В последние годы трансформерные модели стали фундаментом многих достижений в области обработки естественного языка и машинного обучения. Их способность эффективно справляться с задачами генерации текста, перевода и анализа стала революционной. Однако использование таких моделей часто связано с традиционными языками программирования и фреймворками, как Python и TensorFlow или PyTorch. В то же время язык Rust, славящийся своей производительностью, надежностью и безопасностью памяти, начинает активно применяться в области машинного обучения. В этой статье мы рассмотрим проект по реализации и обучению трансформера и токенизатора на Rust с помощью библиотеки tch-rs, а также исследуем ключевые особенности и лучшие практики работы с этими технологиями.
Rust и tch-rs: мощное сочетание для машинного обучения Rust завоевывает популярность среди разработчиков благодаря способности обеспечивать безопасность и высокую производительность без излишних накладных расходов. Его система владения памятью исключает целый класс ошибок, что важно при работе с крупными моделями и данными. Однако до недавнего времени число инструментов для машинного обучения на Rust было ограничено. Появление библиотеки tch-rs, которая выступает в качестве обертки над libtorch — C++ библиотекой PyTorch, существенно расширило возможности Rust в этой сфере. Теперь можно разрабатывать, обучать и запускать нейросетевые модели, не отходя от экосистемы Rust.
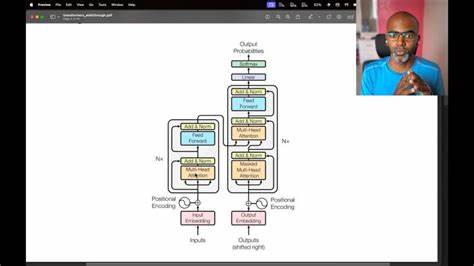
Реализация трансформера в Rust Трансформер — архитектура, основанная на механизме внимания (attention), которая заменяет традиционные рекуррентные сети и свёрточные модели в задачах обработки последовательностей. В представленном проекте основное внимание уделено реализации казуального декодерного трансформера — модели, которая умеет генерировать текст, предсказывая следующий токен на основе предыдущих. Код строится в основном на Rust, что обеспечивает низкоуровневую оптимизацию и контроль, а также интеграцию с tch-rs для работы с тензорами и обучением модели. Интересной особенностью является большое количество dropout-слоёв (четыре на блок), что помогает улучшить обобщающую способность модели и избежать переобучения. Также применяется Layer Normalization до механизмов внимания и feed-forward слоёв, что улучшает стабильность обучения и качество результата.
Модель состоит из нескольких блоков, каждый из которых содержит мультиголовный аттеншн и feed-forward нейросети с нелинейностями. Такой подход следует современным рекомендациям и практикам, например, использует pre-LN структуру и residual dropout, позволяющую добиться высокой эффективности даже при относительно небольшой модели. Токенизация с использованием BPE Токенизация — важнейший этап подготовки данных для обучения языковой модели. В проекте используется алгоритм Byte Pair Encoding (BPE), который эффективно сжимает частые последовательности символов или подслов в токены, помогая модели лучше обрабатывать и генерировать текст. Особенностью токенизатора является обработка пробелов и ограничения на объединение токенов только внутри слов, что сохраняет лингвистическую структуру и улучшает качество токенов.
Результат токенизации сериализуется в формате RON (Rusty Object Notation), что упрощает дальнейшую загрузку и работу с данными. Работа с датасетами и обучение модели В проекте используется датасет tinystories-10k, содержащий короткие истории для обучения. Формат parquet позволяет эффективно хранить и обрабатывать наборы данных. В первую очередь происходит токенизация текстов, после чего создаётся токенизированный датасет, подходящий для обучения трансформера. Обучение производится с помощью оптимизатора AdamW, одного из стандартов современного глубокого обучения, который обеспечивает правильную настройку весов с учётом регуляризации.
В проекте реализован простой цикл обучения без сложных планировщиков скорости обучения, однако в отдельной ветке доступна реализация с линейной разгонкой и косинусным спуском, помогающая улучшить финальноe качество модели. Особого внимания заслуживает возможность обучения на MPS для владельцев устройств Apple с ARM-чипами, что значительно ускоряет процесс обучения без необходимости прибегать к внешним GPU. Генерация текста и использование модели После обучения можно использовать модель для генерации текста, задавая начальный ввод и контролируя длину и температуру генерации — параметры, влияющие на креативность и разнообразие выдаваемого текста. Возможность задавать начальное слово или фразу позволяет применять модель для различных креативных и практических задач. Пример сгенерированного текста демонстрирует способности модели создавать связные и осмысленные рассказы из небольшого начала, что свидетельствует о качестве и достаточной мощности трансформера, несмотря на компактность его архитектуры.
Анализ проекта и перспективы Проект демонстрирует, что Rust можно эффективно использовать для работы с современными архитектурами глубокого обучения, включая трансформеры, что открывает новые возможности для разработчиков, ищущих производительные и безопасные инструменты вне привычных Python-фреймворков. Одним из преимуществ является явная архитектура кода с подробными комментариями, что помогает новичкам понять основные принципы работы трансформеров и механизмов токенизации. Также важно отметить, что проект создаёт основу для дальнейших экспериментов с более продвинутыми методами обучения и оптимизации, включая кастомные конфигурации моделей и стратегий тренировки. Выводы Реализация и обучение трансформеров и токенизаторов на Rust — перспективное направление для развития инструментов NLP и машинного обучения. Использование tch-rs позволяет объединить высокопродуктивную и безопасную среду Rust с мощью PyTorch, сохраняя при этом гибкость и масштабируемость.
Данный проект служит не только примером технической реализации, но и вдохновляет на создание новых, оптимизированных моделей и приложений, способных работать быстро и эффективно на различных платформах, включая устройства с ограниченными ресурсами. Использование Rust в области ИИ обещает значительный рост и интеграцию с системным и прикладным программированием, что открывает новые горизонты в разработке программного обеспечения и искусственного интеллекта.