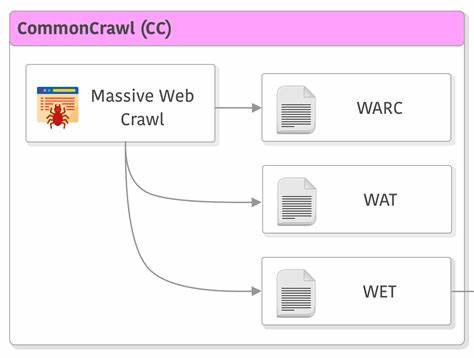
В современном цифровом мире данные являются основой множества технологий, включая искусственный интеллект, машинное обучение и обработку естественного языка. Common Crawl – это одна из крупнейших открытых баз веб-документов, которую исследователи и разработчики по всему миру используют для обучения своих моделей. Однако в силу исторических и технических причин, большая часть собранных данных сосредоточена на английском языке, оставляя сотни других языков значительно недопредставленными. Такая диспропорция препятствует развитию технологий для немногих, создавая неравные возможности в доступе к инновациям. Именно поэтому важна инициатива Common Crawl по расширению языкового охвата, которая приглашает к сотрудничеству активных участников и носителей различных языков.
Вызов, который стоит перед Common Crawl, заключается в том, чтобы собрать релевантные, качественные и разнообразные данные на множестве языков, включая редкие и региональные. Эти данные помогут улучшить модели и приложения, направленные на понимание и генерацию текста на разных языках. Открытый характер Common Crawl способствует демократизации доступа к данным, предоставляя возможность исследователям, разработчикам и компаниям создавать более справедливые и инклюзивные технологии. Для достижения этой цели эксперты Common Crawl предлагают простые, но эффективные способы участия каждому, кто владеет языком, отличным от английского. Во-первых, идет работа над проверкой автоматической идентификации языка текста.
Данные LangID или LID – это подсистема, которая определяет, на каком языке написан фрагмент текста. Точность таких систем критична для того, чтобы не пропустить материалы на других языках и избежать смешения языков в данных. На платформе Dynabench открыта задача по валидации и улучшению языковой идентификации, где участники могут проверить и скорректировать результаты автоматического определения языка. Такая работа способствует увеличению точности языковой классификации. Во-вторых, пользователи могут внести свой вклад, предлагая ссылки на веб-сайты и страницы на разных языках для включения их в исходный набор данных – так называемые seed URLs.
На GitHub-репозитории Common Crawl создана специальная площадка, где сообщество может добавлять адреса сайтов, представляющих различные культуры, регионы и языки. Это позволяет поисковым роботам охватить более широкий спектр контента и собрать данные, которые отражают многообразие человеческого опыта. Помимо непосредственного сбора и валидации данных, Common Crawl совместно с такими организациями, как MLCommons и EleutherAI, организует специализированные мероприятия для обмена знаниями и стимулирования научного сообщества. Одним из таких проектов является Workshop on Multilingual Data Quality Signals (WMDQS) – воркшоп, посвященный анализу и улучшению качества многоязычных данных. В рамках этого мероприятия открыт призыв к подаче научных работ, в которых исследователи могут представить свои методы и подходы к оценке и обработке мультиязычных наборов данных.
Также в рамках WMDQS планируются конкурентные задания, например, shared task по языковой идентификации. Такие соревнования способствуют развитию передовых алгоритмов и тестированию их эффективности на реальных данных, собранных с помощью Common Crawl. В результате сценариев сотрудничества и соревновательности повышается качество инструментов, доступных всему сообществу. Особое значение имеет мультикультурный и многоязычный подход, ведь качество данных напрямую зависит от разнообразия источников и внимательности к специфике каждой языковой группы. Когда языковые данные неполные либо искажённые, технологии могут неправильно интерпретировать текст, создавать ошибочные результаты и плохо справляться с задачами локализации и адаптации.
Расширение охвата языков и культур способствует созданию более универсальных моделей, способных работать в глобальном масштабе и учитывать уникальные особенности каждого языка. Таким образом, участие сообщества в проекте Common Crawl – это не только способ внести вклад в развитие широкой базы знаний, но и возможность продвинуть технологии искусственного интеллекта в своем регионе и на родном языке. Носители языков могут обеспечить, чтобы культура и знания их народов были представлены справедливо и полноценно в цифровом пространстве. Для тех, кто заинтересован в участии, процесс прост и доступен. Регистрация и участие в проверке языковой идентификации на платформе Dynabench не требует специальных технических знаний, а размещение URL на GitHub предоставляет возможность рекомендовать ценные источники своего региона.
Кроме того, участие в научных и технических мероприятиях WMDQS открывает дверь к обмену опытом с мировыми экспертами и получению новых знаний в области многоязычной обработки данных. Инновации в области искусственного интеллекта и обработки естественного языка во многом зависят от качества и разнообразия исходных данных. Расширение языкового покрытия Common Crawl является шагом к созданию более демократичных и инклюзивных технологий, которые будут служить всему человечеству вне зависимости от того, на каком языке оно говорит. Именно благодаря таким инициативам возможно формирование цифрового мира, где каждый голос будет услышан, а каждая культура достойно представлена. В будущем дальнейшее развитие проектов по сбору и анализу многоязычных данных позволит создавать интеллектуальные системы с глубоким пониманием глобального разнообразия, открывая новые возможности для образования, науки и бизнеса.
Поэтому участие каждого, кто владеет языком, отличным от английского, становится важным вкладом в общую цель – сделать искусственный интеллект по-настоящему универсальным и полезным.