В современном мире разработки и обработки данных важно иметь инструменты, которые не только облегчают выполнение рутинных задач, но и повышают качество и скорость работы. Databricks-SQL, в сочетании с возможностями GitHub Copilot и протоколом Model Context Protocol (MCP), представляет собой уникальное решение для эффективного взаимодействия с данными в среде Azure Databricks. Этот инновационный подход открывает новые горизонты для разработчиков и аналитиков, позволяя автоматически выполнять SQL-запросы, инспектировать структуры таблиц и сравнивать данные с помощью удобного и интуитивного интерфейса внутри Visual Studio Code. Главной особенностью данного решения является внедрение небольшого, но мощного Python-сервера, который запускается непосредственно в VS Code и предоставляет GitHub Copilot новые возможности для автоматизации и ускорения рабочего процесса. Результат — интеграция трех ключевых функций: выполнение SQL-запросов, тщательное исследование таблиц и сравнительный анализ с прогрессивной выборкой данных через классическую утилиту Unix diff.
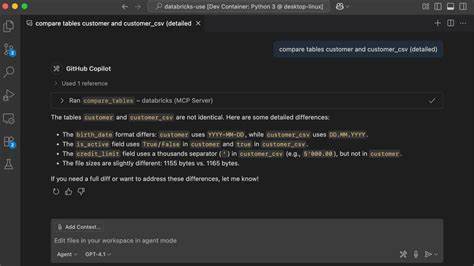
Такое сочетание инструментов позволяет GitHub Copilot гораздо быстрее и точнее понимать различия между таблицами, избегая просмотра огромных объёмов данных вручную. Одним из значимых преимуществ предлагаемого подхода является высокая абстракция, которая становится доступной для Copilot. Вместо получения сырых данных в виде колонок и множества строк, инструмент теперь работает с тщательно сжатым и понятным объединённым диффом, что значительно ускоряет выявление и анализ изменений в данных. Это избавляет специалистов от изнуряющего процесса пролистывания, позволяя гораздо быстрее сосредоточиться на решении стоящих задач. Быстрота обратной связи становится ключевым фактором успешной работы.
Однократное нажатие кнопки «Start» запускает непрерывный цикл обмена данными между GitHub Copilot и сервером, что устраняет необходимость вручную копировать и вставлять запросы или переключаться между различными контекстами. Все операции происходят в рамках единого раунда взаимодействия, что позволяет значительно сэкономить время и сделать процесс работы более плавным и непрерывным. Организация и запуск сервера — довольно простая процедура. Для начала необходимо клонировать репозиторий с исходным кодом, создать виртуальное окружение Python и установить требуемые зависимости. Ключевой момент — подготовка конфигурационного файла MCP, содержащего все необходимые параметры подключения к Azure Databricks, такие как адрес сервера, HTTP-путь, токен доступа и настройки каталога и схемы.
Такой файл легко редактируется прямо в VS Code и обеспечивает быструю интеграцию всех компонентов системы. В конфигурации MCP параметры разделены на отдельные поля с описаниями, что облегчает их понимание и корректную настройку. Значение поля databricks_server_hostname представляет собой адрес рабочей области Databricks без протокола, databricks_http_path — HTTP-адрес доступа к складу данных или кластеру, а databricks_access_token — персональный токен для выполнения SQL-запросов с соответствующими правами. Каталог и схема по умолчанию можно оставить main и default соответственно, либо задать специфичные для вашего проекта параметры. После настройки конфигурации и запуска сервера, в GitHub Copilot становятся доступны четыре основных инструмента, предназначенных для взаимодействия с базой данных.
Это позволяет сразу приступать к выполнению типовых действий, таких как получение информации о структуре таблиц, выполнение запросов и сравнение наборов данных. Пример рабочего цикла включает запрос к Copilot за схемами таблиц, генерацию SQL-трансформации для загрузки одной таблицы в другую, выполнение сформированного запроса и анализ результата через сравнительный дифф. В случае обнаружения несоответствий по типам данных, формату чисел или дат, разработчик имеет возможность оперативно скорректировать запрос и повторно выполнить его без потери времени. Важным техническим аспектом реализации является механизм ограничения выборки в QueryTool, который автоматически добавляет параметр limit если он отсутствует в SQL-запросе. Это предотвращает излишнюю загрузку ресурсов и ускоряет работу с большими таблицами.
TableCompareTool проявляет еще большую изобретательность, создавая временные файлы с различными размерами выборок (5, 25, 100, 500 строк) и прерывая анализ при обнаружении первой значимой разницы. При этом итоговый вывод диффа ограничен десятью строками, что обеспечивает информативность при минимальных временных затратах. Вся конфигурация построена на основе переменных окружения и параметров, введенных через MCP, что облегчает адаптацию к различным условиям и потребностям проектов. Стоит отметить, что реализованное решение выделяется не только своим функционалом, но и масштабируемостью. Добавление дополнительных инструментов и операций, таких как мониторинг задач или аналитика по выполненным процессам, не требует изменений в архитектуре — GitHub Copilot автоматически распознает новые возможности, расширяя полезный арсенал для пользователя.
Такой модульный и гибкий подход позволяет поддерживать высокий уровень абстракции и сохранять контекст работы Copilot чистым и понятным. Эта особенность критически важна для продуктивной работы с большими и сложными проектами, где постоянная загрузка избыточной информации снижает внимание и вызывает утомление. Все исходные коды и документация доступны на платформе GitHub под лицензией MIT, что гарантирует открытость, прозрачность и возможность для сообщества вносить свой вклад в развитие и улучшение инструмента. Это также способствует широкой адаптации и активному обмену опытом между специалистами, работающими в сфере аналитики, развития и автоматизации процессов с данными. В итоге, интеграция Databricks-SQL с GitHub Copilot посредством Model Context Protocol не просто расширяет функционал привычных инструментов, но и трансформирует подход к работе с данными, делая его более интеллектуальным, оперативным и удобным.
Теперь разработчики и аналитики могут с минимальными усилиями управлять сложными вычислительными задачами, ускорять итерации по доработке кода и получать мгновенную и качественную обратную связь. Эта слаженная связка технологий является отличным примером того, как современные разработки помогают раскрыть потенциал искусственного интеллекта в реальных условиях и существенно повысят производительность труда в области обработки больших данных.







