Matrix — децентрализованный протокол с открытым исходным кодом, который позволяет пользователям общаться в реальном времени посредством различных серверов. Одним из самых крупных и важных серверов в этой экосистеме является matrix.org, за которым следит команда Element и Фонд Matrix.org. Недавно команда столкнулась с серьезной проблемой — коррозией индексов в базе данных PostgreSQL, которая привела к поломке множества комнат, а значит, к ухудшению пользовательского опыта и перебоям в коммуникации миллионов людей.
Рассказ о том, как разворачивалась ситуация, какие методы расследования и исправления были применены, а главное, как удалось вернуть сервер к стабильной работе, может быть полезен специалистам и всем, кто интересуется надежностью и высоконагруженными системами. Проблема стала явной, когда пользователи начали сообщать о том, что в комнатах перестали работать базовые операции. Сообщения не отправлялись, новые участники не могли присоединиться, а система выдавала странные ошибки вроде "No create event in auth events". Эта ошибка означала, что сервер не мог найти базовое событие создания комнаты среди ее текущего состояния, а значит не мог дальше нормально работать с такой комнатой. Этот тревожный симптом подтолкнул инженеров к детальному исследованию.
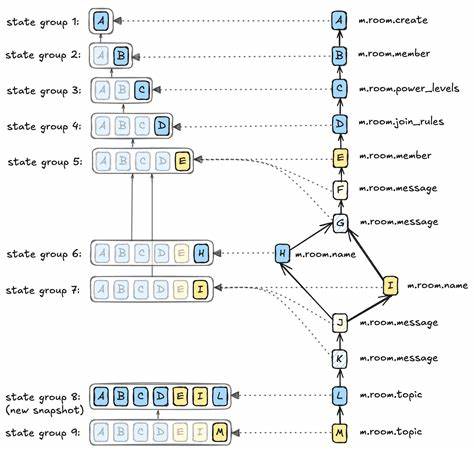
Основой работы Synapse, сервера matrix.org, является огромная база данных PostgreSQL. В ней хранится огромное количество информации о пользователях, событиях и состоянии комнат. Ключевой концепцией, которую важно понять для понимания проблемы, является "state group" — группа состояний. В Matrix изменения внутри комнаты фиксируются событиями, которые либо изменяют текущее состояние (например, пользователь присоединился или поменялся имя комнаты), либо добавляют обычные сообщения.
Чтобы получить актуальное состояние комнаты на момент любого события, сервер хранит объединение изменений, называемое state group. Таким образом, для оптимизации не хранится полная копия состояния каждый раз, а лишь разницы (дельты), кроме некоторых контрольных точек, которые обновляются полностью. Именно в таблицах, отвечающих за хранение state groups и их связей, и проявилась ошибка. Инженеры обнаружили, что некоторые state groups были пустыми, то есть в их состоянии не содержалось обязательного create event. Это фундаментальная часть структуры комнаты, которая должна быть всегда.
Отсутствие этого события приводило к отказу в обработке новых событий для таких комнат и, фактически говоря, к их "сломанности". Расследование продвигалось шаг за шагом. Было важно понять, когда и как появилась коррозия. Анализ логов показал резкий рост ошибок "No create event in auth events" начиная с конца июня 2025 года, однако никаких изменений в коде сервера, которые могли бы вызвать это, не было. Более того, проверка показала, что изначально state groups были корректными, а позже стали поврежденными, что указывало на повреждение данных после их создания, а не на ошибку в программном обеспечении при записи данных.
Общая картина стала проясняться: пострадали данные на хранении — произошла коррозия индекса в PostgreSQL. Коррупция индекса — ситуация, когда «указатели» в структуре индекса перепутались, и запросы, используя индекс, возвращали неправильные результаты — либо отсутствовали данные, либо выдавали чужие записи. В нашем случае индекс в таблице state_groups_state был повреждён. Это означало, что даже если запрос искал состояние конкретной группы, он мог получить неверные данные или вовсе потерять их. Этому мог помочь только ремонт базы, а именно полное восстановление индекса.
Однако напрямую перебилд индекса было сложной задачей — база весила несколько терабайт, поэтому нужна была точная стратегия. Также, к тому моменту часть данных уже была удалена фоновыми задачами очистки, которые удаляли «устаревшие» данные, основываясь на повреждённых индексах. Первым действием стало включение защитных ограничений на уровне базы — была введена проверка, запрещающая удалять состояние для групп, которые все ещё используются в связях с другими группами. Это предотвратило дальнейшее ухудшение ситуации. Отключение и повторное включение фонового процесса очистки дало понимание, что именно этот процесс провоцировал некорректные удаления из-за повреждений индекса.
Дальнейший анализ с использованием tcpdump помог проследить, какие запросы уходят на базу и чьим ошибочным результатом они обрабатываются. Это позволило сузить круг подозреваемых и подтвердить, что причина в базе данных, а не в приложении Synapse или пуле соединений PgCat. Восстановить данные помог резервный бэкап базы от 26 июня 2025 года. Хотя и он содержал проблемы с тем же индексом, наличие времени отката и средства скриптов позволили выявить потерянные записи, которые были ошибочно удалены после повреждения индекса. В этот период производилась внимательная синхронизация и взаимодействие между восстановленными данными и текущей базой.
Применение pg_amcheck и pageinspect (специализированных инструментов для проверки целостности Postgres) показало, что классический инструмент pg_amcheck не всегда способен зафиксировать такую атипичную ошибку — индекс присутствует, но содержит лишние записи, указывающие на неверные позиции в таблице данных. Причина этой коррозии остается загадкой. Самое вероятное предположение — аппаратные ошибки: неисправности на уровне дисков, или встраиваемого контроллера RAID, которые могли повлиять на отдельные фрагменты данных, в частности на индекс. Причем, по удивительному совпадению, повреждения затронули только один крупный индекс, а остальные данные остались почти целыми. Проверки SMART, файловой системы ext4 и средств мониторинга оборудования не выявили явных проблем.
Такая избирательность — редкое, но возможное явление при сбоях дисков. Кроме того, в 2021 году уже фиксировался отказ одного из дисков базы и производилась переадаптация на резервный сервер, что могло внести потенциально скрытые повреждения, накопленные за долгое время. После оценки данных и анализа источников ошибки, команда приступила к постепенному восстановлению индекса, что заняло много времени и ресурсов, учитывая объем базы. Дополнительно был разработан комплексный скрипт, который определял, какие записи были ошибочно удалены, и затем восстанавливал их из резервной копии, что позволило вернуть работоспособность подавляющего большинства комнат. Этот случай стал отличным уроком по нескольким направлениям.
Во-первых, важность мониторинга логов и реакции на неожиданные сообщения об ошибках — именно через них началось расследование. Во-вторых, жизненно необходимо иметь надежную стратегию резервного копирования и восстановления. Без сохранённого бэкапа, вероятно, многие данные были бы утеряны насовсем. В-третьих, сложность и объём базы требует аккуратного подхода к обслуживанию — любые операции по очистке и «оптимизации» данных могут привести к непредвиденным побочным эффектам при скрытых ошибках аппаратуры. Наконец, важным становится поддержка целостности индексов и своевременный аудит с применением специализированных инструментов.
Для пользователей Matrix данный инцидент стал наглядным примером того, насколько важно качественное администрирование инфраструктуры. Этот опыт позволяет и другим крупным проектам, использующим Postgres и хранящим критические данные в больших и сложных структурах, быть готовыми к незапланированным сложностям. Команда Element и Фонд Matrix.org продолжают работать над улучшением стабильности, а также над выявлением и предотвращением подобных проблем в будущем. Они открыто делятся этим кейсом, чтобы помочь профессионалам в сообществе лучше понять тонкости эксплуатации масштабируемых баз данных и сложных систем реального времени.
Таким образом, данный случай напоминает, что современные инфраструктуры — это живой организм, требующий постоянного внимания. Даже качественный и проверенный софт, как Postgres, может столкнуться с нестандартными проблемами из-за аппаратных факторов. Тщательный анализ и системный подход помогают выявлять, локализовывать и исправлять такие сбои, минимизируя ущерб и обеспечивая высокую доступность сервисов. Опыт matrix.org еще раз подтвердил, что важнейшими аспектами при работе с большими базами являются регулярные резервные копии, мониторинг целостности данных, контроль процессов фонового обслуживания и готовность к восстановлению после инцидентов.
А прозрачность и открытость в коммуникации с пользователями помогают сохранить доверие даже в сложных ситуациях.