Humanity’s Last Exam (HLE) — одна из самых амбициозных и сложных оценочных систем, созданных для проверки знаний на уровне PhD в различных научных дисциплинах, включая химию и биологию. Впервые представленный как новый стандарт оценки интеллектуальных возможностей и глубины знаний, этот экзамен нацелен на решение проблемы, связанной с устаревшими и «перепробованными» тестами, которые не способны выделить лучших из лучших. Тем не менее, недавно опубликованное исследование, проведенное командой FutureHouse во главе с Михаилом Скарлински и коллегами, показало, что около 30% вопросов в разделах химии и биологии имеют ответы, которые противоречат проверенным научным данным. Эта новость вызвала широкий резонанс в научном и AI-сообществах, заставляя задуматься о качестве подобных benchmark-тестов и перспективах их применения в будущем. HLE был разработан как ответ на феномен насыщения классических эвалюационных тестов, например, MMLU, в которых передовые модели искусственного интеллекта смогли достичь уровня точности более 90%.
Humanity’s Last Exam задумывался как более строгий вызов — набор из 2500 вопросов с высокой сложностью, большая часть которых не поддается правильному ответу даже современными продвинутыми языковыми моделями. По состоянию на середину 2025 года лучшая модель, Grok4, смогла показать лишь 26,9% правильных ответов при изоляции и 44% при использовании дополнительных инструментов и доступа к интернету. Однако при близком изучении biology и chemistry подсетов этого экзамена выявилась серьезная проблема. Основная причина, по мнению авторов анализа, кроется в методологии создания самого теста. Для разработки вопросов использовались критерии, среди которых был запрет на задачу вопросов, на которые могут ответить топовые языковые модели.
В результате возникли многочисленные «ловушки» с подвохами, а некоторые вопросы были составлены настолько искусственно и запутанно, что даже эксперты терялись в оценках их корректности. Один из ярких примеров — вопрос о том, какой благородный газ был самым редким на Земле в 2002 году. Экзамен предложил ответ «Оганесон», искусственный сверхтяжелый элемент, существующий лишь доли секунды и не являющийся газом в привычном понимании. При этом официальная научная литература указывает, что оганесон, скорее всего, является твердым веществом, с химическими свойствами, далекими от классических благородных газов, и уж точно не присутствует в земной коре. Такие ошибки — не единичны.
Вспомним вопрос об ампуле с одноразовой дозой лекарственного препарата и времени ее безопасного использования. Ответом в экзамене стал лимит в один час с момента вскрытия, что не соответствует рекомендациям фармакопей и экспертам в области стерильных препаратов. Фактически, ампулу рекомендуют использовать сразу после вскрытия, и установка фиксированного ограничения вводит в заблуждение и может быть вредна с точки зрения практики. Аналогично, вопрос о рационе питания насекомых из отряда Рафидиоптер (змеиные мухи) вызвал споры. Согласно экзамену, представители питаются нектаром.
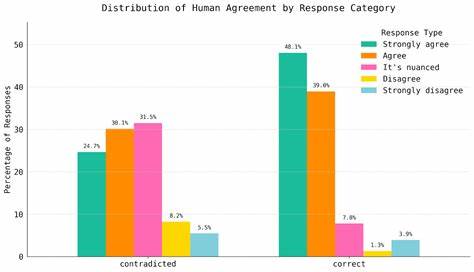
Однако в научных обзорах и исследованиях достоверных данных о таких наблюдениях нет — эти насекомые известны как хищники, и их питание крайне редко включает нектар, что делает утверждение экзамена сомнительным. Подобные примеры подчеркивают серьезность проблемы. Анализ команды FutureHouse опирался как на автоматизированные инструменты поиска сопоставлений с научной литературой, так и на опыт независимых экспертов в области химии и биологии. Результаты показали, что более половины рацианалей к вопросам тескста непосредственно противоречат публикациям и исследованиям, а около 29% вопросов, возможно, содержат ошибки на уровне утверждений или предположений. Важно отметить, что процесс сверки вопросов и ответов в HLE был достаточно особым.
Проверяющим выдавалось ограниченное время — не более 5 минут на оценку каждого вопроса, а главным критерием отборов было убедиться, что машины на передовом уровне не смогут правильно ответить. Верификация работоспособности и достоверности объяснений отодвигалась на второй план. Такая методология объективно могла привести к появлению вопросов, которые не соответствуют реальным научным данным и вводят в заблуждение даже специалистов с профильным образованием. Ответ разработчиков HLE не заставил себя ждать. Они признали, что некоторые вопросы действительно проблематичны, снизили первоначальные оценки процента неверных ответов с 29% до порядка 18% при проведении собственного независимого повторного анализа с привлечением трех экспертов, что также подтверждает глубину и серьезность проблемы.
Кроме того, объявлено о запуске постоянного процесса ревизий и обновлений, который призван повысить качество студентов и итоговую достоверность экзамена в долгосрочной перспективе. Это демонстрирует важность прозрачности и гибкости в разработке benchmark-экзаменов, особенно в условиях стремительного роста возможностей искусственного интеллекта и научных знаний. Возникает логичный вопрос — что же делать с такими сложнымиevalами, где наука и передовые знания идут по тонкой грани интерпретаций, не всегда однозначных? Ведь научный «фронтир» — это место, где многое еще изучается, где часто существует не одна, а несколько альтернативных точек зрения. Попытка сформулировать однозначные и универсально верные вопросы может быть просто невозможной задачей. Тем не менее, от подобных benchmark-экзаменов и ожиданий, связанных с ними, не стоит полностью отказываться.
Они служат своеобразным маяком, который указывает направления для улучшений и помогает выявить слабые места в обучении и тестировании искусственного интеллекта. В дополнение к этому, FutureHouse предложила собственный улучшенный набор, который получил название HLE Bio/Chem Gold — выборку вопросов, проверенных и валидированных и искусственным интеллектом, и профильными экспертами, которые могут служить более надежным эталоном для оценки моделей в биологии и химии. Именно на таких комплексных и сбалансированных базах должна строиться новая эпоха тестов. Таким образом, опыт Humanity’s Last Exam — это важный урок для всего научного и AI-сообщества. Создание объективных, точных и одновременно сложных тестов мирового уровня — это не просто вызов.
Это непрерывный и ресурсозатратный процесс, требующий сотрудничества экспертов, прозрачных методологий, ответственного отношения к проверке данных и постоянной работы над обновлениями. Отказ от простых «ловушек» и чрезмерно искусственных вопросов в пользу реалистичных, научно обоснованных сценариев будет способствовать более здоровому развитию области и лучше подготовит технологии к реальным вызовам науки и техники нового века. Будущее подобных экзаменов за «живыми» и динамичными платформами, которые могут адаптироваться к меняющимся знаниям и учитывать нюансы, что позволит ИИ и людям работать вместе в сфере высокотехнологичных, сложных задач, оставаясь уверенными в корректности и полезности оцениваемой информации.