Развитие технологий машинного обучения и, в частности, больших языковых моделей (LLM) привело к беспрецедентному росту возможностей искусственного интеллекта. Вместе с тем, возникла новая проблема — необходимость разучивания или удаления определённых данных и функций из моделей. Эта задача важна по причинам конфиденциальности, безопасности и соответствия законодательству, а также для управления поведением ИИ систем после их обучения. Однако современные методы разучивания оказываются весьма уязвимы и легко нивелируются повторным дообучением модели на тех же данных. Такой сценарий ставит под сомнение эффективность всех попыток достоверно удалить информацию из модели без её полной переобучения.
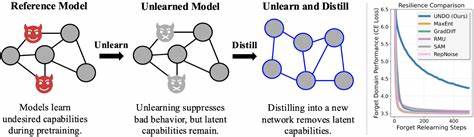
Одним из интереснейших направлений исследований в этой области стала концепция дистилляции, то есть переноса знаний с одной модели на другую. При традиционной дистилляции обучается «студенческая» модель на основе выводов «учительской» модели. Но именно этот подход, если его умело применить, может стать решающим фактором для создания надежного процесса разучивания. Исследования показывают, что обучение студента, случайно инициализированного, на имитацию модели, из которой уже была удалена нежелательная информация (unlearned model), позволяет «перенять» самые важные и полезные способности, при этом не копируя удалённые или нежелательные свойства. Это значит, что дистилляция само по себе робустит, то есть укрепляет процесс разучивания.
В основе этих исследований лежит идея, что finetuning - дообучение на основе вывода модели (output) — недостаточно эффективно для усиления удаления информации. Даже идеальные методы, направленные на имитацию не содержащей неизвестных данных модели (oracle model), становятся неустойчивы, если на них суётся дополнительное дообучение. Но дистилляция, когда студент обучается именно воспроизводить поведение уже разученной модели, обеспечивает качественный отбор полезных знаний, не копируя нежелательного. На этом фундаменте появилась новая методика — Unlearn-Noise-Distill-on-Outputs (UNDO). Она сочетает дистилляцию с введением специально сгенерированного шума в копию модели для усиления надежности разучивания.
UNDO позволяет балансировать между затратами на вычислительные ресурсы и степенью устойчивости к отмене разучивания, предлагая гибкий и практичный инструмент для реализации надежной фильтрации знаний. Преимущества UNDO очевидны — метод достигает уровня устойчивости, сравнимого с абсолютным переобучением модели с идеально отфильтрованными данными, но затрачивает при этом значительно меньше ресурсов — до 60-80% от требуемых при традиционном методе, и требует минимального количества размеченных данных, всего около 0,01% всей выборки. Это открывает дорогу для широкого применения в индустрии, где переобучение больших моделей зачастую оказывается непомерно дорогим с точки зрения времени и вычислительных затрат. Важно отметить, что надежность UNDO не ограничивается абстрактными тестовыми задачами вроде синтетического языка или арифметики. Метод показал свою эффективность на реальных сложных проблемах, таких как Weapons of Mass Destruction Proxy (WMDP), что служит убедительным доказательством его практической применимости и ценности для реальных систем безопасности.
В сфере невозможности полностью избавиться от информации древними методами, дистилляция предлагает элегантный способ реструктуризации знаний модели. Вместо прямого удаления данных, она помогает «перебрать» и переобучить модель так, чтобы нежелательные поведения естественным образом не передавались новым версиям. Таким образом процесс разучивания приобретает устойчивость к «откату» и попыткам восстановить удалённые данные. С технической точки зрения, дистилляция в контексте разучивания основана на том, что суррогатная модель студента обучается не на исходных данных, а на выходах ранее разученной модели. При этом добавление шума в процесс обучения усиливает защиту от обратного внедрения нежелательных знаний.
Разработчики могут управлять уровнем шума и другими параметрами, оптимизируя соотношение между вычислительной эффективностью и степенью надежности удаления. Общий тренд показывает, что традиционные идеалы разучивания, подразумевающие полное удаление информации через фильтрацию данных и ретренинг, уступают новому подходу, который балансирует эффективность и практичность. UNDO создаёт новый фронтир в модели компромисса, позволяя добиваться высококачественного разучивания при меньших издержках. С практической точки зрения для организаций, которые заинтересованы в защите пользовательских данных, соблюдении нормативов и быстрой адаптации моделей к новым требованиям, путь через дистилляцию и метод UNDO становится невероятно перспективным. Этот подход интегрируется в стандартный цикл разработки и поддержки машинного обучения, поскольку дистилляция уже широко используется в индустрии для облегчения и ускорения разработки компактных и эффективных моделей.
В итоге, дистилляция не просто помогает создавать более эффективные студенческие модели. Она трансформирует саму парадигму разучивания, делая этот процесс более надежным и управляемым. В условиях, когда все больше внимания уделяется этичности, безопасности и контролю за ИИ, такие решения как UNDO открывают новые горизонты для безопасного и ответственного использования современных моделей. Подводя итог, можно сказать, что дистилляция стала ключевым механизмом в достижении устойчивого разучивания, способным противостоять попыткам отмены удаления данных. В сочетании с инновационными подходами, такими как внесение шума и тонкая настройка параметров, она обеспечивает эффективное решение проблем, которые долгое время оставались нерешёнными.
В будущем можно ожидать дальнейшего развития этой методики, что позволит не только безопасно управлять знаниями в моделях, но и создавать более надежные и адаптивные системы искусственного интеллекта.