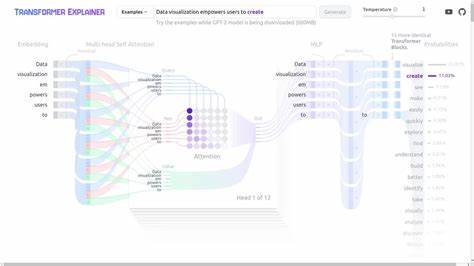
Трансформеры стали настоящей революцией в области обработки естественного языка и искусственного интеллекта в целом. Понимание того, как информация протекает через эти модели, позволяет лучше оценить их мощь и потенциал, а также глубже понять современную архитектуру нейросетей. В основе трансформеров лежит принцип обработки данных, основанный на механизме внимания, который обеспечивает эффективное взаимодействие между различными частями входной информации. Это позволяет трансформерам превосходить традиционные рекуррентные и сверточные нейросети в задачах, связанных с пониманием и генерацией текста, а также с обработкой других видов последовательных данных. Архитектура трансформера состоит из энкодера и декодера, каждый из которых содержит несколько идентичных слоев.
Энкодер отвечает за восприятие входных данных и их преобразование в внутреннее представление, в то время как декодер генерирует выходной сигнал на основе этого представления и ранее созданного контекста. Процесс обработки информации начинается с поступления последовательности токенов - базовых элементов текста. Каждому из них присваивается векторное представление с помощью эмбеддингов, что позволяет модели работать с числовыми данными, а не с сырым текстом. Эти векторы далее проходят сквозь слои трансформера, где каждый из них обогащается дополнительной информацией о взаимосвязях с другими токенами. Ключевым элементом архитектуры является механизм самовнимания (self-attention), который позволяет модели оценивать важность каждого слова в контексте всей последовательности.
Вместо того чтобы обрабатывать слова последовательно, как это делается в рекуррентных сетях, трансформер анализирует всю последовательность сразу, вычисляя весовые коэффициенты, отражающие значимость и влияние каждого токена относительно остальных. Таким образом, модель получает возможность динамически фокусироваться на наиболее существенных элементах входа, что является критически важным для понимания многозначных слов, идиом или контекста. Сам процесс вычисления внимания начинается с преобразования входных векторов в три новых представления: запросы (queries), ключи (keys) и значения (values). Запросы и ключи используются для вычисления весов внимания с помощью скалярных произведений, которые затем нормализуются с помощью функции softmax, обеспечивая вероятностное распределение. Эти веса применяются к значениям, что в итоге формирует выходные векторы, содержащие информацию, релевантную данному контексту.
Благодаря параллельной обработке всех токенов, трансформеры достигают высокой эффективности и качества работы. Многочисленные слои внимания и последующие слои нормализации и полносвязной обработки помогают модели углублять и уточнять представление информации. В каждый слой добавляются остаточные связи, которые помогают сохранять исходную информацию и обеспечивают стабильность обучения. В итоге трансформер создает высокоуровневое контекстуальное представление, которое можно использовать для различных задач - от машинного перевода и анализа тональности до генерации текста и ответов на вопросы. Кроме того, мультиголовное внимание - еще один важный компонент, позволяющий модели одновременно фокусироваться на различных аспектах входных данных.
Каждая 'голова' внимания обрабатывает представление задачи с разных "углов", что значительно обогащает итоговое векторное представление и расширяет способности модели к распознаванию сложных паттернов и взаимосвязей. Трансформеры также используют позиционное кодирование, поскольку их архитектура не учитывает порядок слов в последовательности напрямую. Позиционное кодирование добавляет информацию о положении каждого токена, что позволяет модели различать разные последовательности и учитывать структуру предложений. Это повышает качество интерпретации контекста и грамматических конструкций. Понимание прохождения информации через трансформер дает возможность лучше разбираться в том, как современные модели машинного обучения справляются со сложными задачами, требующими учета контекста и масштабирования на большие объемы данных.
Эти знания особенно важны для разработчиков, исследователей и специалистов по данным, работающих в области искусственного интеллекта и аналитики. Таким образом, поток информации через трансформеры - это сложный и многоступенчатый процесс, объединяющий эмбеддинги, механизм внимания, остаточные связи и позиции, который обеспечивает качественную обработку и генерацию текстовых данных. Современные достижения в области трансформеров продолжают менять подходы к решению задач в самых разных сферах, делая их еще более эффективными и интеллектуальными. .







