В последние годы большие языковые модели (LLM) стали настоящей революцией в сфере искусственного интеллекта и обработки естественного языка. Их возможности в генерации текста, понимании контекста и выполнении разнообразных задач впечатляют, однако запуск и эффективное использование таких моделей часто связано с существенными аппаратными требованиями, особенно по части видеопамяти (VRAM). Поэтому вопрос—можно ли запустить ту или иную LLM на вашей системе и с какой производительностью—становится крайне актуален. На помощь приходит специализированный инструмент — калькулятор VRAM для LLM, который помогает оценить, насколько выбранное железо справится с задачей инференса, и какой будет скорость генерации текста. Современные калькуляторы VRAM предназначены для разработчиков и инженеров, создающих приложения на базе больших языковых моделей.
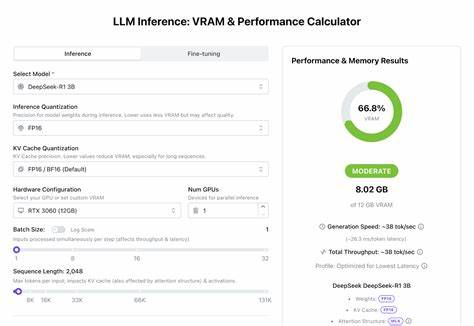
Такие инструменты учитывают множество факторов, влияющих на потребление видеопамяти и вычислительную производительность, позволяя моделировать различные сценарии работы. К ним относятся параметры самой модели: количество параметров, слоев, скрытые размерности и архитектурные особенности, а также особенности инференса, включая точность весов, размер кэш-памяти для ключей и значений (KV Cache), длину входных последовательностей и параметры батчей (batch size). Точность весов—precision—играет ключевую роль. Использование 16-битной (FP16) точности уменьшает нагрузку на VRAM и ускоряет вычисления за счёт меньших объёмов данных, при этом качество результата практически не страдает. Более низкие форматы, например INT8 или INT4 квантование, ещё сильнее экономят видеопамять, но могут повлиять на точность генерации, что особенно важно при критичных задачах.
Аналогично, квантование KV кэша помогает уменьшить объем занимаемой памяти при обработке длинных последовательностей, что актуально для задач с большим числом токенов и сложной логикой внимания. Настройка аппаратной конфигурации в калькуляторе позволяет выбрать конкретную видеокарту из списка или задать пользовательский объём VRAM, что точно отражает возможности системы пользователя. Помимо одной видеокарты, поддерживается указание количества GPU для параллельного инференса, что важно при распределении нагрузки в продакшн-средах и позволяет увеличить пропускную способность. Батч-сайз, то есть число одновременных входов, влияет на скорость обработки и латентность. Большие батчи обеспечивают более высокую пропускную способность, поскольку процессы интенсивнее загружают вычислительные ресурсы, однако расходуют больше видеопамяти, поэтому баланс должен быть подобран с учётом целей проекта и возможностей железа.
Длина последовательности же определяет, сколько токенов в одном запросе может обработать модель, напрямую влияя на размер KV кэша и объём активных данных, участвующих в вычислениях. В современных системах поддерживаются длинные контексты — вплоть до 131k токенов, что значительно расширяет возможности моделей, но требует существенно больше памяти. Кроме того, калькулятор учитывает число одновременных пользователей, что особенно важно для серверных приложений и сервисов с нагрузкой в реальном времени. Моделирование многопользовательской нагрузки помогает понять, как изменятся требования к VRAM и производительности при параллельном обслуживании нескольких клиентов, что позволяет избежать простоев и снижения качества сервиса. Современные оптимизации в инференс-фреймворках также влияют на расчёты.
Например, в обновлениях калькулятора учтены более точные оценки времени до первого токена (Time to First Token), улучшенная балансировка памяти, особенно при offloading (выгрузке части вычислений или данных на CPU, RAM или NVMe), а также специальные алгоритмы для моделей с активными экспертами (Mixture of Experts, MoE), которые традиционно используют больше видеопамяти из-за распределённой архитектуры. Важно понимать, что результаты калькулятора предоставляются в виде приблизительных оценок. Они базируются на обобщённых моделях, benchmark-результатах и математических расчётах, поэтому в реальной среде может быть некоторая разница. Однако, такой инструмент—незаменимый помощник при планировании ресурсов, позволяющий сэкономить время и средства, не приобретая избыточное оборудование или не сталкиваясь с неожиданными проблемами при запуске. Одним из уникальных аспектов использования калькулятора VRAM является возможность экспериментировать с параметрами модели и аппаратными настройками, проводя симуляции перед непосредственной реализацией проекта.
Это позволяет выбрать оптимальный набор параметров для компромисса между производительностью, качеством и затратами. Для разработчиков открытого ПО и энтузиастов существует интегрированный набор утилит, например Python-инструментарий Kerb, который помогает создавать готовые к продакшену LLM-приложения с модульной структурой. Он включает компоненты для retrieval-augmented generation (RAG), агентных систем и генерации структурированных ответов, что значительно упрощает разработку и внедрение моделей. В итоге, использование специализированного калькулятора VRAM для больших языковых моделей—неотъемлемая часть современного подхода к развитию AI-приложений. Этот инструмент помогает принимать обоснованные решения, формировать эффективную архитектуру, а также оптимизировать затраты на оборудование и время разработки.
С учётом постоянных обновлений и новых моделей, такие калькуляторы регулярно адаптируются, учитывая последние достижения в области архитектуры, оптимизации памяти и вычислений. Резюмируя, можно сказать, что грамотное использование VRAM калькуляторов при работе с крупными языковыми моделями открывает путь к успешному внедрению LLM в различные сферы — от чат-ботов и автоматизации клиентской поддержки до научных исследований и креативных индустрий. Владение такими инструментами становится конкурентным преимуществом как для специалистов, так и компаний, стремящихся использовать потенциал искусственного интеллекта на максимуме.