнами требует достаточно большой объем оперативной памяти, так как размер результирующей таблицы растет квадратично с числом строк исходных данных. Следовательно, для масштабных данных требуется продумывать способы оптимизации по памяти, например, поэтапная обработка данных или использование более продвинутых техники агрегации и отбора признаков. Подытоживая, можно быть уверенным, что соединение мощи колоночных вычислений, параллельных операций и оптимизированных алгоритмов обработки данных в Polars предоставляет весомые преимущества по сравнению с классическими подходами в Pandas. Тем, кто стремится повысить производительность своих проектов и оптимизировать алгоритмы машинного обучения, стоит обратить внимание на Polars и Expression API как на современные инструменты эффективной работы с данными.
Использование Polars раскрывает новые возможности для быстрого прототипирования, масштабирования и анализа данных, делая его ценным выбором для профессионалов в области анализа данных, разработки алгоритмов и исследователей. Развитие и распространение подобных библиотек способствует переходу индустрии к новым стандартам в обработке больших данных и машинном обучении, что открывает широкие перспективы для инноваций и оптимизаций в самых разных сферах.