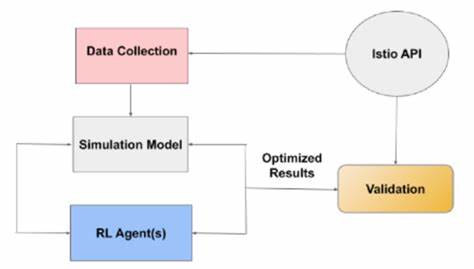
В условиях стремительно развивающихся технологий и роста числа киберугроз исследователи и специалисты по информационной безопасности все чаще обращаются к моделям искусственного интеллекта, способным обучаться и адаптироваться в динамичной среды. Одним из наиболее перспективных направлений является применение методов обучения с подкреплением (Reinforcement Learning, RL) для создания агентов, участвующих в симуляциях кибербоевых сценариев. Такие платформы позволяют изучать взаимодействия между защитными и атакующими агентами в контролируемом и воспроизводимом окружении, что способствует выявлению сильных и уязвимых сторон защитных систем. Важной задачей становится интерпретация поведения этих агентов, которая помогает не только понимать причины их успехов и ошибок, но и улучшать алгоритмы и стратегии в будущем. Обучение с подкреплением основывается на том, что агент самостоятельно изучает оптимальные действия в среде, получая отзывы в виде наград или штрафов.
В контексте кибербезопасности такие агенты могут представлять собой программы, которые защищают сеть от атак либо, наоборот, действуют как атакующие, пытаясь проникнуть в систему и получить контроль. Это создает уникальную возможность для анализа сложного и разнообразного поведения в условиях противоборства. Одной из ключевых проблем в понимании работы RL-агентов в киберсимуляторах является высокая сложность состояния среды и разнообразие возможных действий. Чтобы получить удобочитаемые и полезные сведения об эффективности агентов, исследователи предлагают упрощать состояния и действия, выделяя важнейшие события — такие как успешное проникновение, обнаружение угрозы, применение защитных мер и восстановление систем после атаки. Анализ этих событий позволяет выявить закономерности и оценить, насколько оперативно и эффективно агент реагирует на угрозы.
Для примера можно рассмотреть кейс с открытыми агентами, участвовавшими в состоявшемся киберзащитном соревновании CAGE Challenge 2. В нем агенты защищали имитационную сеть от ряда правил-основанных атакующих программ. Детальный разбор их работы показал, что защитные агенты чаще всего успешно обнаруживали и устраняли проникновения в течение одного-двух временных шагов после эксплуатации хоста. Такое быстродействие критично для сохранения целостности сети и минимизации ущерба. Дополнительно важно анализировать эффективность конкретных действий агентов.
Например, исследования показали, что некоторые защитные меры оказываются малоэффективными – в 40–99% случаев они не приводят к положительному результату. Эти данные крайне ценны для оптимизации стратегий: зная, какие меры редко приносят результат, можно сосредоточиться на разработке более действенных технологий и алгоритмов. Интересным элементом защиты в киберсимуляторах являются ловушки или «декои» — имитации уязвимых сервисов, создаваемые для отвлечения и выявления атакующих. Анализ показал, что применение таких ловушек способно блокировать до 94% попыток эксплуатации, направленных непосредственно на получение прав доступа к важным узлам. Это подчеркивает важность интеграции многослойных подходов к защите, где не только прямое реагирование, но и психологические и тактические уловки играют роль в срыве атакующих планов.
Одновременно с этим эксперты обсуждают степень реалистичности подобных испытательных площадок. Изначальные версии CAGE Challenge демонстрировали определенные ограничения, связанные с моделированием поведения атакующих и защитных систем. В последующих итерациях, таких как CAGE Challenge 4, предприняты шаги по улучшению соответствия симуляций реальным киберугрозам, что расширяет возможности для более точного и полезного анализа агента и улучшения методов защиты. Понимание поведения RL-агентов в киберсимуляторах дает аналитикам надежные инструменты для оценки эффективности применяемых стратегий и выявления путей для их совершенствования. Кроме того, такой подход облегчает интерпретацию сложных процессов, что традиционно было серьезной проблемой при работе с алгоритмами глубокого обучения и обучение с подкреплением.
Развитие кибербоевых симуляторов с использованием обучающихся агентов способствует также подготовке специалистов по кибербезопасности, позволяя им оттачивать навыки реагирования в безопасных условиях. Разработчики систем защиты могут экспериментировать с новыми методами без риска для реальных инфраструктур, выявляя потенциальные уязвимости и улучшая протоколы. Таким образом, выпускники и практикующие специалисты в области информационной безопасности, а также исследователи искусственного интеллекта, находят ценность в подобных исследованиях, которые объединяют методы машинного обучения, кибербезопасности и симуляционного анализа. Такой междисциплинарный подход открывает перспективы для создания более адаптивных, устойчивых и эффективных систем защиты в условиях постоянно меняющейся угрозы. Стоит отметить, что данная область продолжает активно развиваться, и с каждым новым выпуском симуляционных платформ и совершенствованием алгоритмов RL, понимание поведения агентов становится все более глубоким.