Современные большие языковые модели (LLM) стремительно меняют сферы науки, технологий и бизнеса. Их способность генерировать контент, вести осмысленный диалог и решать сложные задачи открывает новые возможности для приложений искусственного интеллекта. Однако вместе с ростом качества моделей увеличивается и их вычислительная сложность, а значит и требования к инфраструктуре, необходимой для их работы. В частности, актуальной проблемой становится оптимизация хранения и повторного использования промежуточных вычислительных данных, таких как KV-кэш, который используется для ускорения вывода в трансформерных моделях. На данном этапе развития LLM для повышения производительности и снижения задержек ответов появляется инновационное решение — LMCache, разработанное как расширение движка для обслуживания LLM, работающее по принципу «Redis для LLM».
LMCache кардинально меняет подход к управлению KV-кэшем, делая его более распределённым, доступным и быстрым. KV-кэш (key-value cache) – это структура данных, предназначенная для хранения промежуточных результатов вычислений трансформеров, что позволяет избежать повторной генерации одних и тех же срезов контекста при обработке длинных последовательностей текста. При работе с длинными контекстами, типичными для многораундовых диалогов или сложных запросов, полное пересчитывание модели приводит к значительным задержкам и высокой нагрузке на графические процессоры. В этом контексте LMCache выступает как оптимизирующий слой, способный кэшировать и переиспользовать KV-кэш как внутри одного сервера, так и между несколькими инстансами сервера, делая процесс генерации намного эффективнее. Особенность LMCache – хранение кеша на нескольких уровнях доступной памяти.
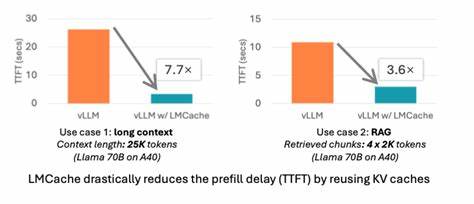
Помимо традиционного GPU-памяти, где хранятся сами веса модели и данные для вычислений, LMCache позволяет выгружать KV-кэш на CPU DRAM и локальный диск. Такая иерархия хранения даёт возможность значительно снизить нагрузку на графическую карту, освобождая ценные GPU-циклы для реальных вычислений вместо повторных запросов однотипных данных. При этом перенос кеша в более дешевые и объемные уровни памяти не приводит к ощутимой потере производительности благодаря эффективным алгоритмам оффлоада и быстрому обмену данными между уровнями. Важной составляющей LMCache стала его тесная интеграция с другим высокопроизводительным проектом – vLLM, ориентированным на масштабируемое и эффективное развёртывание LLM. Совместное использование LMCache с vLLM показывает впечатляющие результаты: сокращение задержек генерации ответа может достигать от трёх до десяти раз, а экономия графических ресурсов существенна уже в реальных сценариях применения, таких как многократные вопросы-ответы и генерация с использованием Retrieval-Augmented Generation (RAG).
Благодаря поддержке пирообразного (peer-to-peer) обмена кешем, LMCache обеспечивает доступ к KV-данным даже между разными инстансами сервиса, что особенно актуально для кластерных и распределённых архитектур. Технологическая основа LMCache позволяет ему поддерживать не только классические ситуации с префиксом текста, который уже генератор обработал, но и более универсальные сценарии сохранения кеша любых частей контекста, что расширяет его применимость в сложных и интерактивных задачах с искусственным интеллектом. Кроме того, наличие многовариантного хранения (CPU, диск, NIXL) делает проект гибким по части инфраструктурных требований и открывает потенциал для использования на самых разных платформах и конфигурациях. Процесс установки и настройки LMCache достаточно прост благодаря распространённой упаковке через pip и детальной документации, сфокусированной на совместимости с Linux-платформами, оборудованными графическими процессорами NVIDIA. Благодаря этому множество команд разработки и исследовательских проектов могут легко интегрировать LMCache в свои экосистемы, получая немедленные преимущества в производительности и стоимости.
В случае более сложных инфраструктурных решений проект предоставляет расширенную документацию с рекомендациями по решению распространённых проблем с зависимостями, что значительно упрощает адаптацию и масштабирование. Сообщество вокруг LMCache активно растёт. Регулярные встречи проходят каждые две недели, во время которых специалисты обмениваются опытом, обсуждают инновации и планы развития продукта. Видео сессий и материалы встреч доступны для всех заинтересованных, что способствует прозрачности и открытому развитию технологии. Инструменты и исходный код проекта доступны на GitHub под лицензией Apache 2.
0, что обеспечивает открытость и возможность участия в развитии продукта. Современные кейсы использования LMCache включают интеллектуальные чат-боты, поисковые системы с расширенным пониманием контекста, генерацию сложных текстов в реальном времени и различные приложения с RAG, где необходимо быстро обрабатывать большие объемы контекстной информации. Высокая эффективность LMCache в сокращении времени первого отклика и общего времени обработки позволяет создавать более отзывчивые и масштабируемые сервисы, что становится конкурентным преимуществом в столь динамичной отрасли. Несмотря на высокую технологичность и сложность, LMCache активно развивается, предлагая решения для предприятия и индивидуальных разработчиков. Дополнительные функции, такие как сжатие кеша, стриминг и расширенные методы оптимизации, изучаются и внедряются совместно с научными публикациями и конференциями, что подтверждает серьёзный академический и практический интерес к данной разработке.